MLflow ist eine Machine Learning Plattform Komponente und begleitet den kompletten Machine Learning Prozess eines Data Science Projektes. Ziel ist die Dokumentation, Reproduzierbarkeit und das Deployment zu vereinfachen. Das Silicon Valley Startup databricks hat MLflow als Open Source Projekt hervorgerufen und entwickelt sehr aktiv an diesem Projekt.
- Hintergrund
- Probleme in Machine Learning Phasen
- MLFlow Funktionen
- MLflow installieren
- Zusammenfassung
Hintergrund
In diesem Artikel gehe ich auf die wichtigen Punkte des Projektes ein und beschreibe im Detail die 3 grundlegenden Funktionen:
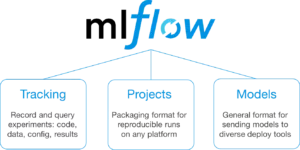
- Tracking: Dokumentation aller getesteten Model Parameter und wie diese Test- oder Validierungsergebnisse beeinflussen.
- Projekte: Ein konsistenter, standardisierter Weg wie man Experimente und Data Science Code in anderen Projekten nutzen kann.
- Models: Vereinfachte Art und Weise wie Modelle über mehrere Plattformen hinweg den Weg in die Produktion finden.
Wir beschäftigen uns mit dem Thema MLflow auch in unserem neusten Youtube Video. Hier erklären wir genauer, was MLflow ist, welche Funktionen es hat und gehen auf die Vorteile des ML-Trackings ein.
Doch zunächst möchte ich kurz auf die Probleme in Machine Learning Projekten eingehen, um so ein besseres Verständnis für den Nutzen von MLflow zu schaffen.
Probleme in Machine Learning Phasen
Die Komplexität bei der Entwicklung eines Machine Learning (ML) Models kann sehr hoch sein. Viele Herausforderungen sind im kompletten Prozess, von Entwicklung bis hin zur produktiven Nutzung, zu lösen. Folgende Herausforderungen ergeben sich:
- Eine unüberschaubare Zahl von Tools und APIs. Auf dem Markt gibt es hunderte einzelne Tools, die speziell für eine Phase des Entwicklungsprozesses gedacht sind. Dahingehend sollen unterschiedliche Algorithmen oder deren Implementierungen getestet werden, was dazu führt, dass viele unterschiedliche ML Libraries integriert werden müssen.
- Dokumentation der Versuche ist umständlich. Durch die vielen Parameter der ML Algorithmen ist es schwierig einzelne Ergebnisse festzuhalten.
- Reproduktion der Ergebnisse ist schwierig. Um die Ergebnisse zu reproduzieren müssen alle Parameter gespeichert sowie das ML Model gleichermaßen wieder ausgeführt werden. In der Praxis scheitert es oft daran – wer weiß schon nach 20 unterschiedlichen Parametern welcher wie funktioniert hat?
- Einsatz in Produktion ist komplex. Neben der ganzen Modellerstellung gilt es zudem, dass die Modelle wirklich in Produktion gebracht werden. Oft ist dies nicht ganz einfach, wenn z.B. ein Modell in einer App oder Website implementiert ist.
Die Herausforderungen in Big Data Analytics Projekten, wo Machine Learning zum Einsatz kommt, zeigen uns die Komplexität der Vorhaben auf. Deshalb haben sich in den letzten Jahren führende Unternehmen vor allem mit internen Machine Learning Plattformen auseinandergesetzt. In diesem Artikel habe ich das Thema ML Plattformen und Feature Store bereits beschrieben.
Als Beispiel seien hier die Projekte von Facebook, Google und Uber – FBLearner Flow, TFX und Ubers Michelangelo zu nennen. Diese Projekte setzen sich mit dem kompletten Prozess von Datenvorverarbeitung, über Modelltraining bis hin zum Model Deployment auseinander.
Databricks hat jetzt mit dem Projekt MLflow: an open source machine learning platform eine Open Source Plattform herausgebracht, die diese Probleme minimieren soll. Diese befindet sich zwar Momentan noch in der Alpha Phase, aber bewährt sich schon recht gut.

MLflow Funktionen
Moment bietet MLflow in der Alpha drei grundlegende Funktionen:
MLflow Tracking
Die Tracking Komponente ist hauptsächlich ein API für die Speicherung von Modellparametern, Code Versionen und Output Formaten von ML Modellen. Entwickler können MLflow in vielen Umgebungen nutzen (beispielsweise in einem einzelnen Skript oder in einem Notebook, wie IPython oder databricks) um die einzelnen Werte der Modelldurchläufe lokal oder auf einem Server zu speichern. So lassen sich die Ergebnisse mit anderen Entwicklern innerhalb des Teams teilen. Hierfür steht eine webbasierte Oberfläche zur Verfügung.
Folgende Abbildung zeigt die Tracking Funktion von MLflow:
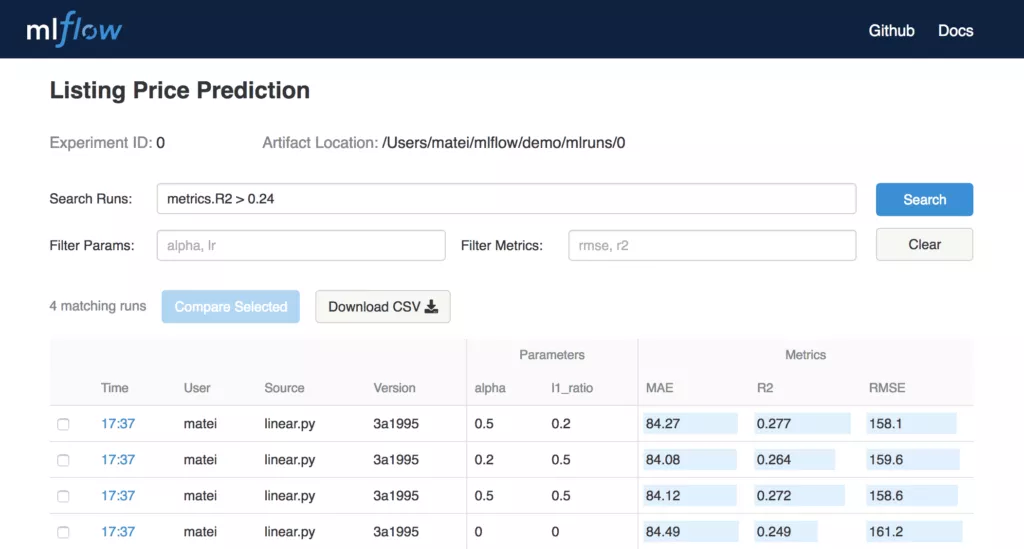
Die Abbildung zeigt schön die Funktionalität von MLflow – man erhält einen super Überblick über Durchläufe, Nutzer, Versionierung, Parameter und natürlich Modellgütekennzahlen wie bspw. mean absolute error (MAE), R2 oder RMSE. Natürlich sind viele verschiedene Kennzahlen je nach Modell und Daten abrufbar.
Ich finde besonders die Trackingfunktion total interessant für meine Projekte, denn damit habe ich schon einen Teil meiner Dokumentation automatisiert und muss es nicht aufwändig per Hand machen.
MLfLow Projekte
Die Projektkomponente von MLflow definiert einen Standardformat für Data Science Code, so dass dieser in anderen Projekten wiederverwendbar ist. Jedes Projekt ist wie ein Ordner mit Code oder ein Git Repository aufgebaut, welches Informationen über alle Abhängigkeiten enthält. Als Beispiel kannst du in einem Projekt ein conda.yaml für das Python Conda Environment definieren.
Wenn das Tracking API eingesetzt wird, merkt sich MLflow automatisch die zuletzt ausgeführte Version und die gespeicherten Parameter. Entwickler können effizient bestehende MLflow Projekte laden und mehrere MLfLow Projekt zu einem Workflow zusammenführen.
MLflow Models
Diese Komponente sorgt dafür, dass das Machine Learning Projekt in einem Standardformat für die verschiedenen Tools und Umgebungen für die Produktion gepackt werden. So ist es einfach verschiedene Umgebungen mit Modellen zu versorgen und diese in Produktivumgebungen einzusetzen.
Natürlich ist bei einer Entwicklung von databricks, auch Apache Spark nicht weit davon entfernt. Dahingehend ist das ganze Projekt sehr nah an Apache Spark orientiert.
MLflow installieren
MLflow ist sehr leicht über pip zu installieren:
pip install mlflow
Viel mehr müsst ihr hier nicht machen. Wer mehr dazu erfahren möchte kann hier den quickstart guide von Databricks finden.
Zusammenfassung
MLflow ist ein sehr interessantes Projekt, wenn man in Data Science Projekten viele verschiedene Modelle entwickelt und der ganze Prozess dokumentiert werden soll. Natürlich gibt es kommerzielle Systeme, wo man eine grafische Oberfläche hat, aber oft sind diese Systeme besonders im Big Data Umfeld bis jetzt kaum einzusetzen. Daher denke ich, dass MLflow besonders in individuellen Entwicklungen und Plattformen seine Stärke hat.
Vor allem wenn man eine gute Architektur mit einem entsprechenden ML Feature Store (Feature Store Beispiel von Uber) hat, kommen die Komponenten von MLflow zur Geltung und steigern die Produtkivität in Data Science Projekten.