


Sie hören den Begriff Databricks immer öfter: in Ausschreibungen, auf Konferenzen, von Kollegen, die gerade eine neue Datenarchitektur evaluieren. Aber was steckt eigentlich dahinter, und ist das relevant für ein Unternehmen wie deins?
Wir begleiten als Databricks Silver Partner täglich Projekte bei mittelständischen Unternehmen, die genau diese Frage beantworten wollen. Dieser Artikel gibt Ihnen eine ehrliche Einordnung: Was Databricks ist, was es kann, für wen es sich lohnt und für wen (noch) nicht.
Steigen wir direkt ein!
Was ist Databricks?
Databricks ist eine cloudbasierte Data Intelligence Platform, die alle wesentlichen Aufgaben rund um Daten – Verarbeitung, Analyse, Machine Learning und KI – auf einer einzigen, offenen Plattform vereint.
Das klingt zunächst abstrakt, wird aber greifbar, wenn man schaut, womit Unternehmen typischerweise vor Databricks zu kämpfen hatten: Daten in isolierten Silos, ein Data Warehouse für SQL-Auswertungen, ein separates Tool für Machine Learning, ein weiteres für Datenpipelines – und ein Data-Team, das die meiste Zeit damit verbringt, Daten zwischen diesen Systemen hin- und herzuschieben statt echten Mehrwert zu schaffen. Databricks löst genau dieses Problem.
Die Plattform wurde 2013 von den Entwicklern von Apache Spark – dem meistgenutzten Open-Source-Framework für verteilte Datenverarbeitung – an der UC Berkeley gegründet. Heute ist Databricks mit einer Bewertung von 134 Milliarden US-Dollar (Stand Dezember 2025) und einem Jahresumsatz-Run-Rate von über 4,8 Milliarden US-Dollar (Wachstum >55% gegenüber Vorjahr) die führende Plattform in diesem Marktsegment.
Databricks kombiniert mehrere Open-Source-Lösungen miteinander: Apache Spark, Delta Lake und mlflow. Um zu verstehen, was Databricks ist, sehen wir uns die drei Lösungen genauer an.
Databricks vs. die häufigsten Verwechslungen
Databricks vs. Data Warehouse (z.B. Azure Synapse, Snowflake):
- Ein klassisches Data Warehouse speichert strukturierte, bereits aufbereitete Daten für SQL-Abfragen und BI-Reports.
- Databricks arbeitet direkt auf dem Rohdaten-See (Data Lake) – mit allen Datentypen, auch unstrukturierten – und kann gleichzeitig ML-Modelle trainieren und Echtzeit-Pipelines betreiben.
- Der Unterschied: Databricks ersetzt kein Data Warehouse, es macht das Data-Warehouse-Konzept moderner und breiter.
Databricks vs. Power BI:
- Power BI ist ein Visualisierungs- und Reporting-Tool – die letzte Meile zum Endnutzer.
- Databricks ist die Datenschicht darunter: Es bereitet die Daten so auf, dass Power BI sie schnell und zuverlässig abfragen kann.
- Beide Systeme arbeiten Hand in Hand. Databricks ersetzt Power BI nicht.
Databricks vs. Microsoft Fabric:
- Microsoft Fabric ist Microsofts integriertes Data- und Analytics-Ökosystem, eng verzahnt mit Power BI, Azure und Microsoft 365.
- Databricks ist plattformunabhängiger, läuft auf Azure, AWS und GCP und setzt stärker auf Open-Source-Standards.
- Für viele Mittelständler in der DACH-Region ist die Frage nicht „oder“, sondern „wann welches“ – dazu mehr im Abschnitt Für wen lohnt sich Databricks?.
Das Herzstück: Das Data Lakehouse
Um zu verstehen, wie Databricks funktioniert, muss man das Data Lakehouse-Konzept kennen – die Architektur, die Databricks populär gemacht hat.
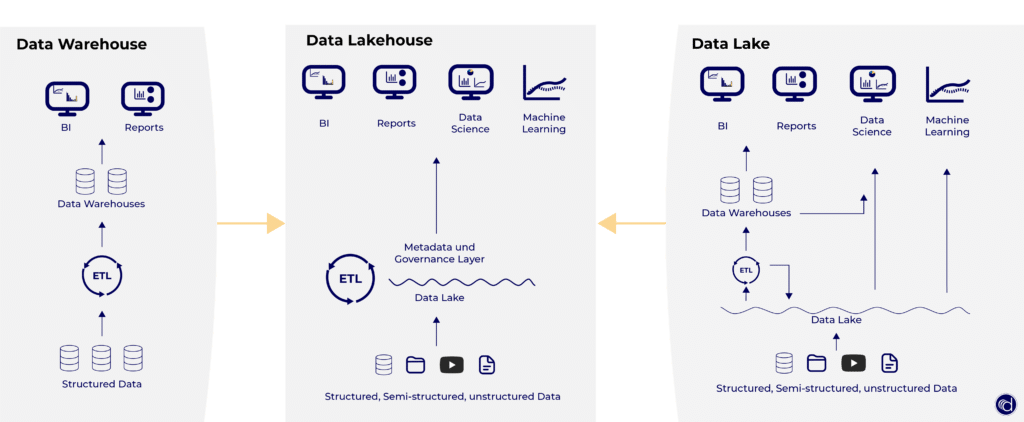
Klassische Architekturen zwangen Unternehmen in einen Kompromiss: entweder ein Data Warehouse (schnell für SQL, aber teuer, unflexibel und schlecht für ML) oder ein Data Lake (günstig, flexibel, aber ohne Datenqualitätssicherung oft zum „Data Swamp“ verkommen). Das Lakehouse kombiniert die Stärken beider Ansätze.
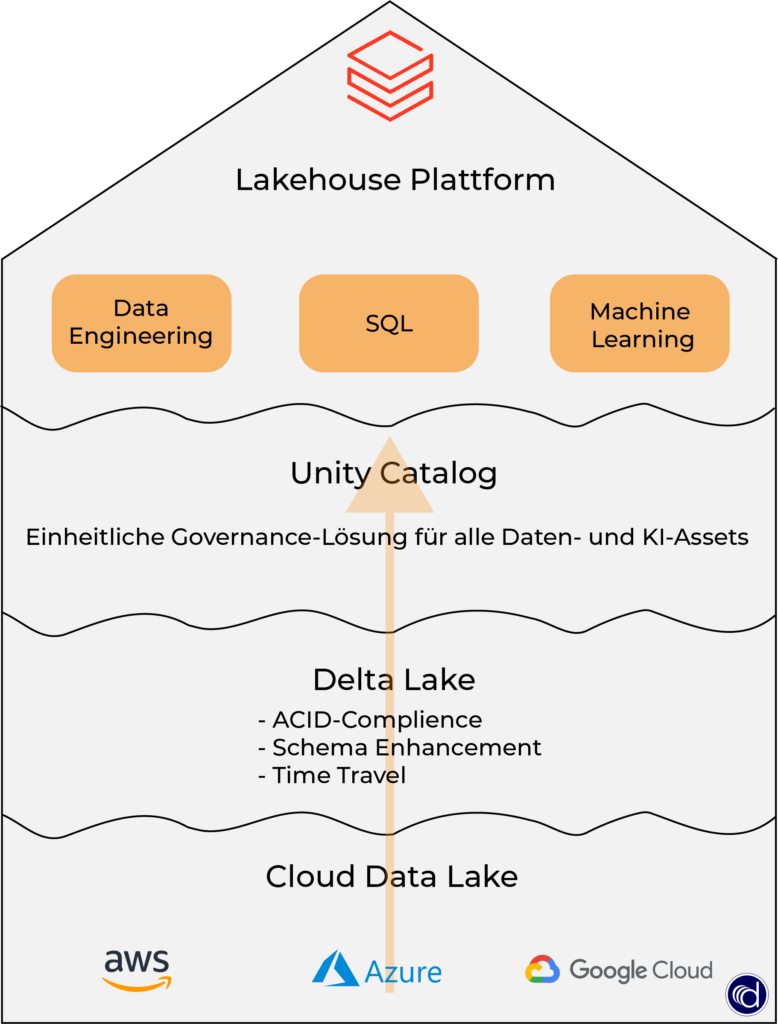
Die technische Basis des Databricks Lakehouse besteht aus drei Kerntechnologien:
| Komponente | Was es macht | Was das für Ihr Unternehmen bedeutet |
|---|---|---|
| Delta Lake | Fügt dem Data Lake ACID-Transaktionen, Datenqualitätssicherung und Time Travel (Datenversionierung) hinzu | Ihre Daten sind zuverlässig und auditierbar – kein Data Swamp mehr |
| Apache Spark | Verteilte Verarbeitungs-Engine für sehr große Datenmengen, parallel auf vielen Maschinen | Auch komplexe Transformationen und ML-Workloads laufen performant |
| Unity Catalog | Zentrale Governance-Schicht: Zugriffsrechte, Datenherkunft, Audit-Logs für alle Daten und KI-Assets | DSGVO-konforme Datenverwaltung aus einer Hand, auch bei wachsenden Teams |
Klassische Architekturen zwangen Unternehmen in einen Kompromiss: entweder ein Data Warehouse (schnell für SQL, aber teuer, unflexibel und schlecht für ML) oder ein Data Lake (günstig, flexibel, aber ohne Datenqualitätssicherung oft zum „Data Swamp“ verkommen). Das Lakehouse kombiniert die Stärken beider Ansätze.
Die Standard-Datenorganisation in Databricks-Projekten folgt dabei der sogenannten Medallion-Architektur: Rohdaten landen in der Bronze-Schicht (unverändertes Original), werden in der Silver-Schicht bereinigt und validiert, und in der Gold-Schicht zu anwendungsspezifischen Datenprodukten aggregiert – für Dashboards, ML-Training oder operative Prozesse.
Ihr Team kennt die Konzepte aber nicht den produktiven Alltag auf der Plattform?
Verstehen ist der erste Schritt – Anwenden der zweite.
Expertentipp von Laurenz Wuttke, CTO & Databricks MVP bei Datasolut:
In unseren Projekten ist der häufigste Fehler beim Einstieg in Databricks, direkt mit der Gold-Schicht anzufangen – also möglichst schnell ein Dashboard zu bauen. Die Bronze- und Silver-Schicht ist aber das eigentliche Fundament: Wer hier sauber arbeitet, hat später deutlich weniger Aufwand bei Datenqualitätsproblemen. Planen Sie für den Aufbau dieser Schichten mindestens 30–40% des initialen Projektaufwands ein.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Was kann Databricks konkret? Die vier Anwendungsbereiche
Databricks ist keine Insellösung für einen Zweck. Die Plattform deckt vier Hauptbereiche ab, die in klassischen Architekturen jeweils separate Tools erfordert hätten:
1. Data Engineering: Zuverlässige Datenpipelines ohne Wartungs-Overhead
Daten aus verschiedenen Quellen – ERP, CRM, IoT-Sensoren, APIs – werden mit Databricks in automatisierte Pipelines überführt, die täglich oder in Echtzeit laufen. Das Framework LakeFlow (früher Delta Live Tables) ermöglicht es, diese Pipelines deklarativ zu definieren: Datenqualitätsregeln, Abhängigkeiten und Fehlerbehandlung werden direkt im Code beschrieben – Databricks übernimmt das Monitoring und den Restart bei Fehlern.
Für den Mittelstand bedeutet das: Ein kleines Data-Engineering-Team von 2–3 Personen kann eine produktive Pipeline-Landschaft betreiben, die früher 8–10 Personen erfordert hätte.
2. SQL & Analytics: Alle Daten, für alle Teams zugänglich
Databricks SQL ermöglicht es, direkt auf den Lakehouse-Daten mit Standard-SQL zu arbeiten – mit einer Performance, die klassischen Data Warehouses auf Augenhöhe begegnet oder sie übertrifft. Business-Teams können über vertraute BI-Tools wie Power BI oder Tableau auf aktuelle, bereinigte Daten zugreifen, ohne auf das Data-Engineering-Team warten zu müssen.
3. Machine Learning & KI: Vom Experiment zur produktiven Lösung
Die enge Integration von MLflow (dem meistgenutzten Open-Source-Standard für ML-Lifecycle-Management) macht Databricks zur bevorzugten Plattform, um ML-Modelle von der Entwicklung bis in die Produktion zu bringen. Typische Anwendungsfälle im Mittelstand: Churn-Vorhersage, Nachfrageplanung, Qualitätskontrolle auf Basis von Sensor-/Maschinendaten, Dokumentenklassifikation.
4. Business Intelligence: Direkte Insights ohne SQL-Kenntnisse
Mit Genie und der Business-User-Oberfläche Databricks One können auch Mitarbeiter ohne technische Kenntnisse Fragen an ihre Unternehmensdaten in natürlicher Sprache stellen. Dashboards, Alerts und Ad-hoc-Analysen – ohne Ticket ans Data-Team. Zugriffsrechte werden dabei zentral über den Unity Catalog gesteuert.

Für wen lohnt sich Databricks – und für wen nicht?
Das ist die Frage, die in keinem anderen Vergleichsartikel beantwortet wird. Hier unsere ehrliche Einschätzung aus der Projektpraxis.
Databricks lohnt sich, wenn:
- Ihr Unternehmen täglich mehr als 50 GB Rohdaten aus verschiedenen Quellen verarbeitet
- Sie mehr als drei isolierte Datenquellen haben, die zusammengeführt werden müssen
- Sie ein Data-Team von mindestens 2–3 Personen aufbauen oder bereits haben
- ML/KI-Anwendungsfälle über POC-Status hinaus produktiv werden sollen
- Datenqualität und Governance (z.B. für DSGVO oder interne Compliance) eine wachsende Rolle spielen
- Sie in der Microsoft/Azure-Welt sind (Azure Databricks ist ein First-Party-Azure-Service, tief integriert mit Entra ID, ADLS Gen2, Power BI)
Databricks ist (noch) nicht die richtige Wahl, wenn:
- Ihr Datenvolumen überschaubar ist und ein gut konfiguriertes Data Warehouse ausreicht
- Sie keine technischen Kapazitäten haben und noch kein Data-Team aufgebaut haben
- Sie ausschließlich strukturierte Daten in klassischen BI-Reports nutzen
- On-Premise-Betrieb eine Pflichtanforderung ist – Databricks ist eine reine Cloud-Plattform
Typische Einstiegsszenarien im Mittelstand
Fertigungsunternehmen mit ERP-Daten: Ein Hidden Champion mit SAP-Backbone und Maschinen-Sensordaten will Qualitätsabweichungen früher erkennen. Databricks verbindet ERP-Transaktionsdaten mit IoT-Sensordaten in einer einheitlichen Pipeline – und macht ML-gestützte Qualitätsprognosen möglich.
Seit Februar 2025 erleichtert die SAP Business Data Cloud-Partnerschaft die native Integration von SAP-Daten erheblich.
Mittelständischer Einzelhändler: Daten aus verschiedenen Filialen, einem Online-Shop und einem Warenwirtschaftssystem werden täglich in Silos verwaltet. Databricks vereinheitlicht die Datenbasis – Grundlage für Bestandsoptimierung, Churn-Prognosen und Aktionsplanung.
Versicherungsvertrieb: Große Mengen an Kunden- und Vertragsdaten, Compliance-Anforderungen, wachsende Anforderungen an KI-gestützte Beratungsunterstützung. Databricks liefert die DSGVO-konforme Grundlage: Kundendaten liegen im eigenen Azure-Account, nicht bei Databricks selbst.
Databricks-Beratung für Ihr Unternehmen
Wir begleiten Mittelständler auf dem Weg von den ersten Datenprojekten bis zur skalierten Datenplattform – mit dem DSX Lakehouse Framework aus über 30 abgeschlossenen Projekten. Kein Learning by Doing auf Kundenseite.
Mit Databricks starten: So geht der Einstieg
Ein Databricks-Projekt startet selten mit einer Big-Bang-Migration. Was wir in der Praxis als sinnvollsten Einstiegspfad erleben:
Schritt 1: Klarheit über Ausgangslage und realistischen Einführungspfad
Bevor eine einzige Zeile Code geschrieben wird, braucht es eine ehrliche Bestandsaufnahme: Welche Datenquellen existieren, in welcher Qualität, mit welchen Zugriffsrechten? Welche Use Cases sollen in 6 Monaten funktionieren – und welche in 2 Jahren? In unserem kostenlosen Data Infrastructure Assessment klären wir diese Fragen strukturiert und leiten daraus eine priorisierte Roadmap ab.
Schritt 2: Fundament legen – Bronze, Silver, erste Gold-Tabellen
Der erste produktive Meilenstein ist eine laufende Datenpipeline vom Quellsystem bis zu einer bereinigten Silver-Tabelle. Das klingt unspektakulär, ist aber der kritischste Schritt: Hier entscheidet sich, ob das Lakehouse später als belastbare Grundlage für KI und Analytics dient oder als Data Swamp endet. Unser DSX Lakehouse Framework gibt dabei bewährte Architekturmuster und Governance-Standards vor – damit nicht jedes Projekt von vorne anfängt.
Schritt 3: Erste Anwendungsfälle produktiv schalten
Sobald die Datenbasis steht, können die ersten Use Cases in Produktion gehen: ein ML-Modell, ein neues Dashboard, eine automatisierte Reporting-Pipeline. Hier zahlt sich die Entscheidung für eine einheitliche Plattform aus: Data Engineers, Data Scientists und Business-Teams arbeiten auf denselben Daten – ohne Übergabe-Reibungsverluste.
Databricks 2025/2026: Lakebase, Agent Bricks und die KI-Richtung
Databricks entwickelt sich schnell – und zwei Ankündigungen vom Data + AI Summit 2025 sind für mittelständische Unternehmen besonders relevant:
Lakebase: Seit dem Summit allgemein verfügbar – ein managed, serverloser Postgres-kompatibler Datenbankdienst, der direkt auf der Lakehouse-Infrastruktur läuft. Was das bedeutet: Transaktionale Workloads (OLTP) und analytische Workloads (OLAP) laufen erstmals auf denselben Daten, ohne Replikation oder Synchronisierung. Für KI-Agenten, die in Echtzeit auf Unternehmensdaten zugreifen müssen, ist das ein erheblicher Vorteil. Lakebase ist auf Azure in westeurope und northeurope verfügbar – relevant für DSGVO-konforme EU-Deployments.
Agent Bricks: Ein Framework, das den Aufbau und das Deployment von Production-Grade AI Agents auf Basis eigener Unternehmensdaten drastisch beschleunigt. Statt monatelanger Eigenentwicklung ermöglicht Agent Bricks die Erstellung domänenspezifischer Agents in Stunden – mit integrierter Evaluierung und automatisierter Optimierung.
Die Richtung ist klar: Databricks entwickelt sich von der reinen Datenplattform zur vollständigen KI-Infrastruktur. Für Unternehmen, die heute eine belastbare Datenbasis aufbauen, ist das eine strategische Weiche – wer jetzt in die richtige Architektur investiert, kann morgen diese KI-Fähigkeiten ohne Restrukturierung nutzen.
Expertentipp von Laurenz:
Viele unserer Kunden fragen uns: „Müssen wir jetzt Lakebase und Agent Bricks sofort einplanen?“ Unsere Antwort: Nein. Aber die Plattformwahl sollte diese Richtung nicht ausschließen. Wer heute ein sauberes Lakehouse auf Databricks aufbaut, hat die Optionalität. Wer in ein proprietary System investiert, muss später oft neu entscheiden.Databricks Beratung für Ihr Unternehmen
Wir begleiten Mittelständler auf dem Weg von den ersten Datenprojekten bis zur skalierten Datenplattform – mit dem DSX Lakehouse Framework aus über 30 abgeschlossenen Projekten. Kein Learning by Doing auf Kundenseite.
Fazit
Databricks erfüllt als Cloud-basierte Plattform alle Anforderungen an das Datenmanagement. Sie arbeiten interaktiv mit Ihrem gesamten Datenteam zusammen.
Die Plattform vereinheitlicht Datensysteme, reduziert Kosten und skaliert für große Datenmengen. Sie ergänzt Ihre bestehende Cloud (AWS, Microsoft Azure oder Google Cloud) und verarbeitet Daten zuverlässig mit der Lakehouse-Plattform
Sie möchten mehr erfahren oder sind an Cloud-basierten Lösungen für Ihre Daten interessiert? Dann kontaktieren Sie uns gerne!
FAQ – Die wichtigsten Fragen schnell beantwortet
Databricks ist eine Cloud-basierte Datenplattform, die es Nutzern ermöglicht, eine Multi-Cloud-Lakehouse-Struktur aufzubauen. Die Plattform unterstützt Kunden bei der Speicherung, Bereinigung und Visualisierung großer Datenmengen aus unterschiedlichen Quellen. Kunden können verschiedene Aufgaben im Datenmanagementprozess von einer einzigen Plattform aus durchführen und interaktiv zusammenarbeiten.
Auf die Nutzungsintensität kommt es an! Das Kostenmodell basiert auf zwei Abrechnungsposten: Zeit und benötigte Rechenleistung (Größe und Anzahl). Die Abrechnung erfolgt in sogenannten DBUs (Databricks Units). Daraus ergibt sich folgende Gleichung
Kosten = (Anzahl Server * DBU)*h/Nutzung + (Anzahl Server * Instanzpreis)*h/Nutzung
Databricks basiert auf Apache Spark, bietet aber eine vereinfachte Handhabung mit Spark Clustern. Gleichzeitig bietet Databricks mit Delta Lake die Nutzung einer Lakehouse-Umgebung und vereint damit die Vorteile von Data Lake und Data Warehouse. Die Open Source Plattform ermöglicht zudem die Nutzung verschiedener Cloud Server und bietet Lösungen für SQL, Data Engineering und Machine Learning.
Azure Databricks ist eine einheitliche, auf Open-Source basierende Cloud-Plattform für Unternehmen, mit der Daten, Analysen und KI-/ BI-Lösungen erstellt, bereitgestellt, gemeinsam genutzt und dabei sicher verwaltet werden können. Die Plattform integriert sich in Ihr Cloud-Konto (AWS, Google und Azure) und übernimmt das Management der Cloud-Infrastruktur. Mit Azure Databricks können Sie unterschiedlichste Datenquellen anbinden (DWH, MSSQL, Google Analytics, Salesforce, SAP), Daten verarbeiten, analysieren, visualisieren und KI-Modelle entwickeln. Durch den Unity Catalog bietet Sie Enterprise-Grade Sicherheit und Governance. Außerdem ermöglicht Azure Databricks die Nutzung und Integration von Open-Source-Technologien wie Apache Spark und Delta Lake sowie proprietären Tools für optimierte Leistung und Zusammenarbeit.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte











