


Machine Learning (deutsch: maschinelles Lernen) ist eine Anwendung der Künstlichen Intelligenz (KI). Computersysteme lernen automatisch Muster und Zusammenhänge aus Daten und verbessern sich selbst, ohne explizit programmiert zu werden. Machine Learning unterstützt uns seit vielen Jahren erfolgreich in Wirtschaft, Forschung und Entwicklung.
In diesem Artikel erklären wir Ihnen die Grundlagen des maschinellen Lernens und zeigen, welche verschiedenen Arten und Algorithmen es gibt. Außerdem erfahren Sie, wofür Machine Learning eingesetzt wird und welche Daten dafür benötigt werden.
Machine Learning auf einen Blick
- Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz.
- Systeme lernen selbstständig Muster und Zusammenhänge aus großen Datenmengen.
- Maschinelles Lernen wird in drei Methoden unterteilt: Supervised Learning, Unsupervised Learning und Reinforcement Learning.
- Deep Learning ist eine besondere Form des maschinellen Lernens
Machine Learning Definition
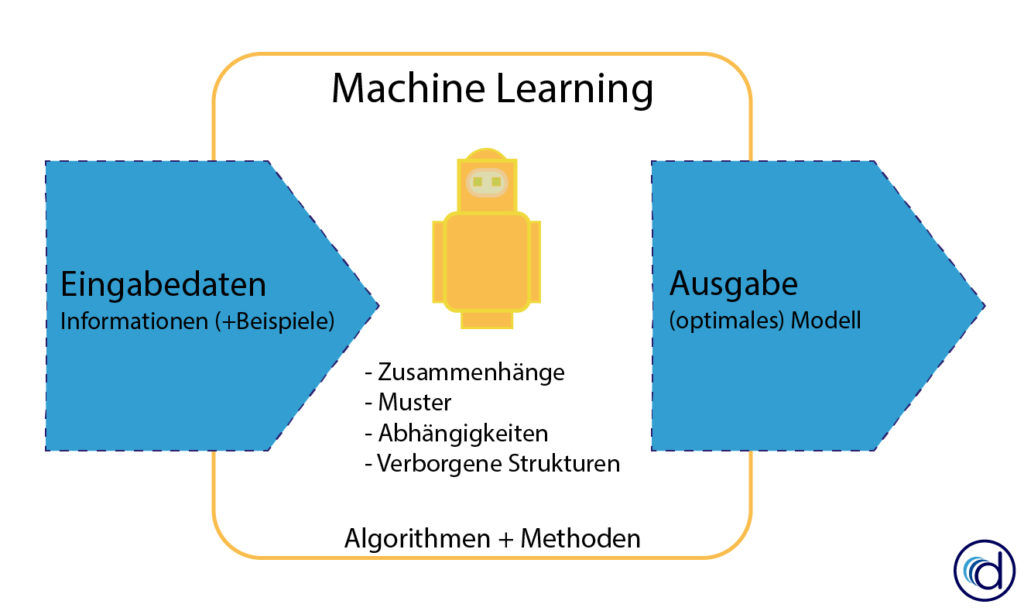
Maschinelles Lernen (Machine Learning, ML) ist ein Teilbereich der Künstlichen Intelligenz, der Systeme in die Lage versetzt, automatisch aus Erfahrungen (Daten) zu lernen und sich zu verbessern, ohne explizit programmiert zu sein.
ML kann automatisiert Wissen generieren, Algorithmen trainieren, Zusammenhänge identifizieren und unbekannte Muster erkennen. Diese identifizierten Muster und Beziehungen können auf einen neuen, unbekannten Datensatz angewendet werden, um Vorhersagen zu treffen und Prozesse zu optimieren.
Anders als bei der traditionellen Softwareentwicklung, liegt bei Machine Learning der Schwerpunkt auf dem selbstständigen Lernen aus Daten. Das bedeutet, dass der Algorithmus aus den Daten lernt und seinen Programmcode alleine erstellt.
Maschinelles Lernen kann folgende Aufgaben erledigen:
- Vorhersage von Werten auf Basis der analysierten Daten treffen (bspw. Stromverbrauch oder Umsatzforecast),
- Berechnung von Wahrscheinlichkeiten für bestimmte Ereignisse (bpsw. Kaufwahrscheinlichkeit oder Kündigungswahrscheinlichkeit),
- Erkennen von Gruppen und Clustern in einem Datensatz,
- Erkennen von Zusammenhängen in Sequenzen,
- Reduktion von Dimensionen ohne großen Informationsverlust
- Optimierung von Geschäftsprozessen.
Damit maschinelles Lernen funktioniert und die Software die Entscheidung treffen kann, muss ein Mensch den Algorithmus trainieren. Durch das Bereitstellen von Trainings- und Beispieldaten, kann der Algorithmus Muster und Zusammenhänge erkennen und somit aus den Daten lernen. Diesen Prozess nennt man auch Modelltraining.
Maschinelles Lernen wird häufig mit den Begriffen Data Mining und predictive Analytics in Verbindung gebracht. Letztlich nutzen Data Mining und predictive Analytics die Verfahren des maschinellen Lernens.
Sehen wir uns nun an. wie Machine Learning funktioniert.
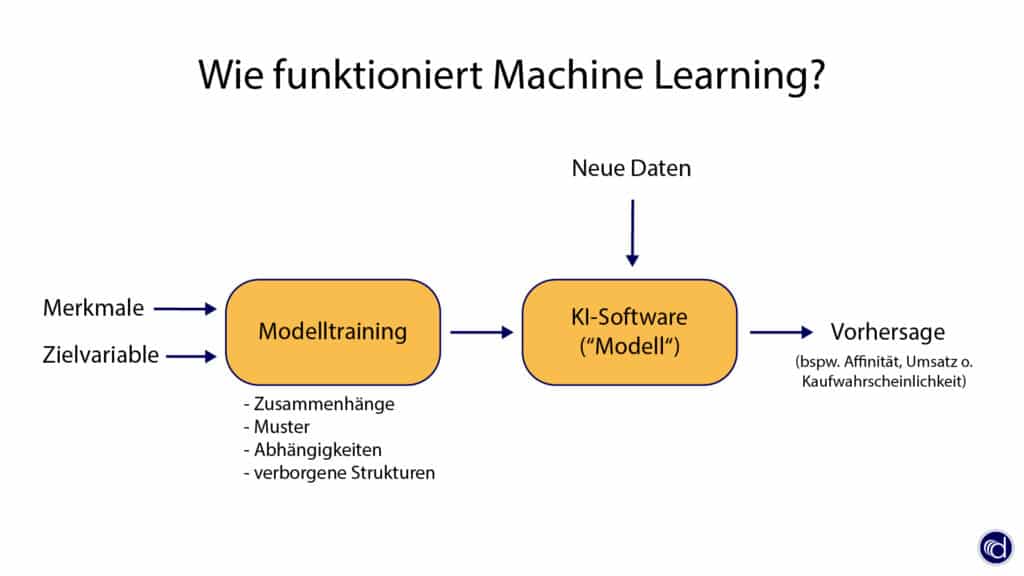
Wie funktioniert Machine Learning?
Damit Machine Learning funktioniert und ein Muster lernen kann, muss es von einem Menschen trainiert werden. Dieser Lernprozess beginnt mit einem vorbereiteten Datensatz (Trainingsdatensatz), der von einem Machine Learning Algorithmus nach Mustern und Zusammenhängen durchsucht wird.
Nach einem erfolgreich abgeschlossenen Lernprozess wird das trainierte Modell dazu genutzt, unbekannte Daten zu bewerten. Auf Grundlage der ML-Ergebnisse können dann optimiert Entscheidungen getroffen werden. Das Hauptziel ist, es ohne menschliche Eingriffe automatisch zu lernen und die Aktionen entsprechend anzupassen.
Die Entwicklung eines Modells ist ein interaktiver Prozess, der oft mehrmals durchlaufen wird, bis das Ergebnis eine bestimmte Qualität erreicht hat. In der Praxis kommt es daher immer wieder zu Entwicklungsschleifen, in denen ein Mensch die Ergebnisse des maschinellen Lernalgorithmus bewerten muss. Dieser Lernprozess basiert auf der jeweiligen Algorithmus-Art.
Schauen wir uns die jeweiligen Arten des Machine Learnings an.
Arten von Machine Learning Algorithmen
Wir unterscheiden bei den Algorithmen des Machine Learnings zwischen folgenden:
- überwachtes Lernen (Supervised Learning)
- unüberwachtes Lernen (Unsupervised Learning)
- teilüberwachtes Lernen (Semi-Supervised Learning)
- verstärkendes Lernen (Reinforcement Learning)
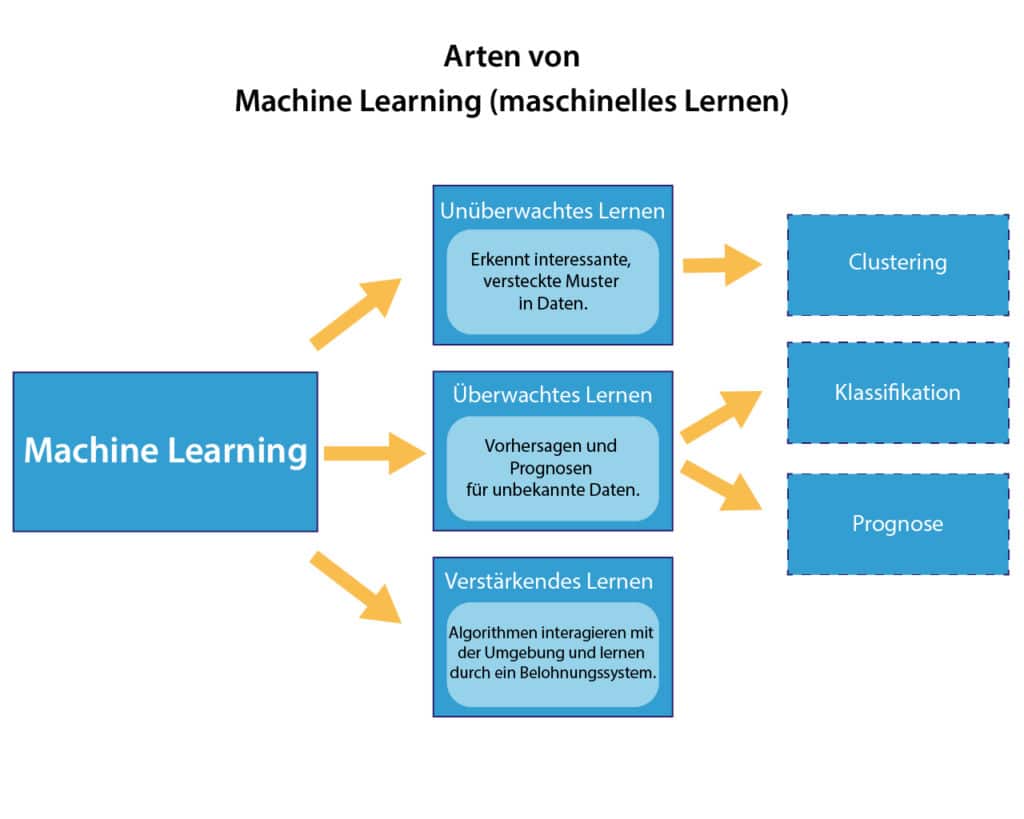 Arten von Machine Learning Algorithmen.
Arten von Machine Learning Algorithmen.
Überwachtes Lernen
Überwachtes maschinelles Lernen (engl.: Supervised Machine Learning) nutzt bekannte Daten, um Muster und Zusammenhänge zu erkennen. Der Algorithmus lernt die Muster anhand eines Trainingsdatensatzes (Beispieldaten). Beim überwachten Lernen wird immer in Bezug auf eine Zielvariable gelernt und der Algorithmus versucht, diese richtig vorherzusagen. Die Zielvariable kann eine Klasse (z.B. Kündigung ja/nein) oder ein numerischer Wert (z.B. Umsatz für den nächsten Monat) sein.
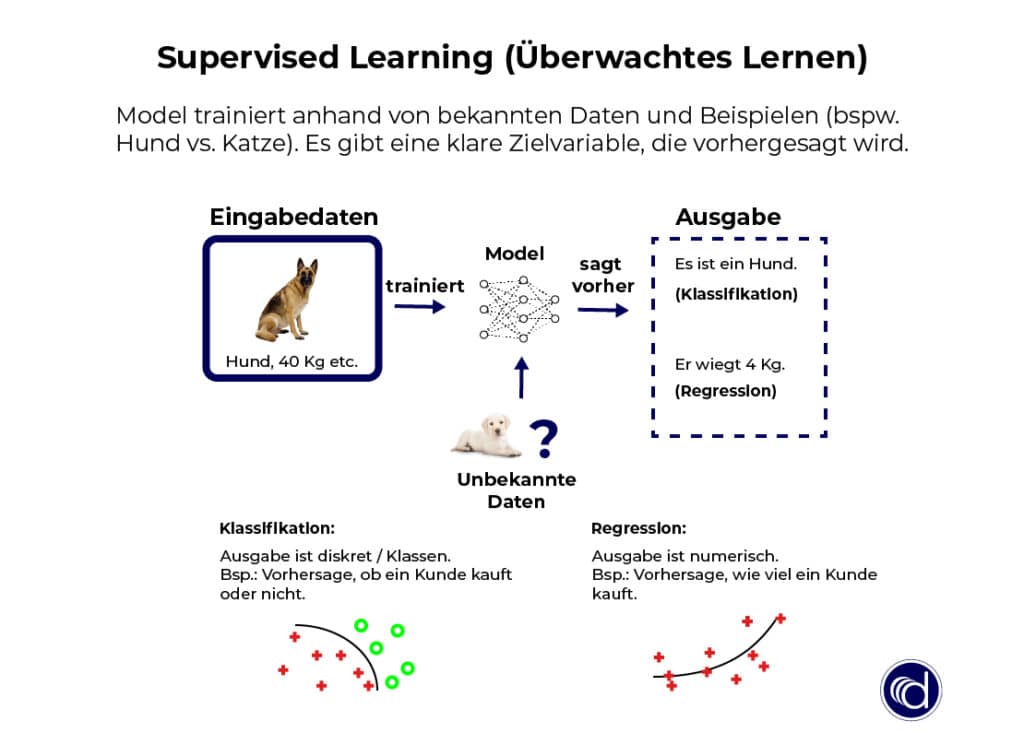
Anhand eines erfolgreichen Lernprozesses werden verlässliche Vorhersagen für zukünftige oder unbekannte Daten getroffen. Im Marketing wird überwachtes Lernen häufig für die Klassifikation von Kundendaten eingesetzt.
Beispiele aus der Praxis von überwachten Lernverfahren sind:
- Vorhersage von Stromverbrauch für einen Zeitraum X
- Risikobewertung von Investitionen
- Berechnung von Ausfallwahrscheinlichkeiten im Maschinenpark
- Prognose von Kundenwert für die nächsten 12 Monate
Unüberwachtes maschinelles Lernen
Beim unüberwachten maschinellen Lernen (Unsupervised Machine Learning) erhält der Algorithmus keine Beispieldaten, sondern Daten, aus denen der Algorithmus selbstständig interessante, verborgene Gruppen und Muster erkennen soll.
Bei dem Unsupervised Machine Learning geht es nicht darum, Vorhersagen für eine bekannte Zielvariable zu treffen, wie es beim Supervised Machine Learning der Fall ist. Stattdessen werden Muster und Strukturen in den Daten entdeckt, ohne dass es eine vorgegebene Antwort gibt. Machine Learning Algorithmen im Bereich des Unsupervised Learning werden genutzt, um Daten zu clustern oder zu segmentieren. Die Bewertung der Ergebnisse erfolgt durch den Data Scientist anhand „weicher“ Faktoren, um zu beurteilen, wie gut die Ergebnisse zur Geschäftsanforderung passen. Solche Machine Learning Verfahren sind besonders nützlich, wenn man versteckte Muster in großen Datenmengen aufdecken möchte.

Beispiele für unüberwachtes maschinelles Lernen sind Dimensions Reduktion und Clusteringverfahren.
Die Verfahren werden eingesetzt für:
- Visualisierung von großen Datenmengen,
- Clusteranalysen,
- Extraktion von Regeln
- und Erstellung von ML-Features.
Ein Anwendungsbeispiel finden Sie hier: Beispiel in Python – wie man eine Kundensegmentierung mit einem K-Means-Clustering-Algorithmus erstellt.
Teilüberwachtes Lernen
Teilüberwachtes Lernen (Semi-supervised Machine Learning) nutzt sowohl Beispieldaten mit konkreten Zielvariablen, als auch unbekannte Daten und ist somit eine Mischung aus überwachtem und unüberwachtem Lernen. Die Einsatzgebiete von teilüberwachtem Lernen sind im Grunde die gleichen wie bei dem überwachten Lernen.
Der Unterschied besteht darin, dass für den Lernprozess nur eine kleine Datenmenge mit einer bekannten Zielvariablen verwendet wird und eine große Datenmenge, für die diese Zielvariable noch nicht vorliegt. Dies hat den Vorteil, dass bereits mit einer geringeren Menge bekannter Daten trainiert werden kann. Die Beschaffung von bekannten Beispieldaten ist oft sehr aufwendig und kostenintensiv, da diese Daten häufig durch Menschen in manuellen Prozessen erstellt werden müssen (z.B. manuelle Beschriftung von Bildern).
Machine Learning Verfahren wie Semi-Supervised Learning werden häufig in der Bild- oder Objekterkennung verwendet. Dabei erstellt man zunächst einen kleinen, gelabelten Datensatz, oft von Menschen. Danach wird ein künstliches neuronales Netz zur Klassifikation trainiert und auf die restlichen Daten angewendet. So können die unbekannten Daten schneller und effizienter korrekt gelabelt werden.
Verstärkendes Lernen
Verstärkendes Lernen (Reinforcement Learning) oder auch bestärkendes Lernen ist eine besondere Form des maschinellen Lernens. Diese Algorithmen interagieren mit der Umgebung und werden durch eine Kostenfunktion oder ein Belohnungssystem bewertet, um so selbständig eine Strategie zur Lösung des Problems zu erlernen und die Belohnung zu maximieren.
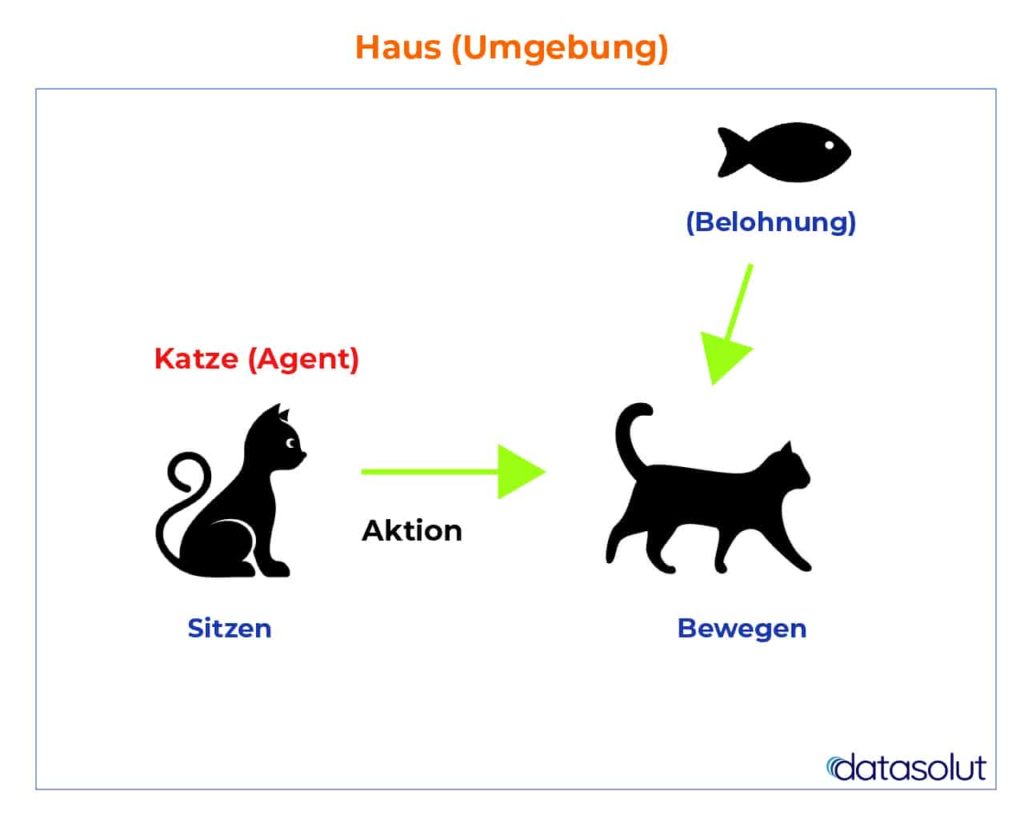
Beim Reinforcement Learning wird dem Algorithmus nicht vorgegeben, welche Aktion oder Handlung in welcher Situation die Richtige ist, sondern der Algorithmus erhält über die Kostenfunktion eine positive oder negative Rückmeldung (Feedback). Anhand dieser wird dann abgeschätzt, welche Aktion zu welchem Zeitpunkt die richtige ist. Auf diese Weise lernt das System „bestärkend“, die Belohnungsfunktion durch Lob oder Bestrafung zu maximieren.
Der entscheidende Unterschied zwischen überwachtem und unüberwachtem Lernen ist, dass bestärkendes Lernen keine vorherigen Beispieldaten benötigt. Der Algorithmus kann hier seine eigene Strategie in vielen iterativen Schritten in einer Simulationsumgebung entwickeln.
Im folgenden Video von Google DeepMind wird dies deutlich: Hier lernt die KI selbstständig zu laufen.
Wenn die KI eigenständig lernen kann, dann ist kein menschliches Vorwissen mehr nötig, um komplexe Probleme zu erlernen. Reinforcement Learning ist die große Hoffnung vieler KI-Forscher für die Lösung komplexer Problemstellungen, wie bspw. autonomes Fahren, autonome Robotik und der Entwicklung einer generellen Künstlichen Intelligenz.
Machine Learning Anwendungsgebiete
In den letzten zwei Jahrzehnten hat der technologische Fortschritt das maschinelle Lernen zu einem zentralen Bestandteil von Technologie und Wirtschaft gemacht.
Im Folgenden nennen wir einige Beispiele für Anwendungsbereiche des maschinellen Lernens:
Machinelles Lernen im Customer Relationship Management
Im Customer Relationship Management (CRM) findet maschinelles Lernen ein breites Anwendungsgebiet, um die Effizienz und Effektivität im CRM zu verbessern und natürlich den Kundenwert zu steigern. Da im CRM traditionell viele Kundendaten zur Verfügung stehen, sind hier die Optimierungspotentiale entlang des kompletten Kundenlebenszyklus enorm:
- Durch Customer Lifetime Value Prognosemodellen zukünftige Profitabilität oder Cross- und Up-Selling Potenziale vorhersagen
- Mit Next Best Offer Produktaffinitäten berechnen
- Kundensegmentierung für personalisiertes Marketing vornehmen
- Durch Churn Prediction-Modelle bevorstehende Abwanderungen vorhersagen
Personalisierung im Marketing
Ein wichtiges Anwendungsgebiet des maschinellen Lernens im Marketing ist die Personalisierung. Maschinelles Lernen kann die Präferenzen und das Verhalten von Kunden lernen und mit denen anderer Kunden vergleichen – das Ergebnis sind individuelle Produkt- oder Handlungsempfehlungen für jeden Kunden zum richtigen Zeitpunkt.
- Produktempfehlungen Webshops: “Kunden, die dieses Produkt kaufen, kauften auch…”
- Personalisierte Internetseiten bei Streaminganbietern und Webshops
- Kundensegmentierung auf Grundlage verschiedener Kennzahlen (CLV, RFM) führt zu personalisierten Marketingstrategien
Ein spannendes neues Beispiel ist der Drive-Through von McDonalds: Bei einigen Standorten werden Kameras mit Bilderkennung eingesetzt, um Fahrzeuge und damit Kunden wiederzuerkennen und ihnen bestimmte Produktvorschläge zu machen.
Wie Machine Learning im E-Commerce eingesetzt werden kann, können Sie hier lesen.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
(IT-)Security
Üblicherweise werden kritische IT-Systeme meist mit Hilfe von Security Information and Event Management (SIEM) abgesichert. Problematisch ist hierbei der hohe Aufwand und Personalbedarf, um auf potentiell sicherheitsrelevante Ereignisse reagieren zu können.
- Schwierigkeit: auf immer besser ausgeklügelten Methoden von Hackern mit kriminellen Absichten reagieren
- Lösung: Machine-Learning-Modelle zur Überwachung von IT-Systemen
- Diese können viel größere Datenmengen in einer höheren Geschwindigkeit verarbeiten
- Erkennt subtile, aber auch komplexe Methoden
Digitale Assistenten
Digitale Assistenten sind wohl die prominentesten Anwendungen von Machine Learning im Alltag. Eine Umfrage von Splendid Research in 2019 zeigt:
- Von rund 1.000 Befragten haben 60% schon einmal ein Gerät per Sprachsteuerung bedient.
- Zwei Jahre zuvor waren es nur 37% der knapp 1000 Befragten.
- Von den 605 Befragten gaben 19% an, solche Systeme mehrmals pro Woche zu nutzen, 11% der Nutzer sogar täglich.
- Die beliebtesten Anwendungen: Suchergebnisse bei Google abrufen (52%), Musik abspielen (51%) und das Wetter abfragen (46%).
Digitale Assistenten werden auch vermehrt in anderer Form eingesetzt. So werden beispielsweise moderne Kamerasysteme durch KI-Module unterstützt, um optimale Voreinstellungen für das Bild zu treffen oder Personen und Objekte im Bild zu erkennen und zu tracken. Auch das Schreiben von Texten und die Erstellung von Grafiken kann von digitalen Assistenten wie ChatGPT oder Dall-E übernommen werden.
Mobilität
In der Mobilität und im Verkehr ist Machine Learning immer häufiger vertreten. Autonomes Fahren ist ein gutes Beispiel:
- Es werden verschiedene Sensordaten ausgewertet und so genaue Informationen zu dem Fahrzeugzustand und der Umgebung generiert.
- Neuronale Netze ermöglichen sichere Navigation im Straßenverkehr und reagieren in Echtzeit auf kritische Situationen.
Ebenso werden in der Infrastruktur Machine Learning Modelle angewandt, um so beispielsweise die Ampelschaltung an großen Kreuzungen zu optimieren. Diese intelligenten Systeme erkennen Ansammlungen von Autos und sollen mit einer reaktiven Schaltung der Grünphasen Staus verhindern.
Predictive Maintenance und Logistics
Der herkömmliche Ansatz klassischer Maintenance Systeme ist meist zeitpunktbasiert oder reaktiv nach festgesetzten Intervallen.
- Problem: Oft verliert man an der Stelle Zeit und Ressourcen, bis das Problem behoben wurde.
- Lösung: Überwachung von Sensordaten, um Abweichungen frühzeitig zu erkennen und sogar prognostizieren
- Supply Chain kann automatisch aufrechterhalten werden
Beispiel: McDonalds plant und kontrolliert die Lieferung von Zutaten und Zubereitungen von Mahlzeiten
Notdienste
Heutzutage nutzt die Polizei Machine Learning, um mögliche Verbrechen vorherzusagen und plant dementsprechend Patrouillen. Einbrüche sind da ein gutes Beispiel:
- Die Aufklärungsquote bei Wohnungseinbrüchen in Deutschland lag 2018 bei gerade einmal 18 Prozent.
- Maschinelles Lernen wird eingesetzt, um Einbrüche zu verhindern, bevor sie passieren.
- Erfolg: Rückgang der Wohnungseinbrüche von 116.540 Fällen (2018) auf 97.504 Fälle (2019), ein Rückgang um 16,3%.
Auch die Feuerwehr setzt mittlerweile autonome Löschfahrzeuge wie Drohnen oder Kleinlöschfahrzeuge ein, die durch maschinelles Lernen Personen und Objekte auch in dichtem Rauch und Dunkelheit erkennen können. Diese Fahrzeuge können in Räumen oder Gebieten eingesetzt werden, die für Menschen lebensgefährlich sind, und sind daher ein sehr wertvolles Werkzeug für die Einsatzkräfte.
Machine Learning Algorithmen Übersicht
Die folgenden Machine Learning Algorithmen können für viele Problemstellen genutzt werden:
- Lineare Regression
- Logistische Regression
- Entscheidungsbaum
- Support Vector Machine (SVM)
- K-Nearest Neighbor
- Clustering Algorithmen
- Random Forest
- Gradient Boosted Trees:
- künstliche Neuronale Netze
- Feed forward neural networks
- Recurrent Neural Networks (RNN)
- viele weitere
Wie funktioniert der Machine Learning Prozess?
Ein Machine Learning Prozess in der Praxis sieht wie so aus:
- Problemdefinition, Zieldefinition und Wissensaustausch. Die Ziele und der Einsatzzweck des maschinellen Lernens müssen im Vorfeld klar definiert werden. Was soll durch maschinelles Lernen optimiert werden?
- Datenbeschaffung, Transformation und Merkmalsextraktion. Dies ist in der Regel der zeitaufwendigste Schritt, da es wichtig ist, qualitativ hochwertige Daten zu verwenden. Hier kann z.B. ein ML Feature Store hohe Effizienz bringen.
- Lernphase. In diesem Schritt findet das maschinelle Lernen statt. Der maschinelle Lernalgorithmus wird trainiert.
- Interpretation der Ergebnisse. Die Interpretation der Ergebnisse und des Modells ist für den Prozess essentiell. Ein wichtiger Schritt, um auch Akzeptanz für maschinelles Lernen im Fachbereich zu schaffen. Der Mensch will verstehen, was im Algorithmus passiert.
- Produktiver Einsatz. Machine Learning nur in Innovation Labs zu entwickeln und dann nicht in realen Prozessen einzusetzen, bringt keinen Mehrwert. Die technischen Anforderungen an das maschinelle Lernen sind komplex, daher ist der produktive Einsatz nicht immer einfach.
Dieser Prozess wird so häufig durchlaufen, bis die gewünschten Ergebnisse vorhanden sind.
Folgend haben wir Ihnen den ML-Prozess in einer Infografik visualisiert:

Ein Vorgehensmodell, was in der Literatur oft beschrieben wird, ist der CRISP-DM Prozess. Ein Prozess der für das Data Mining entwickelt wurde. Dieser Prozess ist nicht allein auf das Machine Learning fokussiert, sondern bezieht auch die Ziele aus Sicht der Business-Anwendung mit ein.
Bringen Sie Ihr Machine Learning in den produktiven Betrieb
Mit DSX Machine Learning etablieren Sie standardisierte, skalierbare MLOps-Strukturen – in wenigen Wochen statt Monaten.
Was ist der Unterschied zwischen Machine Learning und Deep Learning?
Praktisch gesehen ist Deep Learning eine Teilmenge von Machine Learning, daher ist tiefes Lernen technisch gesehen immer maschinelles Lernen. Allerdings unterscheiden sich die Fähigkeiten dieser beiden Arten.
Der Hauptunterschied zwischen Deep Learning und Machine Learning liegt in der Fähigkeit, durch künstliche neuronale Netzwerke (KNN), unstrukturierte Daten zu verarbeiten. Deep Learning durch künstliche Neuronale Netze ist in der Lage unstrukturierte Informationen wie Texte, Bilder, Töne und Videos in numerische Werte umzuwandeln und zu verarbeiten. Diese extrahierten Informationen lassen sich dann zur Mustererkennung, Vorhersage oder zum weiteren Lernen verwendet.
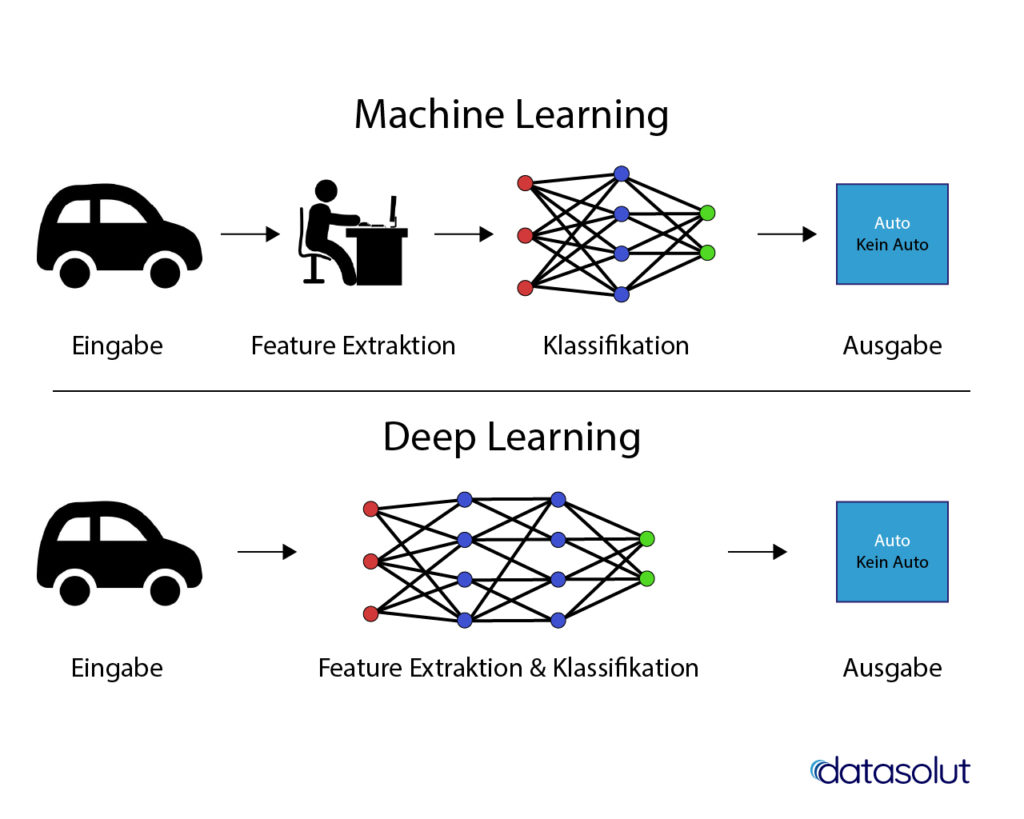
Klassisches maschinelles Lernen, z.B. mit Entscheidungsbaumverfahren, ist nicht in der Lage, diese unstrukturierten Daten sinnvoll zu verarbeiten. So können beispielsweise Bilder nicht einfach als Eingabedaten verwendet werden, um einen Algorithmus zur Objekterkennung zu trainieren. Hier wäre immer ein aufwändiges Feature-Engineering durch einen Menschen erforderlich.
In der folgenden Tabelle sehen Sie die Hauptunterschiede zwischen Deep Learning und Machine Learning:
| Machine Learning | Deep Learning | |
| Datenstruktur | Strukturierte Daten | Unstrukturierte und strukturierte Daten |
| Datensatzgröße | Klein – Mittel | Groß |
| Hardware | Funktioniert mit einfacher Hardware. | Braucht leistungsstarke Computer (mit GPUs). Neuronale Netze multiplizieren Matrizen, die sehr viel Rechenzeit brauchen – GPUs beschleunigen den Vorgang. |
| Feature Extraktion | Sie müssen die Merkmale in der Regel verstehen. | Sie müssen die Merkmale nicht verstehen. |
| Laufzeit | Ein paar Minuten bis Stunden | Bis zu Wochen und Monaten. Künstliche neuronale Netze müssen einen enorm viele Gewichte berechnen. |
| Interpretierbarkeit | Einige Algorithmen sind leicht zu interpretieren (Logistische Regression, einfache Entscheidungsbäume), andere sind fast unmöglich (SVM, XGBoost). | Schwer zu interpretieren und oft unmöglich. |
Einen kompletten Vergleich dieser zwei Methoden finden Sie hier: Deep Learning vs. Machine Learning: Wo liegt der Unterschied?
Schauen wir uns zum Schluss an, ob die einzeln Machine-Learning-Prozessschritte auch ohne Mensch funktionieren.
Ist AutoML die Zukunft von Machine Learning?
AutoML ist die Automatisierung der einzelnen ML-Prozessschritte. Anstatt die Architektur und die Modellauswahl akribisch von Data Science Teams herausfinden zu lassen, automatisiert AutoML diesen Prozess und reduziert die menschliche Arbeitszeit.
Am Ende muss der Mensch höchstens noch auf die Modellergebnisse blicken. Auch die sehr aufwendige Datenvorverarbeitung im Machine Learning (laut Forbes ca. 80% der Zeit eines ML-Projekts) wird von einigen AutoML Frameworks schon übernommen.
Brauchen wir den Menschen dann zukünftig noch? Unsere Antwort ist ein klares Ja. Besonders die fachliche Expertise, die der Mensch mitbringt kann nicht so leicht durch einen Algorithmus ersetzt werden. Auch wenn Machine Learning eine „Tiefenanalyse“ ermöglicht, kann er nicht so zwischen den Zeilen lesen, wie eine erfahrene Fachkraft. Das Design der Datensätze sollte ebenfalls weiterhin Aufgabe der Menschen sein.
Klar ist, dass große Unternehmen extrem viel Geld in die Automatisierung von ML-Prozessen stecken und auch immer mehr Unternehmen das Potenzial Ihrer Daten durch KI nutzen.
Fazit: Maschinelles Lernen und die Potentiale für die Zukunft
Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz und verwendet Algorithmen und statistische Methoden, um Daten zu analysieren und Muster zu erkennen. Aufgrund der wachsenden Datenmengen ist es schwierig, wertvolle Informationen aus einfachen Datenanalysen zu extrahieren. Hier hilft maschinelles Lernen, diese Informationen herauszufiltern, Muster zu erkennen und Vorhersagen zu treffen. So können Unternehmen durch maschinelles Lernen die richtigen Entscheidungen treffen und ihre Prozesse deutlich verbessern.
Auch in unserem Alltag begegnet uns maschinelles Lernen. Ob Social Media, E-Commerce oder Medizin, überall kommt maschinelles Lernen zum Einsatz. Es ist daher nicht mehr wegzudenken und wir können davon ausgehen, dass maschinelles Lernen in den nächsten Jahren immer mehr unser persönliches Leben begleiten wird.
Wenn Sie Fragen zu maschinellem Lernen haben, dann melden Sie sich bei uns.
FAQ – Die wichtigsten Fragen schnell beantwortet
Machine Learning ist ein Teilbereich der Künstlichen Intelligenz. Mit der Hilfe von Machine Learning lassen sich Algorithmen trainieren, die Zusammenhänge identifizieren und Muster erkennen. Machine Learning versetzt Systeme dazu in die Lage, automatisch aus Erfahrungen (Daten) zu lernen.
Maschinelles Lernen kann in verschiedenen Bereichen angewendet werden, z.B. für die:
– Vorhersage von Werten
– Berechnung von Wahrscheinlichkeiten
– Identifizierung von Gruppen und Zusammenhängen
– Filterung von Informationen
– Optimierung der Geschäftsprozesse
Damit das ML-Modell Zusammenhänge finden kann, benötigt es vorab ein Training. Dieses Training sieht wie folgt aus:
1. Ein Mensch stellt dem Algorithmus Trainingsdaten zur Verfügung.
2. Der Algorithmus untersucht diese Daten nach Mustern und Zusammenhänge.
3. Ist der Trainingsprozess abgeschlossen bleibt, liegt ein sicheres Modell vor.
4. Das ML-Modell wird dann dazu verwendet, unbekannte Daten zu analysieren und auszuwerten.
Künstliche Intelligenz umfasst das gesamte Feld der intelligenten Systeme, dessen Ziel es ist, Menschliche Intelligenz nachzuahmen. Machine Learning ist ein Teilbereich der Künstlichen Intelligenz, der fokussiert ist auf die Entwicklung von Algorithmen und Modellen, die aus Daten lernen und in diesen Muster und Zusammenhänge erkennen können.
Es basiert auf beidem, da Machine Learning ein Teilbereich der KI ist. ChatGPT basiert auf Machine Learning, genauer gesagt auf einem speziellen Modelltyp namens Transformer, das auf Deep Learning-Techniken basiert. Es wurde mit großen Mengen an Textdaten trainiert, um Muster in der Sprache zu lernen und darauf basierend menschenähnliche Texte zu generieren.

Ihr nächster Schritt mit uns!
Wenn Sie gerade prüfen, wie KI in Ihrer Organisation sinnvoll eingesetzt werden kann, ist ein unverbindliches Orientierungsgespräch der beste erste Schritt. In wenigen Minuten klären wir:
- wo Sie gerade stehen
- welche Erwartungen realistisch sind
- ob unser KI-Workshop sinnvoll für Sie ist










