


Was brauchen Sie für die Umsetzung erfolgreicher Data Science Projekte? In diesem Artikel erfahren Sie, welche Faktoren Sie bei der Umsetzung beachten sollten, und wie Sie die richtigen Fragen stellen, um erfolgreiche Data Science Anwendungen umzusetzen.
Was sind die Besonderheiten von Data Science Projekten?
Das Besondere an Data Science Projekten ergibt sich aus dem Zusammenspiel der verschiedenen Bereiche Mathematik und Statistik, Informatik und Programmierung sowie fachliche Anforderungen an die Problemstellung. Diese Zusammenkunft der Disziplinen machen solche Projekte häufig komplex.
Es braucht einen interdisziplinären Ansatz, der auch dem Fachbereich einen Austausch mit dem Data Science Team ermöglicht. Somit sollen Teammitglieder nicht nur Experten in ihrem Gebiet sein, sondern darüber hinaus über gute kommunikative Fähigkeiten verfügen.
Eine weitere Besonderheit an Data Science Projekten ist, dass Projekte häufig interaktiv ablaufen. Zunächst wird in der Regel ein “Proof of Concept” entwickelt, um zu ermitteln, ob eine Data Science Lösung die gewünschte Verbesserung bringt. Erst danach überführt man diese Lösung in einen Regelprozess, wo möglicherweise nochmal mehr Arbeit in die Datenvorverarbeitung gesteckt wird.
Doch dann ist das Data Science Projekt noch nicht umgesetzt. Denn ein implementiertes Modell verliert nach einer Zeit an Qualität. Das Bedeutet, dass Modelle immer wieder neu trainiert werden müssen, um diese an die Daten anzupassen (siehe folgende Abbildung).
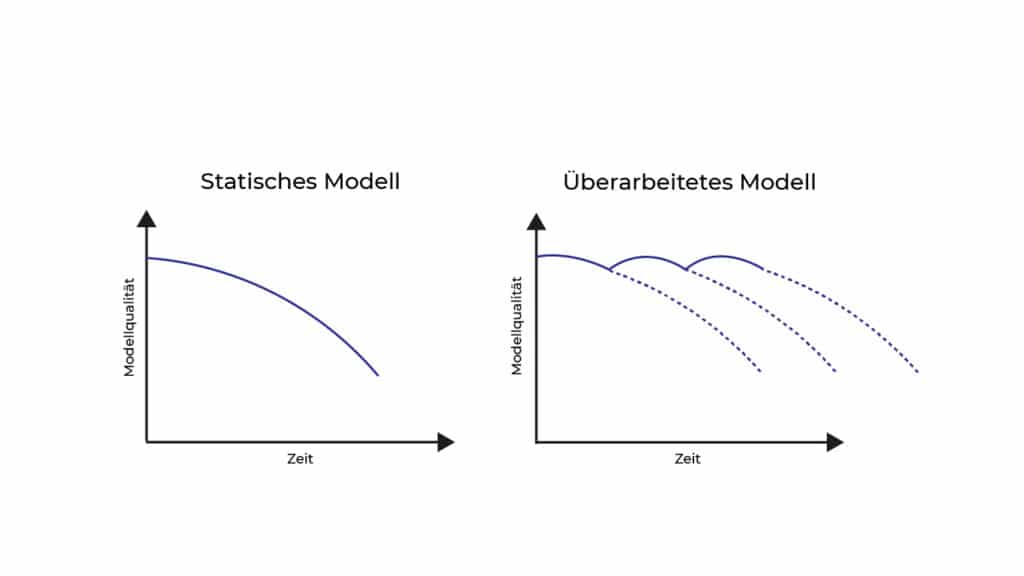
Das Wissen um die Besonderheiten der Data Science Projekte hilft uns dabei, die Aufgabenstellung zu unserem Data Science Projekt zu definieren. Wie genau das funktioniert, sehen wir uns im nächsten Abschnitt an.
Wie definiere ich die Aufgabenstellung?
Die Aufgabenstellung eines Data Science Projektes ist das Herzstück dieses – doch wie definieren wir sie?
Die Definition der Aufgabenstellung für das Projekt sollte möglichst interdisziplinär entwickelt werden. Experten mit verschiedenen Fähigkeiten sollen gemeinsam an einer Idee für die Aufgabenstellung arbeiten. Die Entwicklung basiert dabei auf den vorhandenen Datenquellen, der fachlichen Problemstellung und den technischen Gegebenheiten bzw. der Machbarkeit.
Stellen Sie sich mit Ihrem Team für die Definition folgende Fragen:
- Wie wird sich mein Geschäft in Zukunft entwickeln?
- Was beeinflusst das Kaufverhalten meiner Kunden?
- Wie kann ich die Interaktion mit meinen Kunden noch persönlicher gestalten?
- Welche Produkte interessieren meine Kunden?
- Wie kann ich meine Prozesse optimieren?
Das Ziel ist es am Ende des Tages eine klar definierte Fragestellung vorliegen zu haben mit welcher wir nach den passenden Data Science Anwendungsfällen suchen können. Lassen Sie uns gemeinsam ansehen, wie wir Data Science Anwendungsfälle identifizieren und nach Ihrem Nutzen bewerten.
Identifikation und Bewertung von Data Science Anwendungsfällen
Data Science Anwendungsfälle ermöglichen uns die Betrachtung aller möglichen Szenarien, um mit Hilfe eines Systems oder Werkzeugs das fachliche Ziel zu erreichen. Im Kern geht es also darum:
- zu verstehen,
- zu beobachten,
- die Sichtweise zu definieren,
- Ideen zu finden,
- Prototypen zu entwickeln
- und unser Konzept zu verfeinern.
Sehen wir uns das genauer an:
Grundvoraussetzung ist zunächst, dass alle Beteiligten Grundkenntnis über Data Science und KI verfügen sollten – nur so kann ein gemeinschaftliches Projekt geführt werden.
| Bewertungskriterium | Aufgabe |
| Geschäftsmodell verstehen und die Problemstellung definieren | Schwerpunkt festlegen: Schnittpunkt zu Kunden oder interne Prozesse? Ziel definieren: welcher Prozess soll optimiert werden? |
| Anwendungsfälle nach Kosten & Nutzen bewerten | Nachdem eine Liste an potenziellen Anwendungsfälle gefunden ist, geht es an Bewertung: 1. Komplexität der Implementierung (hängt von Datenverfügbarkeit, Qualität und Updates ab) 2. Kosten- Nutzen-Aspekt (Mehrwert für benötigte Mittel) |
| Evaluierung der Daten | 1. Welche Daten werden benötigt: Wie viel Aufwand, um diese zu integrieren? 2. Algorithmen: Gibt es bereits Implementierungen des Use Cases? 3. Prozesse und Systeme: Welche Prozesse werden durch Projekt möglicherweise beeinflusst? Müssen Änderungen an existierenden Prozessen vorgenommen werden? 4. Notwendige Erfahrung: Sind technische Skills und Fachwissen im Unternehmen vorhanden? |
| Priorisierung | In einem letzten Schritt sollten wir die Data Science Projekte final priorisieren, zum Beispiel durch eine Prioritätsmatrix mit 2 Runden. 1. Runde: Grobe Bewertung 2. Runde: Überprüfung und Priorisierung |
Dabei ist es sinnvoll, die Anwendungsfälle nach den folgenden Parametern zu clustern:
- Dem erforderlichen Daten-Input
- Den dafür erforderlichen KI-Ressourcen
- Produkte und Prozesse für welche die Use Cases in Frage kommen
Ist der passende Date Science Anwendungsfall gefunden, geht es an die Bildung des Teams.
Hier finden Sie ein Beispiel für einen Data Science Use Case, den wir gemeinsam mit unserem Kunden umsetzten: KI im B2B Vertrieb
Welche Teammitglieder brauche ich für ein erfolgreiches Data Science Projekt?
Die hohe Komplexität der Data Science Projekte setzt eine gute Teamzusammensetzung voraus, in der die verschiedenen Fähigkeiten aus den Bereichen Informatik, Mathematik und Domänenexpertise zusammengeführt werden.
Sehen wir uns die Teammitglieder mit den Anforderungen an Ihren Job an:
| Jobbezeichnung | Anforderungen an Jobprofil |
| Data Engineer | Erfassung, Aufbereitung und Prüfung von Daten-Fundament für BigData, Data Warehouse, etc. Aufgabe: Datenbanken und Datenformate bereitstellen Hier geht es zu unserer Data Engineering Beratung! |
| Data Scientist | ML-Feature Definition, Weiterverarbeitung zu Trainingsdaten, Training der Algorithmen, Transfer der Infos zu Fachabteilungen Fähigkeiten/ Aufgaben: bilden von Mathematischen und Stochastischen Modellen; Kenntnisse über Datenverarbeitung und Grundlagen der Programmierung; Branchenkenntnisse |
| ML-Engineer | Aufgabe: Unterstützung des Data Scientist bei Implementierung der KI in produktive Umgebung; Monitoring der ModelleArbeiten mit Ergebnissen der Data Science Experten |
| DevOps Engineer | Development und OperationsIst für Deployments verantwortlich und verwaltet die CI/CD PipelineIst für administrative und softwarebasierte Tätigkeiten im Unternehmen zuständig |
| Domänenexperte | Hilft Zielstellung anhand KI zu lösen durch fachliche Kenntnisse Tiefes Wissen über Prozesse und jeweilige Branche |
In der folgenden Abbildung wird nochmals deutlich, wie die einzelnen Jobprofile in einem KI-Projekt ineinandergreifen und somit miteinander arbeiten.
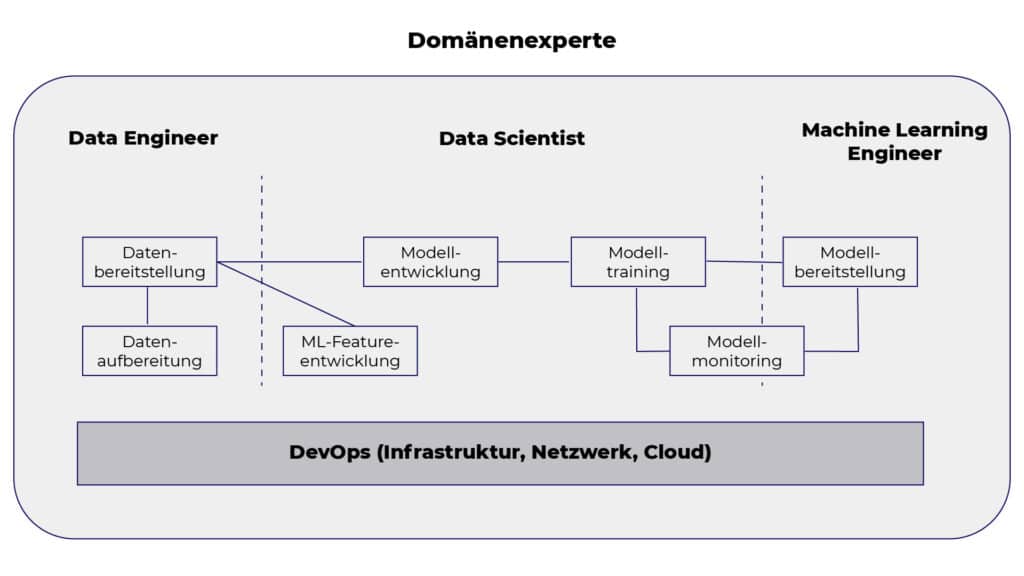
1. Organisatorisch: Es gibt 3 strukturelle Faktoren
- Datenorientierte Ausrichtung (Management, Team, Ressourcen)
- Mehrwert durch (Wertschöpfungskette von Daten)
- Disziplin (Fokus auf Problemstellung, die mit Data Science gelöst werden soll)
2. Technisch
- Iterative Vorgehensweise (Modelle zu Beginn einfach halten). Der Vorteil: man durchläuft die Daten- und Modellpipeline komplett, sammelt wichtige Erkenntnisse und kann schnell Änderungen vornehmen
- Zu Beginn: Grundlagen und Infrastruktur aufsetzen à Änderungen können schnell deployed und Ergebnisse getracked werden
Anwendungsbeispiel für ein erfolgreiches Data Science Projekt
Ein Unternehmen der Versicherungsbranche verfügt über 3.000.000 Aktivkunden, die sich in einer festen Vertragslaufzeit befinden. Marketing- und Vertriebsteam sind stets darum bemüht die Kunden von einem Upgrade des bestehenden Vertrags zu überzeugen.
Das Management ist sich darüber bewusst, dass hier ein enormes Optimierungspotenzial bestünde, wenn die Mitarbeiter Informationen über die Interessen der Kunden erhalten würden. Durch konkrete Handlungsempfehlungen könnten Kunden mit hoher Wahrscheinlichkeit für ein Vertrags-Upsell identifiziert werden. Nur benötigt es für diese Optimierung die Analyse der Daten der vergangenen Interaktionen mit den Kunden. Daraufhin entscheidet sich das Management für den Aufbau eines Data Science Projektes.
Die ersten Schritte zum erfolgreichen Data Science Projekt
- Zielsetzung definieren: Aus den Kundendaten soll hervorgehen, welcher Kunde affin für einen Vertrags-Upsell ist.
- Data Science Projekte nach Priorität bewerten: Die Data Science Projekte Next Best Offer oder Upsell-Prognose sind am sinnvollsten
- Evaluierung der Daten: Wir benötigen vor allem die Daten zum vergangenen Kaufverhalten der Kunden, sowie demografische Daten zu den Kundenprofilen. Bis jetzt wurde noch kein Algorithmus in den Prozessen des Unternehmens implementiert.
- Finale Priorisierung des Data Science Projektes: Festlegung auf Upsell-Prognose, denn hier liegt der Fokus auf einem Optimierungsbereich und die vorhandenen Daten reichen aus
- Die Findung des Data Science Team: Es sollten Experten der Bereiche Datenverarbeitung, Modellentwicklung und Datenauswertung in einem stetigen Austausch stehen. Wichtig hierbei ist, dass alle Mitarbeiter, die mit dem Data Science Projekt in Kontakt kommen – sei es bei der Entwicklung, Implementierung oder Anwendung der Ergebnisse – über die allgemeine Funktionsweise dieses informiert sind. Nur so funktioniert ein Austausch.
- Der Umgang mit den Ergebnissen des Data Science Projektes: Die Ergebnisse sollen in Korrelation zu den Kunden betrachtet werden. Es ist somit wichtig, dass ein ständiger Austausch mit dem Kunden und den Mitarbeitern erfolgt, um qualitativ hochwertige Ergebnisse zu erzielen.
Ist das Data Science Projekt erst in die reale Umgebung implementiert, dienen die Ergebnisse der Upsell-Prognose als konkrete Handlungsempfehlungen für Marketing- und Vertriebsmitarbeiter. Diese nutzen die Ergebnisse, um personalisierte Angebote zu unterbreiten und steigern somit die Upsell-Quote.
Fazit – Data Science Projekte erfolgreich umsetzen ist leicht (wenn man weiß wie)
Wie wir sehen, ist das A und O für den Aufbau und die Umsetzung eines erfolgreichen Data Science Projektes: Das Data Science Team und der Umgang mit den Daten selbst. Eine interdisziplinäre Zusammenarbeit und eine funktionierende Kommunikation ist die Grundvoraussetzung für die korrekte und zielführende Auswertung von vorhandenen Daten über die Kunden.
Sie möchten gerne ein Data Science Team aufbauen oder wollen zu Data Science Projekten beraten werden? Mit Unterstützung unserer Data Science Beratung können Sie Ihr Data Science Projekte erfolgreich umsetzen.
FAQ – Die wichtigsten Fragen schnell beantwortet
Zunächst sollte eine Zielsetzung definiert werden, damit für die anschließende Priorisierung der Data Science Use Cases klar ist, was erreicht werden soll. Anschließend an die Priorisierung werden die Daten evaluiert, damit wir im nächsten Schritt die für uns passenden Data Science Projekte filtern können. Ist das passende Projekt gefunden geht es an die Zusammensetzung des Data Science Team.
Für ein erfolgreiches Data Science Projekt benötigt man:
1. Ein Team aus Spezialisten verschiedener Fachabteilungen.
2. Jede Menge Daten.
3. Eine feste Zielsetzung.
4. Eine gute Kommunikation.
5. Geduld.
Grundsätzlich sollte man sich zu Beginn fragen, was man genau mit der Implementierung des Data Science Projektes erreichen möchte: Welche Prozesse des Unternehmens können durch ein Data Science Projekt optimiert werden? Sobald die Fragestellung definiert ist, sollte eine Liste mit möglichen Data Science Projekten erstellt werden, die wiederrum durch die Evaluation der Daten des Unternehmens nach Nutzen priorisiert werden. Zum Schluss folgt die finale Auswahl des am besten passenden Data Science Projektes.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte











