


LLMOps (Large-Language-Model-Operations) verwendet spezielle Tools und Verfahren zur Verwaltung großer Sprachmodelle. In diesem Artikel werfen wir einen detaillierten Blick auf LLMOps, seine
- Bedeutung,
- Herausforderungen
- und Best Practices,
um die Potenziale von LLMs voll auszuschöpfen.
Lassen Sie uns starten!
Was sind Large Language Models (LLMs)?
Large Language Models (LLMs), wie OpenAI’s GPT-Reihe oder Googles BERT, sind fortschrittliche Künstliche Intelligenzen, die in der Lage sind, menschenähnliche Texte zu
- generieren,
- zu verstehen
- und auf diese zu reagieren.
Diese Modelle werden auf riesigen Datenmengen trainiert und haben die Fähigkeit, eine Vielzahl von Aufgaben zu bewältigen.
Im Sinne einer einfachen Informatik-Definition sind große Sprachmodelle (Large Language Models, LLMs) eine Art generativer KI, die Deep-Learning-Algorithmen verwendet und die Art und Weise simuliert, wie Menschen denken könnten. Sehen wir uns an, wofür Sie LLMs nutzen können.
Wie können Sie LLM für Ihr Unternehmen nutzen?
Das Training von Basic-LLMs wie GPT, Claude, Titan und LLaMa kann ein unnötig hohes finanzielles Investment darstellen. Den meisten Unternehmen fehlt es an einem hohen Budget, einer fortschrittlichen Infrastruktur und erfahrenem Fachwissen im Bereich des maschinellen Lernens, um Basismodelle zu trainieren und sie für den Aufbau generativer KI-gestützter Systeme nutzbar zu machen.
Anstatt ein Basismodell zu trainieren, suchen viele Unternehmen nach kostengünstigeren Alternativen, um LLMs in ihren Betrieb zu integrieren. Jede Entscheidung erfordert jedoch einen gut definierten Prozess und die richtigen Tools, um die
- Entwicklung,
- Bereitstellung
- und Wartung
zu erleichtern. Die drei wichtigsten Tools stellen wir Ihnen nun kurz vor:
Prompt Engineering
Prompt Engineering umfasst die geschickte Erstellung von Texteingaben, die als Prompts bezeichnet werden, um ein LLM zur Erzeugung der beabsichtigten Ausgabe zu steuern. Techniken wie few-shot und chain-of-thought (CoT) Prompts verbessern die Genauigkeit und Antwortqualität des Modells.
Diese Methode ist unkompliziert und ermöglicht Unternehmen die Interaktion mit LLMs über API-Aufrufe oder benutzerfreundliche Plattformen wie die ChatGPT-Weboberfläche.
Feinabstimmung (Fine Tuning)
Die Feinabstimmung verbessert den Output des Modells und minimiert Halluzinationen (Antworten, die logisch richtig klingen, aber ungenau sind). Obwohl die anfänglichen Kosten für die Feinabstimmung teurer sein könnten als die prompte Entwicklung, werden die Vorteile während der Inferenz deutlich.
Retrieval Augmented Generation (RAG)
RAG wird oft auch als Wissens- oder Prompt-Erweiterung bezeichnet und baut auf der Prompt-Entwicklung auf, indem Prompts mit Informationen aus externen Quellen wie Vektordatenbanken oder APIs ergänzt werden. Diese Daten werden in den Prompt eingearbeitet, bevor er an das LLM übermittelt wird.
Wie Sie Large Language Models optimal mit den richtigen Tools einsetzen, um Prozesse in Ihrem Unternehmen zu vereinfachen, zeigen wir Ihnen im Folgenden. Wir starten mit der Definition von LLMOps.
Was ist LLMOps?
Large Language Model Operations, kurz LLMOps, markiert einen Wendepunkt in der Entwicklung und dem Einsatz von Großen Sprachmodellen (LLMs) in der Praxis.
Als Teilbereich von Machine Learning Operations (MLOps) widmet sich Large Language Model Operations (LLMOps) der Überwachung des Lebenszyklus von LLMs von der Ausbildung bis zur Wartung unter Verwendung verschiedener Methoden.
Der Fokus liegt insbesondere auf der Lösung folgender Herausforderungen:
- Umfangreiche Datenverarbeitungsressourcen für Training und Feinabstimmung,
- die Handhabung von komplexen Entwicklungszyklen,
- Skalierbarkeit und Risikomanagement,
- sowie Modellbereitstellung und -überwachung.
LLMOps ist essenziell für die effiziente Implementierung und Wartung von LLMs. Es erfordert eine interdisziplinäre Zusammenarbeit zwischen Data Scientists, DevOps Engineers und IT-Fachkräften. Die Hauptziele von LLMOps sind die
- Maximierung der Effizienz,
- die Gewährleistung der Skalierbarkeit
- und die Minimierung von Risiken.
Das erreichen wir durch die Anwendung spezifischer Best Practices in den Bereichen explorative Datenanalyse, Datenaufbereitung, Prompt Engineering, Modelloptimierung, Modellprüfung und -governance, Modellinferenz und -bereitstellung sowie Modellüberwachung.
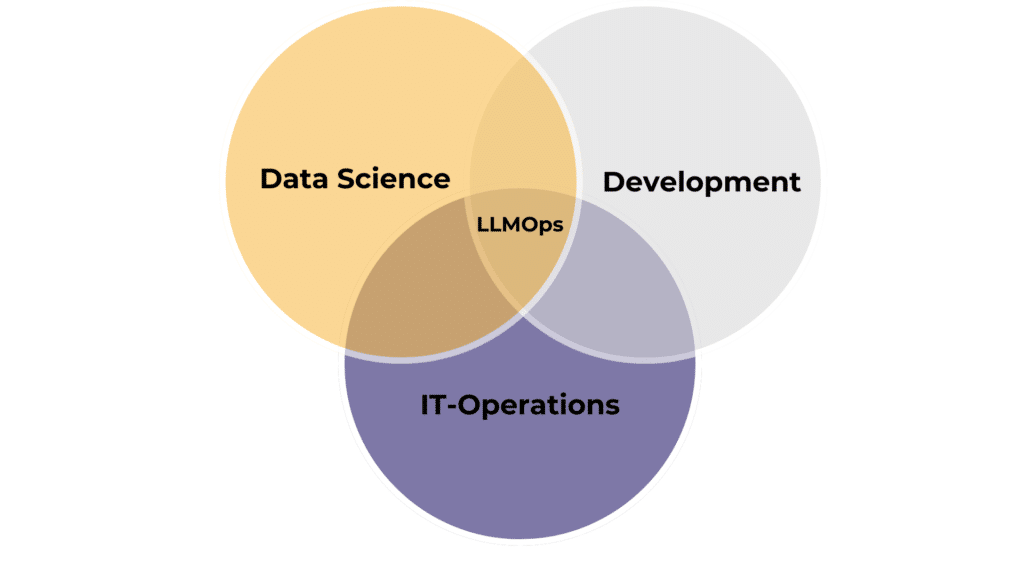
Insgesamt ermöglicht LLMOps Unternehmen, die Fähigkeiten von LLMs voll auszuschöpfen, indem es strukturierte Prozesse und Richtlinien für die
- Entwicklung,
- Implementierung
- und Wartung
dieser Modelle bereitstellt. Sehen wir uns an, welche konkreten Herausforderungen LLMOps ansteuert.
Warum ist LLMOps wichtig?
LLMOps ermöglicht es Unternehmen mit den neuesten Entwicklungen in der Sprachmodelltechnologie Schritt zu halten. Durch die Implementierung von LLMOps können Organisationen die Leistungsfähigkeit von Large Language Models (LLMs) voll ausschöpfen, was wiederum zu innovativen Anwendungen und Dienstleistungen führt.
MLOps bildet das wesentliche Gerüst für die Entwicklung, Bereitstellung und Wartung von KI-Modellen im großen Maßstab. LLMOps, das sich auf generative KI spezialisiert, basiert immer noch auf den grundlegenden Prinzipien von MLOps. Für beide – traditionelles maschinelles Lernen und LLM-getriebene Anwendungen – sind vier Kernprinzipien wichtig:
- Geschäftsziele im Fokus,
- datenzentrierter Ansatz,
- modulare Implementierung
- und automatisierte Prozesse.
Databricks bietet eine einheitliche Plattform für MLOps und LLMOps, einschließlich Werkzeuge wie Unity Catalog, MLflow und Lakehouse Monitoring.
Es geht nicht nur darum, die Modelle effizient zu betreiben und zu warten, sondern auch darum, sicherzustellen, dass sie verantwortungsbewusst und in Übereinstimmung mit den geltenden Vorschriften eingesetzt werden.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei der Entwicklung Ihres Large Language Models.
Die Fähigkeit, LLMs effektiv zu managen, öffnet die Tür für KI-basierte Lösungen, die in einer Vielzahl von Branchen eingesetzt werden können: Von der Kundenbetreuung bis hin zur Gesundheitsforschung. LLMOps ist somit ein zentraler Faktor für Unternehmen, die wettbewerbsfähig bleiben wollen.
Wie funktioniert LLMOps?
LLMOps stattet Entwickler mit den wesentlichen Werkzeugen und Best Practices aus, die sie für die Verwaltung des Entwicklungslebenszyklus von LLMs benötigen. Obwohl viele Aspekte von LLMOps MLOps widerspiegeln, erfordern die Grundmodelle neue Methoden, Richtlinien und Werkzeuge.
Untersuchen wir den LLM-Lebenszyklus mit Schwerpunkt auf der Feinabstimmung, da es für Unternehmen ungewöhnlich ist, LLMs von Grund auf neu zu entwickeln.
Bei der Feinabstimmung beginnen Sie mit einem bereits trainierten Basismodell. Anschließend trainieren Sie es auf einem spezifischeren, kleineren Datensatz, um ein benutzerdefiniertes Modell zu erstellen.
Nach der Bereitstellung dieses benutzerdefinierten Modells werden Eingabeaufforderungen gesendet und die entsprechenden Vervollständigungen zurückgegeben. Es ist wichtig, das Modell zu überwachen und neu zu trainieren, um sicherzustellen, dass seine Leistung konstant bleibt, insbesondere bei KI-Systemen, die von LLMs gesteuert werden.
LLMOps erleichtert die praktische Anwendung von LLMs durch die Einbeziehung von Prompt-Management, LLM-Verkettung, Überwachung und Beobachtungstechniken, die in konventionellen MLOps nicht zu finden sind.
Verwaltung von Eingabeaufforderungen (Prompt Management)
Prompts sind das wichtigste Mittel für die Interaktion mit LLMs. Jeder, der schon einmal eine Eingabeaufforderung erstellt hat, weiß, dass deren Verfeinerung eine sich wiederholende Aufgabe ist, die mehrere Versuche erfordert, um ein zufriedenstellendes Ergebnis zu erzielen.
LLMOps-Tools bieten in der Regel Funktionen zur Verfolgung und Versionierung von Prompts und ihren Ergebnissen im Laufe der Zeit. Dadurch lässt sich die Gesamtwirksamkeit des Modells leichter beurteilen. Bestimmte Plattformen und Tools ermöglichen auch Prompt-Bewertungen über mehrere LLMs hinweg, so dass Sie schnell das LLM mit der besten Leistung für Ihren Prompt finden können.
LLM-Verkettung (-Chaining)
Bei der LLM-Verkettung werden mehrere LLM-Aufrufe nacheinander verknüpft, um eine bestimmte Anwendungsfunktion zu liefern. In diesem Arbeitsablauf dient die Ausgabe eines LLM-Aufrufs als Eingabe für den nachfolgenden LLM-Aufruf und gipfelt in dem Endergebnis. Dieser Entwurfsansatz stellt einen innovativen Ansatz für den Entwurf von KI-Anwendungen dar und zerlegt komplexe Aufgaben in kleinere Schritte.
Anstatt zum Beispiel eine einzige umfangreiche Aufforderung zum Schreiben einer Kurzgeschichte zu verwenden, können Sie die Aufforderung in kürzere Aufforderungen zu bestimmten Themen aufteilen und erhalten so genauere Ergebnisse.
Chaining bekämpft die inhärente Beschränkung der maximalen Anzahl von Token, die ein LLM auf einmal verarbeiten kann. LLMOps reduziert die Komplexität, die mit der Verwaltung der Kette verbunden ist, und kombiniert die Verkettung mit anderen Dokumentenabfragetechniken wie dem Zugriff auf eine Vektordatenbank.
Überwachung und Beobachtbarkeit (Monitoring und Observability)
Ein LLM-Beobachtungssystem sammelt nach dem Einsatz des Modells Datenpunkte in Echtzeit, um eine mögliche Verschlechterung der Modellleistung zu erkennen. Die Echtzeitüberwachung ermöglicht eine rechtzeitige Identifizierung, Intervention und Korrektur von Leistungsproblemen, bevor sie sich auf die Endnutzer auswirken.
Mehrere Datenpunkte werden von einem LLM-Überwachungssystem erfasst:
- Eingabeaufforderungen
- Aufforderungs-Token/Länge
- Abschlüsse
- Vervollständigungs-Token/Länge
- Eindeutiger Bezeichner für die Konversation
- Latenzzeit
- Schritt in der LLM-Kette
- Benutzerdefinierte Metadaten
Ein gut strukturiertes Beobachtungssystem, das Prompt-Completion-Paare konsistent verfolgt, kann genau feststellen, wann sich Änderungen, wie z. B. ein erneutes Training oder eine Verschiebung der Basismodelle, auf die Leistung auswirken.
Es ist auch wichtig, die Modelle auf Drift und Verzerrungen zu überwachen. Während die Drift bei herkömmlichen maschinellen Lernmodellen ein weit verbreitetes Problem ist, ist die Überwachung bei LLMs aufgrund ihrer Abhängigkeit von den Basismodellen noch wichtiger.
Verzerrungen können von den anfänglichen Datensätzen herrühren, auf denen das Basismodell trainiert wurde, von den eigenen Datensätzen, die für die Feinabstimmung verwendet werden, oder sogar von den menschlichen Bewertern, die die prompten Abschlüsse bewerten. Um Verzerrungen wirksam zu bekämpfen, ist ein gründliches Bewertungs- und Überwachungssystem unerlässlich.
Welche Herausforderungen löst LLMOps konkret?
LLMOps stellt sich einigen Herausforderungen, die über die traditionellen MLOps-Anforderungen hinausgehen. Die Schlüsselaspekte, die LLMOps von Machine-Learning-Operations unterscheiden, sind:
- Datenverarbeitungsressourcen: LLMs erfordern erheblich umfangreichere Berechnungen mit großen Datenmengen für Training und Feinabstimmung. Spezielle Hardware wie GPUs wird benötigt, um diesen Prozess zu beschleunigen. Der Zugang zu diesen Ressourcen ist für das Training und die Implementierung von LLMs entscheidend.
- Komplexität des Entwicklungszyklus: Die Entwicklung eines LLM in einem kommerziellen Produkt umfasst viele Teilschritte, darunter Datenerfassung, Datenaufbereitung, Prompt Engineering, Modelloptimierung und -implementierung sowie Modellüberwachung. Diese Prozesse erfordern eine rigorose operative Disziplin und teamübergreifende Zusammenarbeit.
- Skalierbarkeit und Risikomanagement: LLMOps bietet Lösungen für Skalierbarkeit und Management von Tausenden von CI/CD-Modellen. Es sorgt auch für mehr Transparenz und Compliance, was besonders wichtig ist, da LLMs oft behördlichen Prüfungen unterliegen.
- Modellbereitstellung und -überwachung: LLMOps umfasst die gesamte Bandbreite von Machine-Learning-Projekten, von der Datenaufbereitung bis zur Pipeline-Erstellung. Es beinhaltet auch kritische Prozesse wie Modellprüfung, Governance, Inferenz, Bereitstellung und Überwachung mit menschlichem Feedback.
Diese Herausforderungen zeigen die Notwendigkeit eines spezialisierten LLMOps-Ansatzes auf, der über die üblichen MLOps-Praktiken hinausgeht. Der Erfolg von LLMOps hängt von der effektiven Bewältigung dieser Herausforderungen ab, um die Vorteile von LLMs in kommerziellen Anwendungen vollständig zu nutzen.
Wo könnten KI-Agenten bei Ihnen den größten Unterschied machen?
Das finden wir gemeinsam heraus
In der folgenden Tabelle führen wir einzelne Herausforderungen auf, und wie diese durch LLMOps gelöst werden.
| Herausforderung | Lösung durch LLMOps |
| 1. Prompt Engineering | Prompt Engineering ist eine Schlüsselkomponente von LLMOps. Es befasst sich mit der Gestaltung von Eingabeaufforderungen, die LLMs anregen, die gewünschten Antworten zu generieren. |
| 2. Nutzung unternehmensinterner Daten | In LLMOps ist die Integration von firmeneigenen Daten in das Training von LLMs von großer Bedeutung, um maßgeschneiderte Lösungen zu schaffen. |
| 3. Retrieval Augmented Generation (RAG) | RAG ist ein innovativer Ansatz, der externe Informationen zur Verbesserung der Genauigkeit und Relevanz von Modellantworten nutzt. |
| 4. Vector-Databases | Vektordatenbanken sind zentral für die Effizienz von RAG-Workflows, indem sie eine schnelle und genaue Suche nach relevanten Informationen ermöglichen. |
| 5. Fine-Tuning und Pre-Training von LLMs | Das Feinabstimmen und Vorabtrainieren sind wesentliche Aspekte von LLMOps, um die Modelle an spezifische Bedürfnisse anzupassen. |
| 6. Modellbewertung und Feedback | Die Bewertung der Modellleistung und die Integration menschlichen Feedbacks sind entscheidend, um die Qualität der Modellantworten zu sichern. |
| 7. Inferenz mit Großen Modellen | Die Inferenz, insbesondere mit großen Modellen, ist eine Herausforderung, die ein Gleichgewicht zwischen Kosten und Leistung erfordert. |
Was sind wesentliche Komponenten von LLMOps?
LLMOps setzt sich aus verschiedenen Schlüsselkomponenten zusammen, die für das effektive Management und die Implementierung von Large Language Models (LLMs) erforderlich sind. Dazu gehören die explorative Datenanalyse (EDA), welche die Grundlage für das Verständnis und die Aufbereitung der benötigten Daten bildet. Die Datenaufbereitung und das Prompt Engineering sind entscheidend für die Qualität und Effektivität der Modelle. Weitere wichtige Komponenten sind die Modelloptimierung, die auf Leistungssteigerung und Effizienz abzielt, sowie die Modellprüfung und Governance, die für die Einhaltung von Standards und Richtlinien sorgen.
Sehen wir uns nun die einzelnen Komponenten des LLMOps an
Explorative Datenanalyse: (EDA) ist ein Prozess in der Datenanalyse, der darauf abzielt, ein besseres Verständnis von Daten zu gewinnen, indem Daten visuell untersucht und Muster, Trends, Abweichungen und Beziehungen zwischen den Daten identifiziert werden. Im Kontext von LLMOps (Machine Learning Operations für große Sprachmodelle), insbesondere im Bereich der Generativen KI und Natural Language Processing (NLP), kann EDA verwendet werden, um die Daten zu verstehen, die mit LLMs in Verbindung stehen.
Prompt Engineering: bezieht sich auf die Praxis, Texteingaben für ein LLM anzupassen, um genauere oder relevantere Antworten zu erhalten. Obwohl es sich um ein aufstrebendes Gebiet handelt, entwickeln sich einige bewährte Verfahren. In diesem Abschnitt werden Tipps und bewährte Praktiken diskutiert, sowie auf nützliche Ressourcen verlinkt.
Modelloptimierung: in LLMOps (Machine Learning Operations für große Sprachmodelle) bezieht sich auf den Prozess der Verbesserung und Anpassung von großen Sprachmodellen (LLMs), um ihre Leistung zu optimieren und effizienter zu gestalten. Dieser Prozess kann verschiedene Aspekte umfassen, um die Gesamtleistung und Effizienz der LLMs zu steigern.
Modellprüfung: (auch als Modellvalidierung oder Modellevaluation bezeichnet) ist ein entscheidender Schritt in LLMOps (Machine Learning Operations für große Sprachmodelle) und im gesamten Lebenszyklus von Machine-Learning-Modellen. Sie bezieht sich auf den Prozess, bei dem die Leistung eines großen Sprachmodells (LLM) in Bezug auf bestimmte Aufgaben, Daten und Metriken bewertet wird, um sicherzustellen, dass es in Produktionsumgebungen effektiv und zuverlässig arbeitet.
Zudem spielen Modellinferenz und -bereitstellung eine Rolle, um die Modelle effektiv in die bestehenden Systeme zu integrieren. Abschließend ist die Modellüberwachung mit menschlichem Feedback unerlässlich, um die Leistung kontinuierlich zu bewerten und anzupassen. Jede dieser Komponenten trägt dazu bei, dass LLMOps den komplexen Anforderungen von LLMs gerecht wird und deren Potenzial voll ausgeschöpft werden kann.
Use Case: Implementierung von LLMOps für ein Kundenservicezentrum
Gemeinsam mit unserem Kunden – ein großes Telekommunikationsunternehmen – implementierten wir ein LLMOps-System. Das Ziel war es, die Kundenservice-Effizienz langfristig zu steigern. Sie beschlossen, zu diesem Zweck ein Large Language Model (LLM) zu implementieren, um häufig gestellte Kundenfragen automatisch zu beantworten.
Herausforderung:
Das Unternehmen stand vor der Herausforderung, das LLM so zu konfigurieren, dass es präzise und hilfreiche Antworten liefert, während es sich an die sich ändernden Kundenanfragen und -bedürfnisse anpasst. Sie benötigten eine Lösung, die es ermöglicht, das Modell kontinuierlich zu überwachen, zu aktualisieren und zu optimieren.
Lösung: Implementierung von LLMOps
Damit das LLM die Kundenanfragen zuverlässig mit aktuellen Daten beantwortet, implementierten wir auf der Databricks Plattform LLMOps. Unsere Vorgehensweise sah wie folgt aus:
- Prompt Engineering: Zunächst setzten wir ein Team von Experten ein, um effektive Prompts für das LLM zu entwickeln. Diese Prompts sind darauf ausgerichtet, genaue und relevante Antworten auf häufig gestellte Kundenanfragen zu generieren.
- Modellüberwachung und Anpassung: Durch die Nutzung von LLMOps-Tools wird das Modell kontinuierlich überwacht. Kundeninteraktionen werden analysiert, um die Leistung des LLMs zu bewerten und Bereiche für Verbesserungen zu identifizieren.
- Feinabstimmung und Iteration: Basierend auf dem Feedback und den Leistungsdaten wird das LLM regelmäßig feinabgestimmt. Dies umfasst die Anpassung der Prompts und eventuell das Training des Modells mit zusätzlichen Daten.
- Integration in die bestehende Infrastruktur: Das LLM wird nahtlos in die bestehende Kundenbetreuungsinfrastruktur integriert, um Echtzeit-Support für Kundenanfragen zu ermöglichen.
Ergebnis:
Durch die Implementierung von LLMOps konnte das Kundenservicezentrum die Effizienz und Qualität seines Kundenservice steigern. Die Kunden erhalten schnelle und genaue Antworten, und das Support-Team kann sich auf komplexere Anfragen konzentrieren. Darüber hinaus ermöglicht die kontinuierliche Überwachung und Anpassung des LLMs eine dynamische Anpassung an sich ändernde Kundenbedürfnisse und Verbesserungen im Zeitverlauf.
Was sind Best Practices für LLMOps?
Für eine erfolgreiche Umsetzung von LLMOps ist es wichtig, bewährte Methoden und Strategien zu befolgen. Zu den Best Practices gehört zunächst eine gründliche explorative Datenanalyse (EDA), um die Grundlagen für datengetriebene Entscheidungen zu schaffen. Datenaufbereitung und Prompt Engineering sind entscheidend, um die Datenqualität zu sichern und effektive Modellinteraktionen zu ermöglichen. Modelloptimierung unter Verwendung von leistungsstarken Open-Source-Bibliotheken wie Hugging Face Transformers hilft, die beste Performance zu erzielen.
Bei der Modellprüfung und Governance ist es wichtig, Transparenz und Compliance sicherzustellen, insbesondere im Hinblick auf Datenschutz und ethische Standards. Für die Modellinferenz und -bereitstellung sollten agile Methoden und CI/CD-Prinzipien angewandt werden, um schnelle und effiziente Deployments zu ermöglichen. Abschließend ist eine kontinuierliche Modellüberwachung mit menschlichem Feedback unerlässlich, um die Modelle ständig zu verbessern und an neue Anforderungen anzupassen. Diese Best Practices bilden das Fundament für ein robustes und effizientes LLMOps-System, das die Vorteile von LLMs maximiert und gleichzeitig Risiken minimiert.
Fazit
LLMOps stellt einen wesentlichen Fortschritt in der Handhabung und Nutzung von Großen Sprachmodellen (LLMs) dar. Es vereint die effiziente Nutzung von Ressourcen, innovative Datenaufbereitung und fortgeschrittene Modelloptimierung, um die Potenziale der LLMs voll auszuschöpfen. Die Implementierung von Best Practices in LLMOps ermöglicht es Unternehmen, die Vorteile dieser fortschrittlichen Technologien zu nutzen, während sie gleichzeitig Herausforderungen wie Skalierbarkeit, Datenqualität und Compliance meistern. In einer zunehmend datengetriebenen Welt ist LLMOps somit ein entscheidender Faktor für den Erfolg im Bereich der künstlichen Intelligenz und maschinellen Lernens.
Sie möchten ihr Large-Language-Modell-Operations-Management optimieren? Dann kontaktieren Sie uns.
FAQ – Die wichtigsten Fragen schnell beantwortet
LLMOps steht für Large Language Model Operations und bezieht sich auf die Praktiken, Verfahren und Tools, die für das Management von Großen Sprachmodellen (LLMs) in Produktionsumgebungen notwendig sind.
LLMOps ist speziell auf die einzigartigen Herausforderungen von LLMs ausgerichtet, wie etwa umfangreichere Datenverarbeitung und spezifische Anforderungen an die Modellüberwachung und -wartung.
Zu den Best Practices gehören explorative Datenanalyse, effiziente Datenaufbereitung, Prompt Engineering, Modelloptimierung, Modellprüfung und Governance, sowie kontinuierliche Modellüberwachung mit menschlichem Feedback.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte





