


Big Data ist ein wichtiger Business-Trend und schafft für viele Unternehmen enormen Mehrwert. Big Data ermöglicht die Speicherung, Verarbeitung und Analyse großer Datenmengen. Spezielle Technologien ermöglichen die Verarbeitung von Datenmengen, die relationale Datenbanken nicht verarbeiten können.
In diesem Artikel gehe ich auf die Grundlagen von Big Data ein.
Was ist mit Big Data gemeint?
Unter Big Data versteht man die Speicherung, Verarbeitung und Analyse großer Datenmengen. Diese Datenmengen sind so groß, dass sie mit herkömmlicher Hard- und Software nicht mehr verarbeitet werden können und daher spezielle Big-Data-Hard- und Software benötigt wird.
Big Data löst diese Probleme durch spezielle Hard- und Software, die verteilt, d.h. in einem Verbund von vielen Rechnern (Clustern) arbeitet. In Big-Data-Systemen werden die Daten also nicht mehr auf einem Server gespeichert, sondern auf viele Rechner verteilt, die miteinander kommunizieren können. Durch den Zusammenschluss wird es möglich, riesige Datenmengen zu speichern und zu verarbeiten.
Bekannte Software (Big-Data-Systeme) für die Verarbeitung großer Datenmengen sind beispielsweise Apache Hadoop und Apache Spark.
Big Data Definition
Es gibt viele Definitionen von Big Data, da es viele verschiedene Konzepte umfasst. Wenn man den Begriff bei Google eingibt, erhält man folgende Definition von Big Data:
- große Datenmengen – „Big Data analysieren“
- Technologien zur Verarbeitung und Auswertung großer Datenmengen – „Big Data nutzen“.
Oft sammeln sich in Unternehmen über Jahre hinweg große Datenmengen und hochinteressante Datenquellen an, die mit Big Data Analytics und Machine Learning einen entscheidenden Mehrwert bringen. Ob aus Web-, Sensor- oder unstrukturierten Datenquellen, die Größe wächst stetig, der Nutzwert pro Gigabyte ist jedoch relativ gering. Das bedeutet, dass die intelligente Analyse entscheidend ist, um einen Mehrwert zu erzielen.
Der zweite wichtige Aspekt ist die Big-Data-Technologie, die sich in ihrer Struktur und Funktionalität grundlegend von klassischen Technologien wie relationalen Datenbanken unterscheidet.
Big Data Technologie (Apache Spark oder Hadoop) ermöglicht nicht nur die Analyse von großen Datenmengen, sondern schafft auch Möglichkeiten viele unterschiedliche Datenformate (z.B. semi- oder unstrukturierte Daten wie Texte, Bilder und Videos) oder Daten in viel höherer Geschwindigkeit zu verarbeiten.
Ein letzter Aspekt den ich einbringen möchte, ist die Art und Weise wie man über Daten als Wettbewerbsfaktor denkt, denn heute werden ganze Geschäftsmodelle rein auf Big Data aufgebaut.
Warum ist Big Data so wichtig?
Durch die zunehmende Vernetzung unseres Lebens entstehen an vielen Stellen neue Datenpunkte, die gespeichert werden müssen. Jeder Einkauf, jeder Besuch auf einer Social-Media-Plattform oder jeder Prozess in einer Produktionsstraße hinterlässt eine Vielzahl von Daten.
Mit Datasolut zur passenden Datenplattform.
Mit unserem Datenplattform-Workshop finden wir die perfekte Plattform für Ihre Anwendungsfälle.
Big Data Systeme können all diese Daten aufnehmen und verarbeiten. Unternehmen haben dadruch viele Möglichkeiten diese Daten zu wertvollen Informationen umzuwandeln und zur Optimierung von Prozessen einzusetzen. Folgend Beispiele wofür Big Data genutzt wird:
- Digitale Assistenten werden mit einer Fülle von Sprachdaten gefüttert, damit sie unsere Sprache verstehen.
- Unternehmen können anhand der hinterlassenen Daten ihren Kunden gezieltere Angebote machen, sie noch besser ansprechen und sogar den Preis von Produkten personalisieren.
- In der Medizin werden Bilder genutzt, um zum Beispiel die Erkennung von Krankheiten wie Krebs zu verbessern.
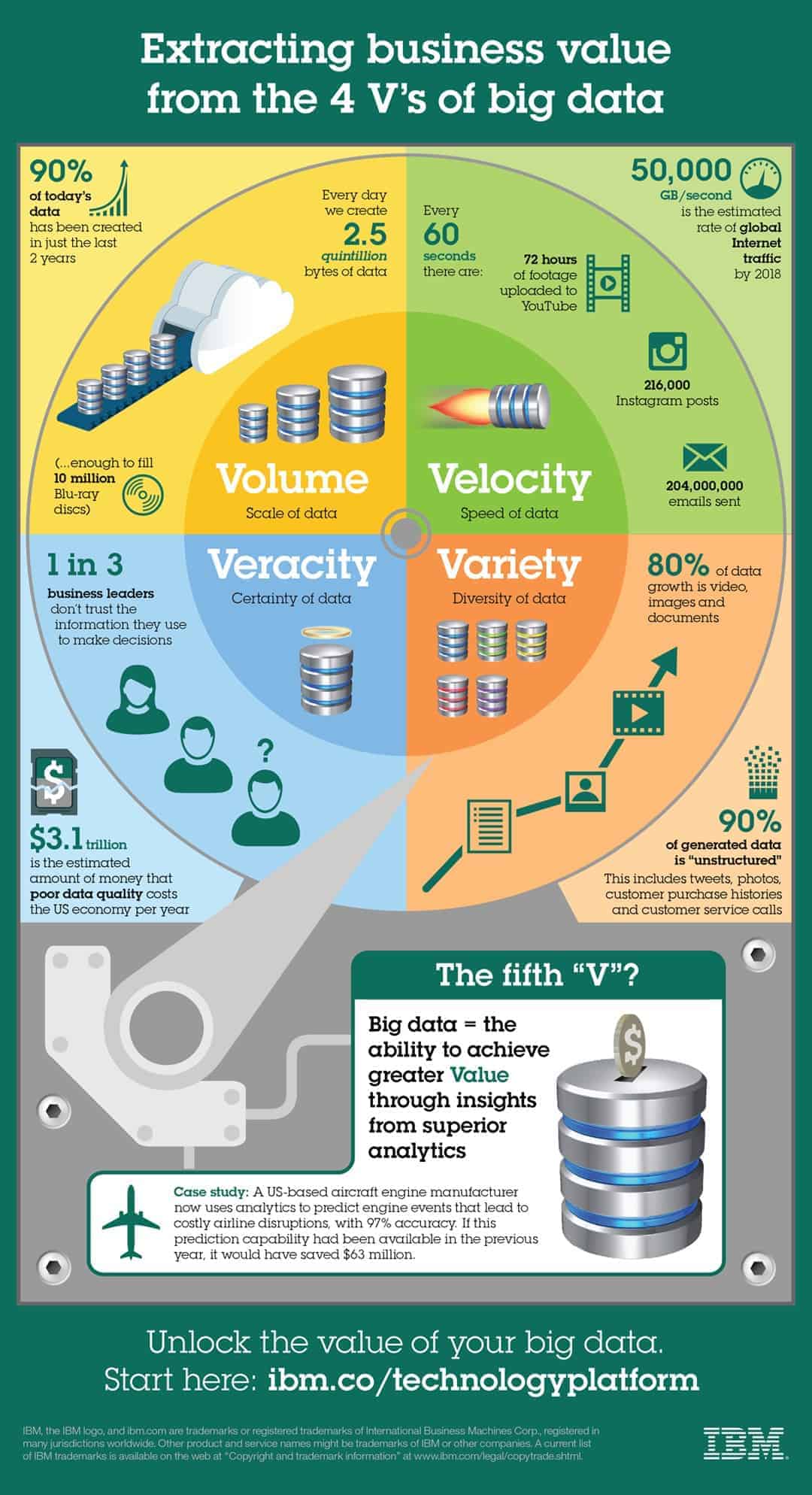
Die 4 Big Data V’s: Volume, Variety, Velocity, Veracity
Ursprünglich hat Gartner Big Data Konzept anhand von 4 V’s beschrieben, aber mittlerweile gibt es Definitionen, die diese um 1 weiteres V erweitert.
4 Big Data V
- Volume, beschreibt die extreme Datenmenge. Immer größere Datenmengen sind zu speichern und verarbeiten. Laut Statista 2017 verzehnfacht sich das weltweit jährlich produzierte Datenvolumen bis 2025 auf 163 Zettabyte.
- Variety, beschreibt die Vielfalt der unterschiedlichste Dateistrukturen: strukturiert, semi-strukturiert und unstrukturiert. All die unstrukturierten Daten sind in relationalen Datenbanken oft gar nicht auszuwerten, dennoch tragen sie sehr wertvolle Informationen. Rund 90% der gespeicherten Daten sind in unstrukturierten Formaten wie Texten, Bildern oder Videos gespeichert. Durch Big Data werden diese Daten anhand von Machine Learning analysierbar.
- Velocity, beschreibt die erhöhte Geschwindigkeit mit der die Daten produziert, aber gleichzeitig auch verarbeitet werden müssen. Heute spielt für viele Unternehmen und Use Cases die Echtzeitverarbeitung eine große Rolle und kann für den entscheidenden Wettbewerbsvorteil sorgen.
- Veracity, die Unsicherheit (Wahrhaftigkeit) der Daten und Datenqualität. Daten kommen aus verschiedenen Quellen teilweise nicht in der gewünschten Qualität an und können daher nicht wie gewollt eingesetzt werden oder müssen aufwendig nachbereitet werden.
Erweiterung um zwei weitere Vs
- Value, der Mehrwert oder Business Value, der durch die großen (verknüpften) Datenmengen erzeugt wird und natürlich durch den Einsatz von Machine Learning Techniken auf diese riesigen Datenmengen. Sicherlich eins der wichtigsten V für die Argumentation von Big Data, denn ohne Value gäbe es keinen Grund für diese Vorhaben.
- Validity, die Qualität der Daten, denn ohne qualitativ hochwertige Daten ist es für Unternehmen unmöglich einen Mehrwert mit ihren Daten zu erzielen. Daten von minderwertiger Qualität können die Prognose Ergebnisse von Machine Learning Modellen negativ beeinflussen und im schlimmsten Fall zu fehlerhaften Vorhersagen führen.
IBM hat für die 4 + 1 Vs (Volume, Variety, Velocity, Veracity, Value) von Big Data eine sehr schöne Infografik erstellt:
Die Geschichte von Big Data
Big Data ist nicht neu. Die ersten Schritte machten wir schon in den 1960er und 1970er Jahren mit den ersten Datenzentren und relationalen Datenbanken.
Um 2005 explodierte die Datenmenge durch Plattformen wie Facebook, Instagram und YouTube. Genau zu dieser Zeit entstand Hadoop, ein Framework für die Auswertung riesiger Datenmengen.
Spätestens mit neuen Technologien wie Hadoop und später Spark wurde die Verarbeitung von Big Data einfacher und kosteneffizienter. Bis heute wachsen die Datenmengen rasant, nicht nur durch Menschen, sondern auch durch vernetzte Geräte (IoT) sowie Apps, Webseiten und innerhalb von Produkten. Machine Learning und GenerativeAI treiben die Datenerzeugung aktuell stark vor ran.
Während Big Data technologisch weit entwickelt ist, steckt die Nutzung und Wertschöpfung dieser Daten noch in den Kinderschuhen. Cloud Computing vereinfacht die Umsetzung von Big Data durch einfache Skalierbarkeit und kostengünstige Speicher- (S3, Azure Blob Storage) und Rechenressourcen.
In der Zusammenarbeit mit unseren Kunden erfahren wir täglich, wie groß das Potenzial von Big Data sein kann, wenn die richtigen Analysewerkzeuge und -kompetenzen eingesetzt und nahtlos in die Geschäftsprozesse integriert werden.
Was ist Big Data Analytics?
Big Data Analytics ist ein Begriff, der viele verschiedene Analysen und Methoden vereint. Ich bin der Meinung grundsätzlich kann man den Begriff in zwei Kategorien unterteilen:
- Analytics, umfasst vor allem die Aufgabenbereiche Analysen, Reporting und Visualisierung. Hier werden die Daten so aufbereitet, das Entscheidungen auf Basis dieser Aufbereitung getroffen werden können.
- Machine Learning, beschreibt das maschinelle Lernen von Systemen, die durch anhand von Daten lernen und dadurch den Entscheidungsprozess unterstützen. Ein Machine Learning Modell findet Einsatz für die Vorhersage von Ereignissen zur Verbesserung von Geschäftsprozessen oder ermittelt eine relevante Produktempfehlung für Kunden. Auch der große Deep Learning Trend ist hier einzuordnen.
All die oben genannten Themen sind nichts neues und werden täglich in Unternehmen umgesetzt. Der Unterschied zwischen Analytics und Big Data Analytics:
- Verarbeitung enormer Datenmengen
- schneller und flexibler Import und Export von Daten
- Datenaktualität – Realtime
- schnelle Verarbeitung der Daten
- bessere Integration von Machine Learning Einsatz
- Trennung von ML und ETL nicht mehr so stark – Daten sind oft im den gleichen Systemen vorhanden
- ML-Scorings im Streaming Kontext

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Big Data Technologie
Am Markt gibt es viele eine Vielzahl von Big Data Technologien, so fällt es schwer den Überblick zu behalten. Aus meiner Praxiserfahrung kann ich sagen, dass es eigentlich nur eine Handvoll relevante Technologien gibt auf die man sich konzentrieren muss.
Big Data Technologien wie Apache Hadoop, Apache Spark und Apache Kafka entwickeln sich rasant weiter.
Apache Hadoop
Mit Apache Hadoop ist der Grundstein der Big Data Technologie gelegt worden. Das in Java geschriebene, verteile System lässt sich einfach skalieren und ist für große Datenmengen entwickelt. Der von Google Inc. entwickelte MapReduce-Algorithmus ist das Herzstück des Systems und ermöglicht die parallele Datenverarbeitung auf massiven Clustern.
Eine Einführung von uns zu Apache Hadoop findet ihr hier!
In der Praxis wird Hadoop oft als System zur Datenhaltung und für die Entwicklung von ETL-Prozessen eingesetzt. Hadoop bietet leider keine direkte Möglichkeit Machine Learning anzuwenden.
Apache Spark
Apache Spark ist im Jahr 2012 entstanden und entwickelt um die Nachteile des Hadoop MapReduce-Algorithmus auszubessern. Spark verarbeitetet, anders als Hadoop, die Datenmengen im Arbeitsspeicher und ist so viel Leistungsfähiger was die Berechnung angeht.
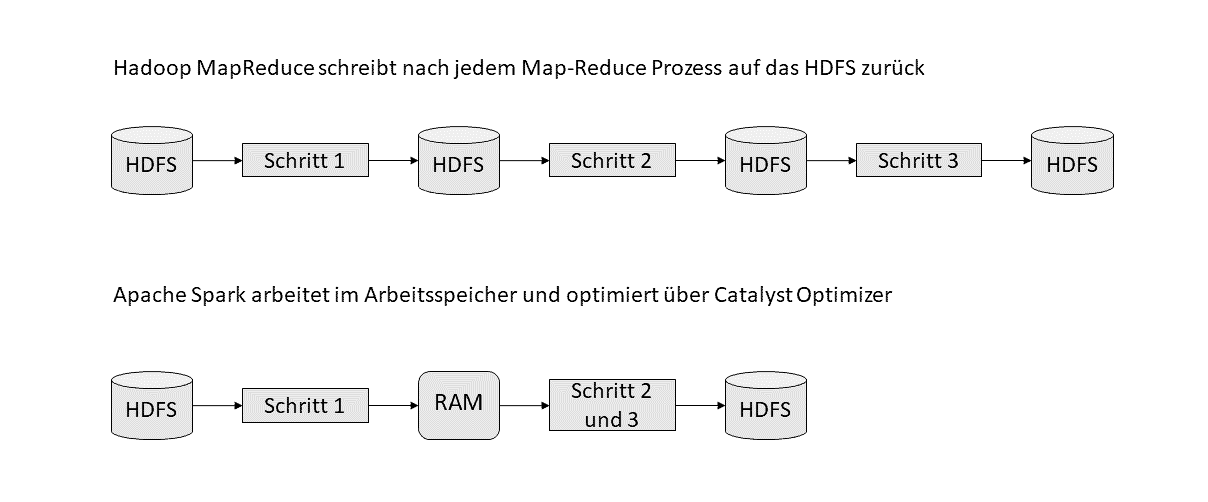
In der Praxis wird es oft für ETL-Prozesse sowie die Entwicklung und Integration von Machine Learning Algorithmen eingesetzt, aber auch die Realtime-Verarbeitung ist mit Structured Streaming in Spark möglich.
Spark ist sicher eines der interessantesten Open Source Projekte auf dem Markt. Hier erfährst du mehr in meinem Artikel zu: Was ist Apache Spark?
Apache Kafka
Apache Kafka ist ebenfalls ein Open Source Projekt der Apache Foundation und wurde bei LinkedIn entwickelt. Mit dem Fokus auf der verteilten Verarbeitung von Datenströmen hat Kafka eine andere Funktion als z.B. Hadoop oder Spark.
Kafka speichert und verarbeitet Datenströme und stellt ein API zum Laden und Exportieren von Datenströmen für andere Systeme bereit. So sind Hadoop und Spark oft Abnehmer von den Datenströmen von Kafka.
Mit Kafka können coole Streaming Use Cases umgesetzt werden, oft kommt Kafka für den Einsatz für das Streaming von Webtrackingdaten zum Einsatz und unterstützt Marketingprozesse im Webshop.
Apache Cassandra
Ist ein verteiltes Datenbanksystem, was für sehr große strukturierte Datensätze ausgelegt ist. Besonders die Robustheit und gute Skalierbarkeit sind die Stärken des spaltenorientierten Systems.
Apache Cassandra zählt zu den NoSQL-Datenbanksystemen und wird ebenfalls als Open Source Projekt von der Apache Foundation veröffentlicht. Das Konzept der Schlüssel-Wert-Relation spielt eine große Rolle, was zu schnellen Abfragegeschwindigkeiten führt.
Cassandra wird von großen Unternehmen wie Uber als ML Feature Store eingesetzt. Eine vergleichbare Datenbank ist die Dynamo DB auf Amazon AWS.

Ihr nächster Schritt mit uns!
Wenn Sie gerade prüfen, wie KI in Ihrer Organisation sinnvoll eingesetzt werden kann, ist ein unverbindliches Orientierungsgespräch der beste erste Schritt. In wenigen Minuten klären wir:
- wo Sie gerade stehen
- welche Erwartungen realistisch sind
- ob unser KI-Workshop sinnvoll für Sie ist







