


Apache Spark ist eine einheitliche In-Memory Analytics Plattform für Big Data Verarbeitung, Data Streaming, SQL, Machine Learning und Graph Verarbeitung.
Apache Spark ist das spannendste und innovativste Big Data System was es zurzeit am Big Data Markt gibt. Das von der Apache Foundation seit 2014 als Top-Level-Projekt klassifizierte Open Source Projekt entstand an der University of California, Berkeley’s im AMPLab und ist seitdem nicht mehr von der Big Data-Landkarte wegzudenken.
Apache Spark hat sich wirklich zur besten Big Data Technologie entwickelt. In unseren Kundenprojekten setzen wir für große Datapipelines auf Apache Spark. Allerdings ist das Anlegen von robusten ETL-Prozessen in Apache Spark nicht immer ganz einfach. Falls Sie dazu Fragen haben, sprechen Sie uns einfach an.
Was ist Apache Spark?
Apache Spark ist ein einheitliches In-Memory Big Data System, was für die Verarbeitung von enormen Datenmengen geeignet ist.
Durch die verteilte Architektur in einem Cluster kann Apache Spark extrem große Datenmengen performant und parallel verarbeiten. Apache Spark verarbeitet die Daten im Arbeitsspeicher und versucht das Schreiben auf eine Festplatte zu vermeiden.
Die gute Integration von vielen Machine Learning, ermöglicht analytische Modelle auf Big Data mit Apache Spark anzuwenden. Deshalb wird das System oft als Schweizer Taschenmesser der Big Data Datenverarbeitung bezeichnet.
Die Schwächen von Apache Hadoop Map Reduce zu eliminieren war die Motivation von den Erfindern aus dem AMPLab. Basierend auf dem Konzept der Resilient Distributed Datasets (RDD), eine auf den Clustern verteilte, nicht veränderbare und fehlertolerante Dateneinheit, ist Spark aufgebaut.
Heute nutzen viele Anwender Spark DataFrames, die seit Spark Version 2 in Scala, Python und Java integriert sind. Spark DataFrames, vergleichbar mit R DataFrames oder Pandas DataFrames, ermöglichen das Abfragen von Daten in einer Tabellenstruktur.
Unser kurzes YouTube Video ordnet das Thema ein und gibt einen kurzen Überblick über Apache Spark.
Hier ein einfaches Beispiel für das Einlesen von einer CSV-Datei in Spark (Scala):
val diamonds = sqlContext.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/path-to-datasets/diamonds.csv")
Nun zu den grundlegenden Komponenten von Spark…
Komponenten von Spark (Spark Core)
Das Apache Spark Framework besteht aus diesen Komponenten: Spark SQL, Streaming, maschinelles Lernen und Graphverarbeitung:
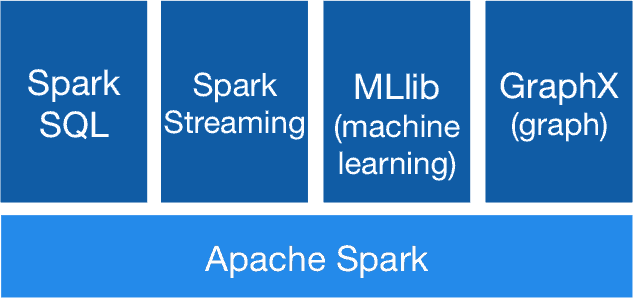
Spark Core
Der Spark Core ist die Basis des Spark-Systems, in dem die fundamentalen Funktionalitäten von Spark zusammengefasst sind. Hier werden Ein- und Ausgabe, das Verteilen von Jobs und das Scheduling gesteuert.
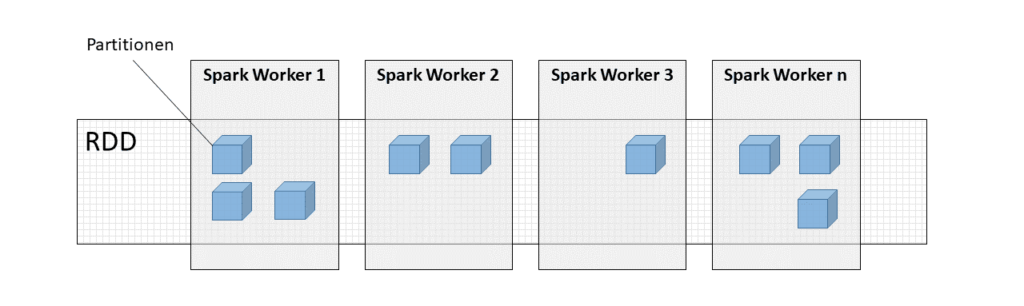
Apache Spark RDD
Die in Spark grundlegende Datenstruktur basiert auf RDDs (Resilient Distributed Datasets), dies ist ein Konzept um Daten über mehrere Rechner zu verteilen und diese parallel zu verarbeiten. Spark DataFrames basieren auf RDDs und enthalten wertvolle Metainformationen, so dass die Daten einfacher zu analysieren sind. Auf RDDs und DataFrames können aus einer externen Hadoop Datenquelle erstellt werden oder aus internen Prozessschritten entstehen.
Was ist ein Resilient Distributed Dataset (RDD?
Resilient Distributed Datasets (RDD) bedeutet:
- Resilient, Fehler-tolerant, sodass verhehlende oder kaputte Partitionen auf geschädigten Spark Workern wiederhergestellt werden können.
- Distributed, die Daten sind in Partitionen über verschiedene Rechner in einem Cluster verteilt.
- Dataset, ist eine Sammlung von partitionierten Daten ohne Typisierung.
Zusammengefasst sind Spark RDDs:
- Die Primäre Abstraktion von Daten in Apache Spark und Hauptbestandteil des Spark Core
- RDDs sind verteilte Dateneinheiten, die über eine oder mehrere Partitionen aufgeteilt sind
- Alle Operationen werden auf den RDDs parallel ausgeführt!
Spark SQL
Apache Spark SQL Integriert SQL-Syntax auf Basis von Spark DataFrames und ermöglicht strukturierte Abfragen in Form von SQL-Code. Einen SQL-Befehl kann man direkt auf ein Spark DataFrame absetzen und so die vorhandenen SQL-Kenntnisse einsetzen.
Spark SQL vereinheitlicht die Zugriffsmöglichkeiten auf verschiedene Datenquellen (Avro, JSON, CSV, Parquet) und schafft Schnittstellen zu anderen Big Data Systemen, wie beispielsweise Apache Hive. Eine bestehende Datenquelle, wie ein Data Warehouse, kann man einfach über JDBC oder ODBC verbinden.

Wie die Abbildung zeigt, wird durch das Spark DataFrame die Arbeit mit den Daten deutlich einfacher. So können ganz normal über die Spalten die einzelnen Daten abgefragt werden.
Spark Structured Streaming
Ein integriertes High-Level-API stellt Spark Streaming in verschiedenen Sprachen zur Verfügung: Java, Scala und Python. Spark Streaming ermöglicht die Echtzeitverarbeitung von Streaming-Daten. Das intelligente API ermöglicht die Entwicklung im Batchbetrieb und anschließend kannst du den gleichen Code dann im Streaming-Kontext anwenden. Auch die Anwendung von zuvor trainierten Machine Learning Modellen ist im Stream möglich.

Seit der Version 2.0 ist eine Erweiterung zu Spark Streaming, was noch RDD basiert war, erschienen. Mit dem neuen Spark Structured Streaming ist die DataFrame API integriert und daher wird im Streaming Kontext die gleiche API wie im Batch genutzt.
Mit der Version 2.3, ist mit Continuous Processing, eine weitere sehr interessante Komponente für Streaming Prozesse im Latenzbereich von < 10 ms hinzugefügt worden.
Für mehr Informationen zum Thema Streaming, habe ich hier eine Zusammenfassung der wichtigstens Frameworks geschrieben.
MLlib
MLlib ist die Machine Learning Library von Apache Spark und stellt verteilte Algorithmen zur Verfügung. Gängige Algorithmen die in MLlib zu finden sind: GBT, Random Forest, K-Means Clustering.
Auch Algorithmen für Personalisierungsvorhaben wie bspw. Collaborative Filtering (ALS) sind in Spark nativ Implementiert und können sofort genutzt werden.
Mit MLlib können Sie ebenfalls auf Daten aus Hadoop als Datenquelle anwenden, somit können Sie Spark MLlib Modelle auch in bestehende Hadoop Prozesse einbinden oder sogar im Spark Streaming für Real Time Scoring eingesetzten.
GraphX
GraphX vereinheitlicht ETL, explorative Analyse und iterative Graphverarbeitung in einem System. Auch verschiedenste Algorithmen sind für die Graph DataFrames erhältlich.
Vorteile von Apache Spark
Apache Spark hat sich in der Big Data-Welt als ETL-Engine durchgesetzt und hat einige Vorteile:
Geschwindigkeit
Spark ist leicht skalierbar und arbeitet im Arbeitsspeicher, dass ermöglicht die extrem schnelle Verarbeitung von enormen Datenmengen. In einem bekannten Test hat Spark bewiesen, dass es bis zu 100 mal schneller ist als Apache Hadoop.
Einfachheit
Spark hat anwenderfreundliche Schnittstellen zu vielen Datenquellen (S3, Blog Store und JDBC etc.). Auch zur Transformation von Daten, wie in ETL-Prozessen, gibt es eine Vielzahl von wichtigen Standard-Funktionen. Das DataFrame-APIs ermöglicht die Verarbeitung von vielen Datenformaten in unterschiedlichsten Formaten.
Einheitliche Big Data Platform
Spark ist eine einheitliche Plattform für die Verarbeitung von enormen Datenmengen (Big Data). Darunter zählen SQL-Abfragen, Streaming-Daten, maschinelles Lernen, und Graph-Verarbeitung.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
Anwendungsbereiche von Apache Spark
Spark kann für viele Anwendungsbereiche und Use Cases eingesetzt werden:
- ETL-Prozesse: Durch das die vielen Schnittstellen, die Apache Spark ansprechen kann, ist das System sehr gut für große ETL-Prozesse geeignet. Durch die In-Memory-Technologie können schnell enorme Datenmengen extrahiert, transformiert und geladen werden. (hier zu meinem Artikel: ETL-Prozesse mit Apache Spark)
- Machine Learning: Spark MLlib bietet eine große Auswahl an verschiedensten Machine Learning Algorithmen an sowie einige Möglichkeiten für Deep Learning.
- Streaming: Spark Streaming ermöglicht die Verarbeitung von Daten in einem kontinuierlichen Fluss (mini Batches). So kann man beispielsweise Daten aus einem Kafka-Tonic lesen und diese in Apache Spark filtern oder als Machine Learning Features aufbereiten. (Hier klicken, wer mehr zu Streaming erfahren möchte.)
Apache Spark vs. Hadoop
Oft wird mir die Frage gestellt: Wie unterscheidet sich Spark vs. Apache Hadoop MapReduce? Grundsätzlich, wenn man diesen Vergleich macht, muss man dazu sagen, dass Systeme oft unterschiedliche Aufgaben haben.
Das Hadoop Framework an sich bietet mehr als nur eine Engine zur Datenverarbeitung. Hadoop basiert auf dem Dateisystem Hadoop Distributed File System (HDFS) und stellt damit anders als Spark ein Dateisystem zur Speicherung der Daten bereit, Spark hat eine solche Komponente nicht. Der folgende Vergleich zwischen Spark und Hadoop MapReduce bezieht sich als auf den MapReduce Algorithmus, der Abfragen und Prozesse auf Hadoop ermöglicht.
Beide basieren auf dem Konzept der Verteilung von Daten und Arbeitsschritten in einem Cluster, aber unterscheiden sich grundsätzlich in der Architektur und Möglichkeiten der Datenverarbeitung:
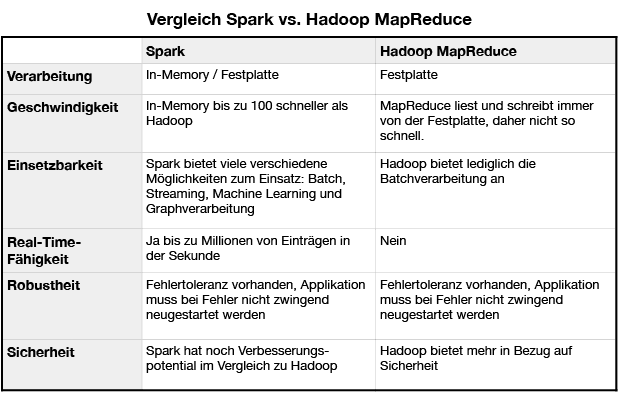
Der Vergleich zeigt, dass Spark in der Verarbeitung von Daten viele Vorteile hat, dennoch kommt das Framework Hadoop mit dem HDFS Dateisystem für die langfristige Speicherung von großen Datenmengen öfter zu Einsatz.
Mit der immer häufiger eingesetzten Cloudtechnologie von AWS wird Hadoop langsam abgelöst und durch intelligente Dienste wie Amazon S3 ersetzt. Dies kann besonders im Einsatz in der Cloud Kosten sparen, da die Cluster immer nur für einen bestimmten ETL eingesetzt werden können.
Apache Spark in der Cloud
Einsatz findet Apache Spark mittlerweile sehr häufig in der Cloud, weil die Wartung und Konfiguration eines On Premise Spark Clusters oft sehr komplex ist. On Premise werden dadurch viele menschliche Ressourcen gebunden, die im Cloudbetrieb hingegen fast komplett wegfallen.
Für den Cloudbetrieb bieten sich Cloudanbieter wie Amazon AWS oder Microsoft Azure an. Ein weiterer interessanter Anbieter ist die Firma databricks, die von den Apache Spark Erfindern gegründet wurde. Databricks stellt eine eigens entwickelte Entwicklungsumgebung im IPython Notebook-Style bereit, die auf beiden Clouds erhältlich ist. Hier ist ein großer Vorteil, dass keinerlei Cluster Installation, Konfiguration oder Wartung vom Anwender erledigt wird, sondern die Arbeitszeit effektiv in die Entwicklung von Big Data Analytics Projekten gesteckt wird.
Databricks stellt eine kostenlose Entwicklungsumgebung zur Verfügung auf der Apache Spark Applikationen programmiert und getestet werden kann. Wer Interesse hat findet hier den Link zur Community Edition.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Ein weitere interessantes Projekt von databricks in das OpenSource Analytics Tool MLflow, was dabei hilft den Machine Learning Prozess besser zu dokumentieren und reproduzierbare Ergebnisse zu erzeugen.
Was ist PySpark?
PySpark ist die Python Version von Spark und ist besonders für die erfahrenen Python-Programmierer interessant, denn die Umstellung zu PySpark ist relativ einfach. Die OpenSource Community investiert viel Zeit in die Weiterentwicklung der Python-Schnittstelle, da besonders Datenwissenschaftler viel in Python arbeiten. Wer mehr über das Thema erfahren möchte, kann sich das Projekt Koalas anschauen.
Einen Nachteil hat PySpark allerdings, es gilt als langsamer als die Scala-Version.
Voraussetzung für die Nutzung von PySpark:
– grundsätzliche Python-Kenntnisse
– Big Data Know-How und Datenbankwissen
Machine Learning mit Apache Spark
Machine Learning mit Spark ermöglicht die massive Skalierung komplexer Modelle in einem verteilten Cluster.
Apache Spark bietet inzwischen zahlreiche Methoden des maschinellen Lernens für die verteilte Verarbeitung: ML-Algorithmen, Feature Creation Tools und Pipeline-Funktionalitäten.
Durch die ausgeprägten Schnittstellen und die vielen Funktionalitäten wird Apache Spark stark im Big Data Umfeld und für Machine Learning eingesetzt. Ein Alleinstellungsmerkmal von Apache Spark ist die Möglichkeit, skalierbare ETL-Prozesse und Machine Learning in einer Systemumgebung zu realisieren, was den Vorteil hat, dass keine Daten in andere Systeme migriert werden müssen.
Was ist Apache Spark MLlib?
Spark MLlib wird genutzt um Machine Learning in Apache Spark anzuwenden. MLlib enthält viele bekannte Algorithmen und hilfreiche Funktionalitäten für Machine Learning.
Da einige Algorithmen auf einem verteilen System nicht funktionieren würden, nimmt MLlib diese Aufgabe ab und ermöglicht die Algorithmen auf einem verteilen System zu nutzen.
Spark MLlib Toolbox
Spark MLlib hat folgende Werkzeuge:
- Machine Learning Algorithmen: dazu gehören gängige Methoden wie Klassifizierung, Regression, Clustering und Empfehlungsdienste (Collaborative Filtering).
- Featurization: Machine Learning Feature Extraktion, Transformation, Dimensionsreduktion und Auswahl von ML Features.
- ML-Pipeline: eine hilfreiche Funktion um Machine Learning Modelle in einem Prozess abzuspeichern, der auch für Produktionszwecke genutzt werden kann.
- Modell und Pipeline Persistenz: Algorithmen und ML-Pipelines können in einem eigenen Format gespeichert und geladen werden.
- weitere Werkzeuge: für lineares Algebra, Statistiken und Datenverarbeitungen.
Welche Algorithmen bietet Spark für Machine Learning?
Die bekanntesten ML-Algorithmen und Werkzeuge aus Apache Spark sind:
- Klassifikation: Random Forest, Gradient Boosted Tree, einfach Entscheidungsbäume
- Regression: Regression Trees, Generalized Linear Regression, Survival Regression etc.
- Empfehlungsdienste (Recommender System): alternating least squares ALS
- Clustering: K-Means, Gaussian mixtures (GMMs) etc.
- Assoziationsanalyse: Frequent itemsets, association rules, and sequential pattern mining
- Dimensionsreduktion: PCA, SVD
- Basis Statistiken: Zusammenfassungen, Korrelationen, Sampling etc.
Unterstützt Spark Deep Learning?
Ja, Spark unterstützt auch Deep Learning. Unterstützt wird Transfer Learning, Hyperparamenter Tuning sowie das Erstellen von Deep Learning Modellen in Keras oder Tensorflow. Da das Erstellen von Deep Learning auf verteilten Infrastrukturen noch in den Anfängen steckt, gibt es hier viel Bewegung im Markt und viele Unternehmen versuchen dieses Problem zu lösen.
Eine Firma, die eine Spark basierte Lösung entwickelt, ist Logical Clocks aus Stockholm. Hier arbeitet ein geschätzter Kollege, der aktiv an der Logical Clocks Lösung Maggy arbeitet. Das Projekt zeigt vielversprechende Ergebnisse und wir können gespannt sein, was sich daraus entwickelt.
Auch die Firma Databricks arbeitet mit Hochdruck an der besseren Deep Learning Fähigkeit von Spark.
Zusammenfassung und Ausblick
Apache Spark ist eines der erfolgreichsten Big Data Systeme und wird in Zukunft noch mehr an Stellenwert gewinnen. Durch die ständige Weiterentwicklung und die motivierten Entwickler, bewegt sich das Projekt rasant vorwärts.
Die Stärken von Apache Spark sind vor allem die Vielseitigkeit in Bezug auf Datenverarbeitung in unterschiedlichen Sprachen, Data-Streaming Fähigkeit und die gute Implementierung von vielen Machine Learning Bibliotheken.
Heute ist Spark schon bei vielen großen und mittleren Unternehmen in Deutschland im Einsatz, die abnehmende Skepsis in Bezug auf Cloudtechnologie wird dies noch verstärken und zum Wachstum beitragen.
Wer mehr zu Apache Spark erfahren möchte, dem kann ich folgende Bücher empfehlen: „Spark: The Definitive Guide – Big Data Processing Made Simple“ und „Learning Spark“, beide Bücher sind vom Erfinder von Spark, Matei Zaharia, geschrieben.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte










