


Ein Machine Learning Feature Store ist ein zentraler Datenspeicher speziell für Data Science Prozesse. Die Datenzugriffs- und verarbeitungsschicht unterstützt Projekte und Anwendungen des maschinellen Lernens und steigert so Effizienz und Skalierbarkeit.
In diesem Beitrag erklären wir, was genau hinter dem Feature Store steckt, welche Vorteile dieser bringt, wie er verwendet wird und vieles mehr.
Was ist ein Feature Store?
Ein Machine Learning Feature Store ist ein zentraler Datenspeicher, der speziell für den Data Science Prozess aufbereitete Daten und Features (Attribute und Merkmale) verwaltet. Ein ML Feature Store ist als „single source of truth“ ein wichtiger Bestandteil einer Data Science Plattform und Grundlage für alle Machine Learning Projekte Ihres Unternehmens.
Was sind Features
Beim maschinellen Lernen sind Features Daten, die als Eingabe für ML-Modelle verwendet werden, um Vorhersagen zu treffen. Rohdaten liegen nur selten in einem Format vor, das von einem ML-Modell verwendet werden kann, daher müssen sie in Merkmale (Features) umgewandelt werden. Dieser Prozess wird als Feature Engineering bezeichnet. Ein Feature ist somit eine unabhängige Variable, speziell entwickelt für das Training eines ML-Modells.
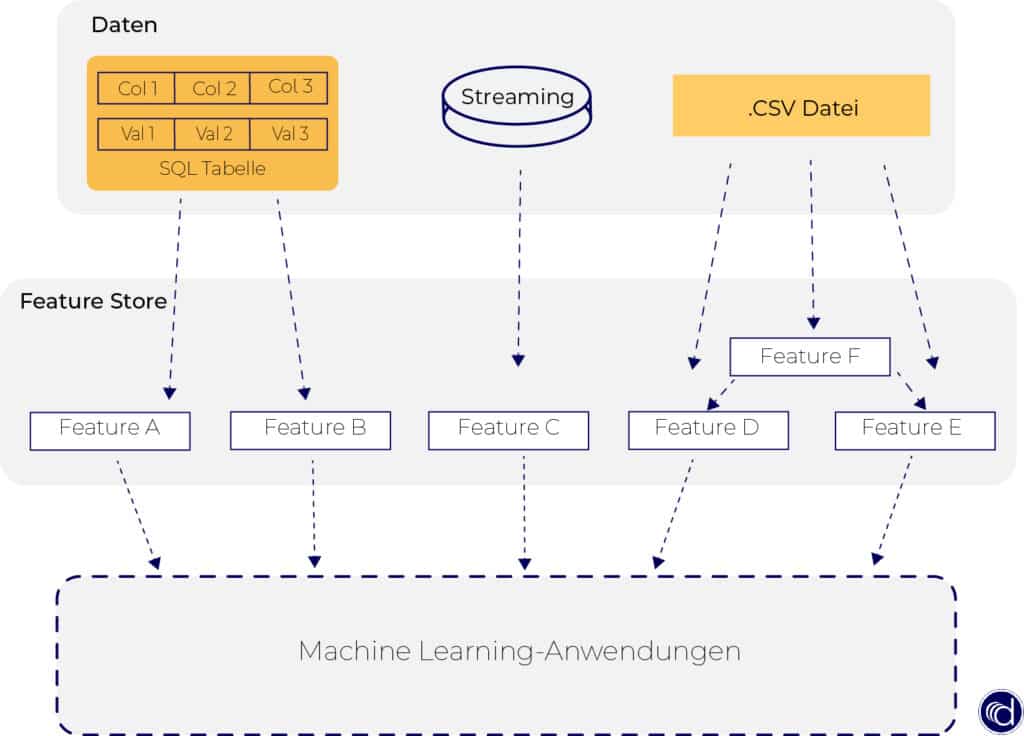
Damit Sie sich den Einfluss des Features Stores auf die Datenverwaltung besser vorstellen können, stellen wir Ihnen folgend zwei Grafiken vor.
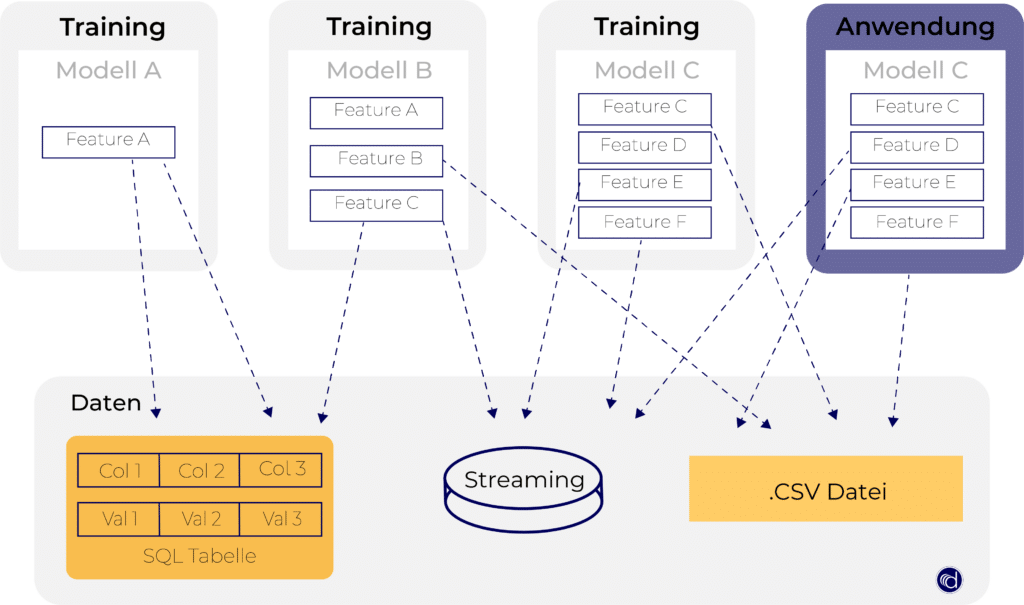
Die Datenverarbeitung ohne Feature Store ist durch das durch Hin- und Herschieben von Daten in Tabellen sehr aufwendig (s. Abbildung oben). Mit dem Feature Store (Abbildung unten) können Daten an einen einheitlichen Ort geladen werden und sind dort jederzeit für Machine Learning-Anwendungen abrufbereit.
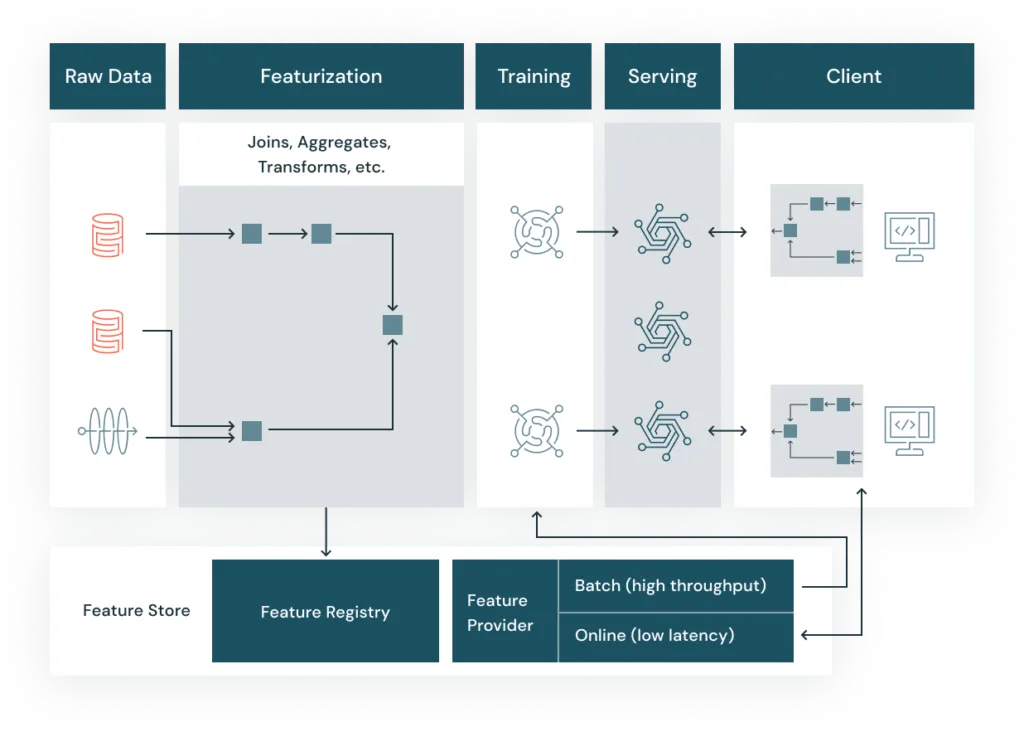
Wie ist der Feature Store aufgebaut?
Feature Stores bestehen neben den Features aus den folgenden drei Komponenten:
- Transformationsschicht
- Speicherschicht
- Auslieferungsschicht
Sehen wir uns die einzelnen Schichten genauer an.
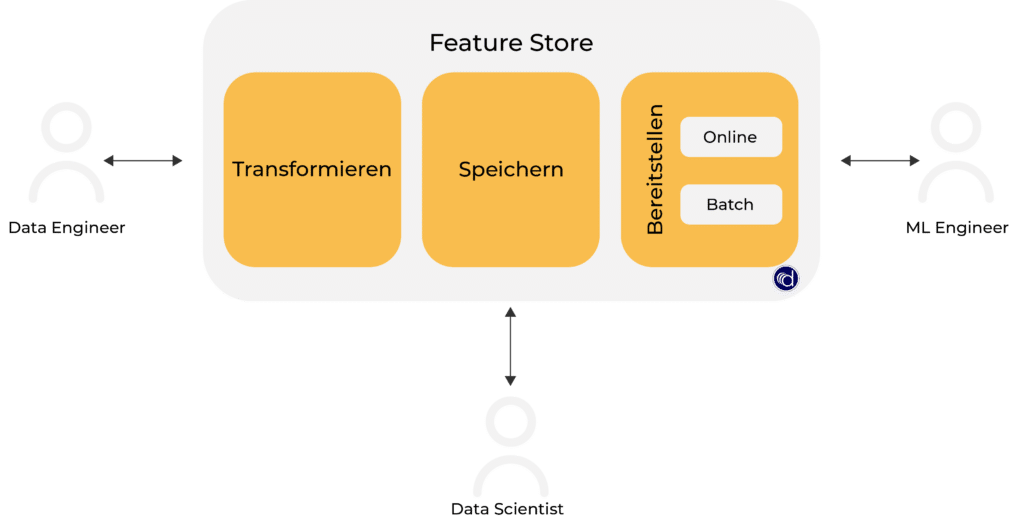
Transformationsschicht
Die Transformationsschicht dient der Transformation von Rohdaten in Feature Daten. Hier sind mehrere Schritte zu berücksichtigen:
- Datenintegration aus verschiedenen Plattformen
- Qualitätssicherung (hierfür Schritte des Data Wrangling durchführen)
- Aufbereitung der Datentuples, damit sie von ML-Modellen verwendet werden können (z.B. One-Hot-Codierung oder Standardisierung des Wertebereichs eines Features)
Anschließend werden die Features in die Speicherschicht geladen.
Speicherschicht
In der Speicherschicht werden die zuvor transformierten Features gesichert. Der Feature Store muss hierfür ein Backend besitzen, welches die Speicherung historischer Features sichert. Als Backend kommt z.B. ein Data Warehouse in Frage aber auch die Speicherung in einem Data Lake ist möglich.
Von der Speicherschicht werden die Features in die Auslieferungsschicht übertragen.
Auslieferungsschicht
Die Auslieferungsschicht stellt die Features zur Weiterverarbeitung bereit. Durch Batch-API ist es Data Scientists (oder anderen Teams) dann möglich, Trainingsdaten für Modelle abzurufen.
Was sind die einzelnen Funktionen des Feature Stores?
Der Feature Store verwaltet sowohl historische als auch aktuelle Features und ermöglicht den problemlosen Zugriff auf diese Daten. In dem Feature Store sind die Funktionen des Data Warehouses und die des operativen Speichers enthalten:
- die Entdeckung, Überwachung, Analyse und Wiederverwendung von Features innerhalb einer Organisation
- vorberechnete Features, die Online-Modelle verwenden können, um ihre Feature Vektoren mit historischen und kontextuellen Daten berechnen zu können
Wie hilft der Feature Store bei den Herausforderungen des maschinellen Lernens?
Machinelles Lernen, Data Science und künstliche Intelligenz: die wohl aktuellsten Themen der heutigen Unternehmenswelt. Diese analytisch gestützten Prozesse versprechen höhere Umsätze und mehr Prozesseffizienz. Leider vergessen wir dabei häufig, dass der Einsatz von Machine Learning selbst mit einem großen Prozessaufwand verbunden ist (z.B. im Punkt Datenverarbeitung).
Um die Effizienz sowie Skalierbarkeit von Data Science und künstlicher Intelligenz zu steigern, kommen (Machine Learning-) Feature Stores zum Einsatz.
Wieso Sie einen Feature Store brauchen?
Feature Stores heben die Datenaktualität an, ermöglichen das Erstellen von genauen Modellen durch hohe Skalierbarkeit und helfen dabei, präzise Vorhersagen zu treffen. Die Features sind außerdem nicht mehr begrenzt abrufbar für ein paar ausgewählte Experten, sondern für alle, die den Zugang benötigen.
Was sind die Ziele des Feature Stores?
- Wir wollen Reibungen zwischen Data Scientists, Data Engineers und Machine Learning Engineers reduzieren, in dem wir einen zentralen Speicher für verschiedene Projekte bilden
- Wer möchte schon gerne suchen? Der Feature Store erleichtert die Auffindbarkeit von Features
- Nennen wir es beim Namen. Die Features sollen einheitlich benannt werden, um eine einheitliche Verarbeitung zu gewährleisten.
- Features sollen nicht mehr verschieden verteilt sein (zwischen Training und Inferenz), sondern zentral an einem Ort
Was sind die konkreten Vorteile des Feature Stores?
Die einzelnen Variablen für maschinelles Lernen sind in einem standardisierten, qualitätsgesicherten Prozess abgespeichert. Dadurch wird ein zentraler Punkt für Machine Learning-Features geschaffen, wo jedes Data Science Team kuratierte Daten zur Verfügung hat. Neben vielen Vorteilen für die Modelltrainings, wird ein standardisierter Prozess für das Modell Deployment erarbeitet, der die gleiche Feature Logik wie im Lernprozess nutzt und somit eine konsistente Plattform schafft.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Machine Learning Feature Stores adressieren viele Probleme von Data Science Projekten und schaffen somit große Effizienz, vor allem bei größeren Projekten, wo ein hoher Automatisierungsgrad erreicht werden soll. Die fünf größten Vorteile listen wir Ihnen in folgender Tabelle auf.
| Vorteil | Detailliert |
| 1.Qualitätssicherung von Features | Durch ETL-Prozesse und Loggingfunktion können Daten zuverlässig für analytische Prozesse verwendet werden. |
| 2. Effizienter Einsatz von Data Scientists | Durch den Einsatz eines gut konzipiertem Feature Stores, können Sie die Arbeitszeit von Analysten effizienter planen. Denn Studien belegen, dass Data Scientists ca. 80% der Zeit bei Data Science Projekten für Datenaufbereitung nutzen. |
| 3. Grad der Automatisierung von Machine Learning | Durch die Automatisierung von Validierungsprozessen auf die immer bereitstehenden Features, können Machine Learning Modelle leicht in Bezug auf Qualität bewertet werden. Dies kann sogar soweit führen, dass völlig automatisiert ein Re-Training des Modells auf einem neuen Datenstand durchgeführt wird. |
| 4. Zentraler Hub für Machine Learning Projekte | Ein sehr wichtiger Punkt für einen Feature Store ist die Zentralisierung der Machine Learning Datenbasis. Besonders in Bezug auf die Effizienz eines Teams macht es Sinn, das Know-How und die Logik für die Aufbereitung von Features zentral zu steuern. Dadurch werden Probleme wie unübersichtliche Codeskripts und Data-Pipeline Jungle vermieden. |
| 5. Skalierbarkeit von Data Science | Durch die Zentralisierung der ML Features, können neue Projekte und Modelle schneller skaliert und umgesetzt werden, denn die Daten, Infrastruktur und standardisierten Prozesse sind somit bereits vorhanden. |
Durch die Vorteile der effizienten Arbeitseinteilung und Qualitätssicherung sparen Sie nicht nur Zeit, sondern vor allem unnötige Kosten.
Gehen wir nun von der Theorie über in die Praxis. Welche Anbieter stellen einen Feature Store zur Verfügung?
Welche Anwender bieten Feature Stores an? (3 Feature Stores)
Die Bedeutung von Feature Stores wurde bereits von verschiedenen Unternehmen erkannt. So setzen große Machine Learning Companies wie Databricks auf Feature Store Lösungen, die verschiedene Benefits bringen. Hier stellen wir Ihnen vier Feature Store Lösungen vor.
AWS Sagemaker
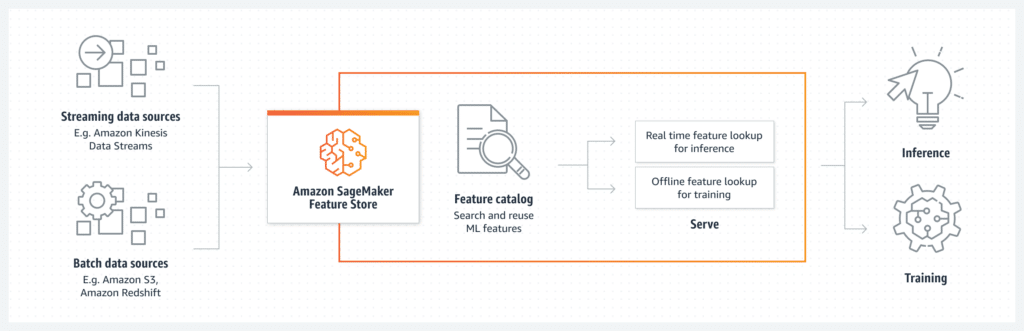
Das Speichern, Freigeben und Verwalten von Funktionen für Machine Learning wird durch das zweckgebundene Repository von Amazon SageMaker Feature Store garantiert.
Der Amazon SageMaker Feature Store bezieht aus Streaming oder Batch Data Quellen Daten. Sind die Daten in den SageMaker geladen werden sie einem Feature Katalog zugeordnet, wo sie von Datenwissenschaftlern aktiv gesucht und wiederverwendet werden können.
Databricks
Databricks bietet verschiedene Lösungen zur Datenspeicherung- und Verwaltung im Machine Learning Prozess an. Neben dem Data Lakehouse bietet Databricks seinen Kunden die Möglichkeit, einen Databricks Feature Store zu implementieren. Der Feature Store setzt an dem Prozess des Feature Engineerings (bei Databricks Featurization genannt) an. Der Store registriert die Daten und stellt sie als Batch oder Online Source zur Verfügung.
Hier bietet Databricks die Möglichkeit, ein Beispiel Notebook für den Feature Store anzusehen.
Wie genau Databricks Feature Store funktioniert haben wir euch in einem Youtube Tutorial festgehalten:
Feast
Der Open Source Feature Store Feast lässt sich in jeder Kubernetes-Umgebung einsetzen. Feast ermöglicht die Verwaltung der bestehenden Infrastruktur, um Analysedaten für das Modelltraining und die Online-Inferenz zu produzieren. Daten werden aus Streaming Quellen wie Kafka oder Kinesis oder Batch Quellen wie Snowflake oder S3 in die Transformationsschicht geladen.
Nachdem die Daten in Features transformiert wurden, werden sie in die Feast-Schicht übertragen. Hier liegt die Speicher- und Abfrageschicht von wo aus die Features für weitere Analysen genutzt werden können.

Feature Stores in der Praxis
Große Tech-Firmen wie Google (TFX), Uber (Michelangelo) und Facebook (FBLearner) haben die Vorteile für sich erkannt und setzen auf solche Ansätze der Machine Learning Plattformen. Ein interessanter Podcast aus der O’Reilly Data Show beleuchtet genau dieses Thema bei Salesforce (Einstein). Zudem haben auch Netflix und Twitter ihre Plattformen und Architekturen bekanntgegeben.
Neben diesen Projekten gibt es mittlerweile auch einen ersten Open Source Ansatz des StartUps Logical Clocks, welches Big Data, Deep Learning und Machine Learning Plattformen entwickelt. Es wird also schnell klar, dass viel Geld und Ressourcen in die Entwicklung und den Aufbau von Machine Learning Plattformen fließen.
Uber gibt beispielsweise an, dass täglich bis zu 10.000 Features komplett automatisiert berechnet und bereitgestellt werden.
Fazit
Feature Stores eröffnen für Unternehmen neue Möglichkeiten, um die Themen rund um Machine Learning professioneller und effizienter innerhalb einer zentralen Plattform zu gestalten. Die vielen Vorteile, die sich dadurch ergeben, übertreffen die zu Beginn anfallenden Kosten schnell. Sie können von verschiedenen Projekten aus auf Features zugreifen und diese gemeinsam optimieren. Durch die einheitliche Verarbeitung der Features und den zentralen Speicherort, sparen Ihre Mitarbeiter Zeit, da sie keine zusätzlichen Datenverwaltungsarbeiten erledigen müssen.
Sie möchten einen Feature Store in Ihrem Unternehmen implementieren? Dann kontaktieren Sie uns!
FAQ: Die wichtigsten Fragen schnell beantwortet
Im Feature Store werden die Merkmale aus Daten gespeichert und organisiert, damit sie entweder zum Trainieren von Modellen (durch Data Scientists) oder zur Erstellung von Vorhersagen (Predictive Analytics) verwendet werden können.
Feature Stores bestehen aus zweiteiligen Datenbanken, siehe folgende Auflistung:
1. Eine offline Datenbank, die für Batch-Vorhersagen und Modelltraining verwendet wird. Diese Datenbank speichert große Mengen an historischen Merkmalen für das Training von ML-Modellen.
2. Eine online Datenbank, die Online-Merlmale mit geringer Latenz für trainierte Modelle bereitstellt, die bereits in Produktion sind. Die Datenbank stellt den Modellen die aktuellsten Merkmale zur Verfügung.
Feature Stores sind nützlich, da sie es Datenwissenschaftlern ermöglichen, Merkmale auf dem Server zu berechnen, beispielsweise die Anzahl der Klicks. Die Alternative dazu ist die Berechnung von Merkmalen im Modell selbst oder/und die Berechnung in einer Transformationsfunktion in SQL.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte








