


Die Entwicklung von Large Language Models (LLMs) hat sich in den letzten Jahren rasant fortentwickelt, sodass sie zu einem der interessanten Tools für den Einsatz von generativer KI geworden sind. Sie sind in der Lage, menschliche Sprache zu verstehen, zu generieren und zu verarbeiten, was eine Vielzahl von Anwendungen in verschiedenen Branchen ermöglicht. Von automatisierten Chatbots über Textgenerierung bis hin zu komplexen Analysewerkzeugen – LLMs bieten enorme Potenziale für Unternehmen und Organisationen, ihre Effizienz und Innovationskraft zu steigern.
Bei der Feinabstimmung (Fine-Tuning) werden bereits vortrainierte LLMs optimiert, um sie an spezifische Aufgaben oder Datensätze anzupassen. In der Vergangenheit war die Anwendung dieser Modelle oft durch ihre generische Natur eingeschränkt, was bedeutete, dass sie nicht immer die spezifischen Herausforderungen und Daten einzelner Organisationen adressieren konnten. Diese Limitation führte dazu, dass die Potenziale der Modelle oft nicht vollständig ausgeschöpft werden konnten.
Durch die Verwendung von Fine-Tuning-Techniken können Unternehmen LLMs jedoch gezielt an ihre spezifischen Bedürfnisse anpassen, wodurch der maximale Mehrwert dieser Technologien im Geschäftskontext erzielt wird.
Ziel dieses Artikels ist es, Ihnen einen Einblick in die Technik des Fine-Tunings von LLMs zu geben. Wir werden die Vorteile und Szenarien für Fine-Tuning erläutern, den Fine-Tuning-Prozess beschreiben und Best Practices sowie praktische Anwendungsbeispiele vorstellen.
Lassen Sie uns starten!
Was sind die Vorteile von Feinabstimmung?
Feinabstimmung (Fine-Tuning) im Bereich der großen Sprachmodelle (LLMs) ist ein Prozess, bei dem ein vortrainiertes Modell (wie Alpaca, Falcon, Mistral AI oder einen der vielen Transformern von Hugging Face) auf einem spezifischen, oft kleineren Datensatz weiter trainiert wird. Dieser Prozess sorgt für eine Modell-Personalisierung, um es für bestimmte Aufgaben oder Kontexte zu spezialisieren.
- Verarbeitung von Unternehmensspezifischen Informationen: Vortrainierte Modelle können zwar menschliche Anfragen verstehen und angemessene Antworten generieren, jedoch verfügen sie nur über generalisiertes Wissen. Sie sind nicht in der Lage, unternehmensspezifische Informationen, wie etwa Details zu Produkten oder Dienstleistungen, in ihrer „rohen Form“ zu verarbeiten. Durch den Fine-Tuning-Prozess kann das Modell gezielt angepasst werden, sodass es unternehmensspezifische Informationen, Anfragen und Herausforderungen ohne Probleme verarbeiten kann. Dies führt zu relevanteren und präziseren Antworten, die den individuellen Anforderungen des Unternehmens gerecht werden.
- Steigerung von Genauigkeit und Effizienz: Fine-Tuning verbessert nicht nur die Genauigkeit der LLMs, sondern steigert auch deren Effizienz. Indem das Modell an einem Datensatz trainiert wird, der eng mit der Zielanwendung abgestimmt ist, wird es geschickter im Umgang mit spezifischen Anfragen. Eine Studie von Google zeigt, dass der Einsatz von Fine-Tuning-Techniken die Effizienz von Large Language Models um bis zu 10 % steigern kann. Unternehmen können durch gezieltes Fine-Tuning nicht nur die Qualität ihrer KI-gestützten Anwendungen verbessern, sondern auch Ressourcen effizienter nutzen.
Dadurch ermöglicht Fine-Tuning ein personalisierteres KI-Erlebnis. In kundenorientierten Anwendungen, wie Chatbots oder digitalen Assistenten, kann ein feinabgestimmtes Modell Antworten liefern, die besser auf den Ton, die Sprache und die Erwartungen der Kunden abgestimmt sind.
Dies führt nicht nur zu einer erhöhten Benutzererfahrung und -zufriedenheit, sondern auch zu einer verbesserten Effizienz der Teams, da weniger Zeit für die Nachbearbeitung von Antworten aufgewendet werden muss. Insgesamt können Unternehmen durch den Einsatz von Fine-Tuning signifikante Vorteile in Bezug auf Leistung und Benutzerzufriedenheit erzielen.
Wann sollte Fine-Tuning eingesetzt werden?
Durch die Vorteile des Fine-Tunings von LLMs wird also ersichtlich, dass diese Methode insbesondere dann sinnvoll ist, wenn vortrainierte Modelle nicht die gewünschten Ergebnisse liefern können oder spezifische Anforderungen nicht gerecht werden. Typische Anwendungsfälle und für den Einsatz von Fine-Tuning wären:
Typische Use Cases
- Chatbots mit spezifischen Instruktionen: Bei der Entwicklung von Chatbots, die auf bestimmte Anfragen oder Konversationsthemen fokussiert sind, kann Fine-Tuning helfen, präzisere und relevantere Antworten zu generieren, die auf den spezifischen Bedürfnissen der Nutzer basieren.
- Aufgabenspezifische LLMs: Fine-Tuning eignet sich hervorragend für die Erstellung aufgabenspezifischer Modelle, wie etwa für die Code-Generierung, bei der präzise und kontextsensitive Ergebnisse erforderlich sind. Ein anderes Beispiel wäre die Extraktion von bestimmten Merkmalen aus standardisierten Texten, wie zum Beispiel Eckdaten aus Verträgen.
- Domänenspezifische LLMs: In spezialisierten Bereichen wie Medizin oder Recht kann Fine-Tuning sicherstellen, dass das Modell über das nötige Fachwissen verfügt, um kontextspezifische Informationen korrekt zu verarbeiten und zu liefern. Die „native“ Verwendung von Domänenspezifischer Sprache kann beispielsweise bei RAG-Ansätzen mangelhaft sein, da die Antwort hier immer nur aus dem gerade angezeigten Kontext gespeist wird, bei Fine-Tuning hingegen aber tatsächlich in das Modell hineingearbeitet wurde.
Typische Gründe für Fine-Tuning
- Unzureichende Ergebnisse bei Prompt Engineering oder RAG: Wenn herkömmliche Ansätze wie Prompt Engineering oder Retrieval-Augmented Generation (RAG) nicht die gewünschten Ergebnisse liefern, kann Fine-Tuning eine effektivere Lösung darstellen.
- Vorhandensein einer quantitativen Metrik: Wenn eine klare und wohldefinierte quantitative Metrik vorliegt, anhand derer die Qualität der Ergebnisse präzise definiert werden kann, ist Fine-Tuning der richtige Ansatz, um die gewünschten Leistungsziele zu erreichen. Ein Beispiel wäre hier ein Sentiment Analyzer, der aus einem vorliegenden Text die Stimmung „Positiv“ oder „Negativ“ abliest. Hier kann mit gängigen Klassifikationsmetriken gearbeitet werden.
- Verfügbarkeit ausreichender Daten: Für ein erfolgreiches Fine-Tuning ist eine ausreichende Menge an qualitativ hochwertigen Daten erforderlich. Wenn diese Daten vorhanden sind, kann das Modell gezielt angepasst werden.
- Latenz- und Kostenintensive Anwendungen: Fine-Tuning ermöglicht die Verwendung von kompakten Prompts, die schnellere Reaktionszeiten und geringere Betriebskosten bieten. In Szenarien, in denen eine niedrige Latenz oder reduzierte Kosten entscheidend sind, ist es oft sinnvoller, ein kleineres, feinabgestimmtes Modell zu verwenden, das die spezifischen Anforderungen der Anwendung erfüllt.
Fine-Tuning Schritt für Schritt einfach dargestellt
In seiner einfachsten Form ist Fine-Tuning von LLMs nichts anderes als konventionelles supervised learning, wie es bereits in großem Umfang im klassischen Machine Learning verwendet wird. Der Prozess besteht darin, ein vortrainiertes Modell weiter zu trainieren, um es an spezifische Aufgaben oder Anforderungen anzupassen. Das Modell wird dabei mit gekennzeichneten Daten gefüttert, die aus Eingaben und den entsprechenden gewünschten Ausgaben bestehen. Diese gelabelten Daten sind entscheidend, da sie dem Modell helfen, die richtigen Muster zu erkennen und zu lernen, wie es auf bestimmte Anfragen reagieren soll. Durch die Anpassung an die spezifischen Anforderungen der Anwendung kann das Modell genauere und relevantere Ergebnisse liefern.

Beispiel: Stellen Sie sich vor, Sie haben ein allgemeines Sprachmodell, das Texte in verschiedenen Stilen generieren kann. Nun möchten Sie es speziell für die Erstellung von technischen Dokumentationen in der IT-Branche optimieren. Durch Fine-Tuning mit einem Datensatz aus hochwertigen IT-Dokumentationen lernt das Modell, präzise technische Begriffe zu verwenden, klare Strukturen zu erstellen und den Ton professioneller Dokumentationen zu treffen.
Hier ist eine erweiterte Schritt-für-Schritt-Anleitung für den Fine-Tuning-Prozess:
- Modellauswahl: Zunächst wählen Sie ein geeignetes vortrainiertes Modell aus, das als Ausgangspunkt für das Fine-Tuning dient. Beliebte Modelle sind beispielsweise Mistral oder BERT, da sie bereits umfangreiche Sprachfähigkeiten besitzen. Die Auswahl des Modells hängt von der spezifischen Aufgabe und den Anforderungen ab, die Sie erfüllen möchten. Interessant sind hier beispielsweise auch die Modelle auf Hugging Face, wo die speziellen Aufgabenfelder durch die Erstellenden mit angegeben sind.
- Datenvorverarbeitung: In diesem Schritt sammeln und bereiten Sie einen Datensatz vor, der relevante Beispiele für die spezifische Aufgabe enthält. Die Daten sollten so strukturiert sein, dass sie klare Eingaben und die entsprechenden Ausgaben enthalten. Es ist wichtig, dass die Daten von hoher Qualität sind und korrekt gelabelt wurden, da diese Informationen entscheidend für das Lernen des Modells sind. Achten Sie darauf, dass Ihr Datensatz die reale Anwendungsumgebung widerspiegelt. Ein ausgewogener Datensatz hilft, Verzerrungen zu vermeiden. Zum Beispiel, wenn Sie ein Modell für Kundensupport trainieren, stellen Sie sicher, dass Ihr Datensatz verschiedene Kundentypen, Probleme und Lösungsansätze abdeckt.
- Fine-Tuning: Nach der Datenvorbereitung wird das ausgewählte Modell mit den vorbereiteten Daten weiter trainiert. Hierbei passt sich das Modell an die spezifischen Merkmale und Anforderungen der neuen Aufgabe an. Durch die Anpassung der Modellparameter lernt es, die Eingaben korrekt zu klassifizieren oder vorherzusagen.
- Testen/Evaluieren: Nach dem Fine-Tuning wird das Modell gründlich getestet und evaluiert, um seine Leistung zu überprüfen. In dieser Phase können Sie auch Rückmeldungen sammeln, um festzustellen, ob das Modell weiter optimiert werden muss. Es ist wichtig, separate Datensätze für das Training, die Validierung und den Test zu verwenden. Der Validierungsdatensatz hilft, die Hyperparameter während des Trainings anzupassen, während der Testdatensatz die endgültige Leistung auf völlig neuen Daten misst.
- Live-Schaltung: Wenn das Modell zufriedenstellende Ergebnisse liefert, ist es bereit für den Einsatz in einer Produktionsumgebung. Dies beinhaltet die Implementierung des Modells in die tatsächlichen Anwendungen, wo es auf neue Daten angewendet wird und Benutzeranfragen in Echtzeit bearbeitet. Ziel soll es außerdem sein, die Ergebnisse und den Output des Modells in die Zielsysteme zu bringen, beispielsweise in einen Chatbot oder als Schnittstelle für Mitarbeitende.
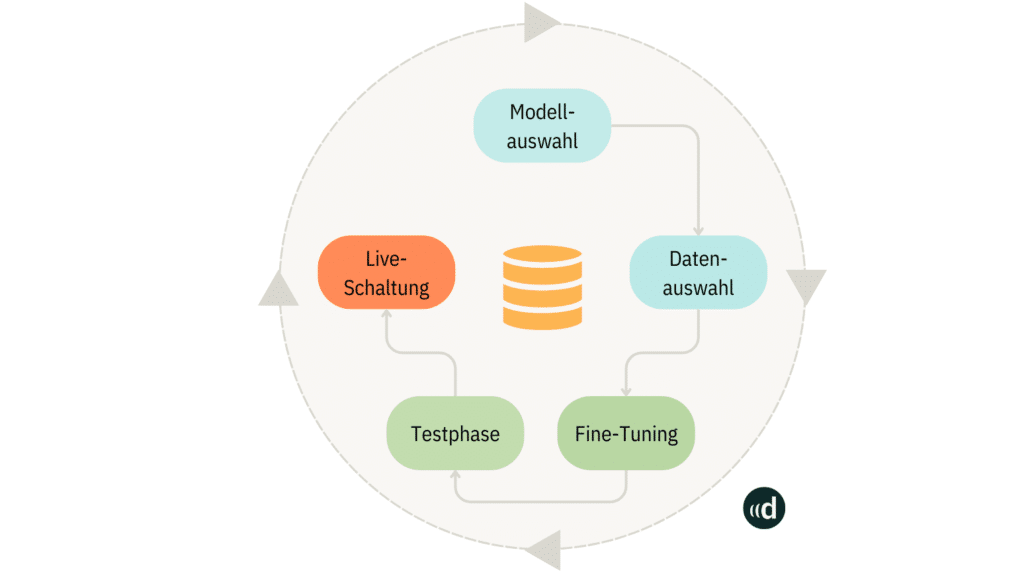
Durch diesen strukturierten Ansatz ermöglicht Fine-Tuning, das volle Potenzial von LLMs auszuschöpfen, indem es an spezifische Geschäftsbedürfnisse und Anwendungsfälle anpasst wird. So können Unternehmen maßgeschneiderte Lösungen entwickeln, die sowohl die Effizienz als auch die Genauigkeit ihrer KI-Anwendungen verbessern.
Methoden zur Feinabstimmung von LLMs
Zwar haben wir uns jetzt die Gründe und den generellen Ansatz des Fine-Tunings angeschaut, aber nun wollen wir uns den Fine-Tuning Prozess an sich näher anschauen. Angenommen, ein Entwicklerteam hat für seinen Use Case ein passendes LLM ausgewählt und verfügt außerdem über eine ausreichende Menge an gelabelten Daten, so kann es mit dem Fine-Tuning Prozess beginnen.
Bevor wir uns die spezifischen Methoden ansehen, ist es wichtig zu verstehen, was beim Fine-Tuning auf Parameterebene geschieht. Ein LLM besteht aus Millionen oder sogar Milliarden von Parametern – dies sind die Gewichte und Verzerrungen (Biases) in den neuronalen Netzwerkschichten des Modells. Beim Fine-Tuning werden also nun diese Parameter angepasst, um das Modell für eine spezifische Aufgabe zu optimieren.
Der Prozess beginnt mit einem vortrainierten Modell, dessen Parameter bereits durch Training auf großen Textkorpora initialisiert wurden. Während des Fine-Tunings werden neue, aufgabenspezifische Daten durch das Modell geleitet. Die Ausgabe des Modells wird mit den erwarteten Ergebnissen (was wir im vorherigen Absatz als „Output“ in der Grafik dargestellt hatten) verglichen, und die Differenz, auch als „Verlust“ bezeichnet, wird verwendet, um die Modellparameter schrittweise anzupassen.
Der „Verlust“ ist ein zentrales Konzept im maschinellen Lernen und beim Fine-Tuning von LLMs. Er quantifiziert, wie weit die Vorhersagen des Modells von den tatsächlichen, erwarteten Ausgaben entfernt sind. Je größer der Verlust, desto schlechter performt das Modell auf den gegebenen Daten. Das Ziel des Trainings ist es, diesen Verlust zu minimieren.
Die Berechnung des Verlusts hängt von der spezifischen Aufgabe und der gewählten Verlustfunktion ab. Für Sprachmodelle wird häufig die Cross-Entropy-Verlustfunktion verwendet. Bei dieser Funktion wird für jedes Wort oder Token in der Ausgabe die Wahrscheinlichkeit berechnet, die das Modell ihm zuweist, und mit der tatsächlichen (erwarteten) Wahrscheinlichkeit verglichen. Der Gesamtverlust ist dann der Durchschnitt dieser Einzelverluste über alle Wörter oder Tokens in einem Batch von Trainingsdaten.
Dieser berechnete Verlust wird dann verwendet, um die Modellparameter durch Backpropagation und Gradient Descent anzupassen. Das Ziel ist es, die Parameter so zu justieren, dass das Modell bessere Vorhersagen für die spezifische Aufgabe macht, ohne dabei das allgemeine Sprachverständnis zu verlieren, dass es während des Vortrainings erworben hat. Dieser Verlust des allgemeinen Sprachverständnisses wird als „Catastrophic Forgetting“ bezeichnet und ist eine gängige Herausforderung beim Fine-Tuning von LLMs.
Gängige Ansätze des Fine-Tunings
Es gibt verschiedene Methoden und Techniken, die beim Fine-Tuning von LLMs zum Einsatz kommen können. Diese unterscheiden sich hauptsächlich darin, welche und wie viele Parameter angepasst werden. Hier sind einige der gängigsten Ansätze:
- Full Fine-Tuning: Bei dieser Methode werden alle Parameter des vortrainierten Modells aktualisiert. Dies kann sehr effektiv sein, erfordert aber oft erhebliche Rechenressourcen und große Datenmengen.
Vorteile: Maximale Anpassungsfähigkeit, potenziell beste Leistung für spezifische Aufgaben.
Nachteile: Hoher Rechenaufwand, Risiko des Overfittings, möglicher Verlust allgemeiner Sprachfähigkeiten.
- Parameter-Efficient Fine-Tuning (PEFT): Diese Methoden zielen darauf ab, nur einen kleinen Teil der Modellparameter anzupassen, was den Prozess effizienter macht. Ein bekanntes Beispiel ist LoRA (Low-Rank Adaptation).
Vorteile: Deutlich geringerer Rechenaufwand, Weniger Speicherbedarf, Reduziertes Risiko von Catastrophic Forgetting
Nachteile: Möglicherweise etwas geringere Leistung im Vergleich zum Full Fine-Tuning
LoRA zum Beispiel fügt kleine, trainierbare Module zu den bestehenden Modellschichten hinzu, anstatt alle Parameter zu aktualisieren. Dies ermöglicht eine effiziente Anpassung bei gleichzeitiger Beibehaltung der grundlegenden Modellstruktur.
- Instruction Fine-Tuning: Hierbei wird das Modell darauf trainiert, spezifische Anweisungen oder Prompts zu befolgen.
Vorteile: Verbessert die Fähigkeit des Modells, Aufgaben basierend auf natürlichsprachlichen Anweisungen auszuführen.
- Multi-Task Fine-Tuning: Das Modell wird gleichzeitig auf mehrere verwandte Aufgaben trainiert.
Vorteile: Kann die Generalisierungsfähigkeit verbessern und die Leistung für mehrere Aufgaben optimieren.
Bei der Auswahl der Fine-Tuning-Methode sollten Entwickler verschiedene Faktoren berücksichtigen:
- Datenmenge: Für kleinere Datensätze können PEFT-Methoden vorteilhaft sein.
- Rechenressourcen: Bei begrenzten Ressourcen sind effiziente Methoden wie LoRA oder Instruction-Tuning zu bevorzugen.
- Anwendungsfall: Für sehr spezifische Aufgaben kann Full Fine-Tuning die beste Wahl sein, während Multi-Task Fine-Tuning für vielseitigere Anwendungen geeignet ist.
- Modellgröße: Für sehr große Modelle sind PEFT-Methoden oft praktikabler.
Es ist wichtig zu beachten, dass der Fine-Tuning-Prozess oft experimentell ist. Entwickler sollten verschiedene Methoden testen und die Ergebnisse sorgfältig evaluieren, um die beste Lösung für ihren spezifischen Anwendungsfall zu finden.
Sehen wir uns nun an, wie Unternehmen Fine-Tuning erfolgreich einsetzen.
Erfolgreiche Anwendungsfälle von LLMs
Die Integration von feinabgestimmten großen Sprachmodellen (LLMs) in Ihr Unternehmen bedeutet vor allem:
- Personalisierung,
- Effizienzsteigerung
- und eine Optimierung der Kunden- und Mitarbeiterkommunikation.
Im Folgenden stellen wir Ihnen drei Anwendungsfälle vor, in welchem wir Large Language Modelle für unsere Kunden implementierten und mit Hilfe von Fine-Tuning Anwendungsspezifisch anpassten.
LLM als Wein-Sommelier (E-Commerce):
Für einen renommierten B2C Weinhändler programmierten wir einen auf GPT-basierten Chatbot. Der Chatbot soll Kunden auf der Website als Berater zur Seite stehen und passende Weine aus dem Sortiment mit über 10.000 Produkten vorschlagen. In die Konversation sollen Angaben der Weine über das Jahr, die Rebe, die Herkunft und die Geschmackskomponenten einfließen. Die Beratung erfolgt dann auf Grundlage der Geschmacksvorlieben der Kunden und den angebotenen Produkten.
Das Ergebnis ist ein Chat-Interface, in dem der Kunde eine Anfrage stellen kann wie „Empfiehl mir einen passenden Rotwein zu einem Lamm-Schmorgericht, der nicht mehr als 12 Euro kostet.“ Der Chatbot crawlt dann innerhalb weniger Sekunden das Produktangebot und filtert es nach passenden Artikeln. Die top 3 schlägt das LLM dem Kunden vor.
LLM als Sales-Assistent (B2B-Handel):
Einer unserer Kunden, ein führender B2B-Händler in Deutschland, wollte seine NBO-Strategie mit Hilfe eines Large Language Models optimieren. Damit die Sales-Manager den B2B-Kunden personalisierte Produktempfehlungen vorschlagen, trainierten wir das LLM durch Fine-Tuning. Hierfür verwendeten wir die Daten zur Kaufhistorie von Kunden und verglichen das Kaufverhalten mit den über 200.000 Produkten. In einem Chat-Interface berät das LLM die Mitarbeiter des B2B-Händlers und schlägt aus den 200.000 Produkten die Produkte vor, die am besten zum Kaufverhalten des jeweiligen Kunden passen. Der Sales-Agent schlägt dem Kunden dann binnen weniger Minuten die passenden Produkte vor, das nächste beste Angebot.
LLM als Sachbearbeiter (Recht):
Anwaltskanzleien haben begonnen, LLMs zur Rationalisierung der Analyse von Rechtsdokumenten und Forschungsarbeiten zu nutzen. Für eine renommierte Kanzlei bauten wir ein LLM auf Basis von GPT, welches durch Fine-Tuning problemlos auf Gesetze, Fallrecht und juristische Präzedenzfälle zugreifen und spezifische Informationen liefern kann. Diese Implementierung reduziert signifikant die Zeit, die Anwälte für rechtliche Recherchen aufwenden mussten, und ermöglicht es ihnen, sich auf die Strategie des Falls und die Interaktion mit Kunden zu konzentrieren. Das Modell hilft bei der Erstellung juristischer Dokumente und stellt die Einhaltung aktueller Gesetze und rechtlicher Standards sicher.
Indem LLMs auf spezifische Branchenanforderungen zugeschnitten werden, haben Unternehmen nicht nur ihre betriebliche Effizienz verbessert, sondern auch einen Wettbewerbsvorteil durch
- verbesserte Entscheidungsfindung,
- Risikomanagement
- und Kundenengagement erlangt.
Da sich KI weiterentwickelt, werden die potenziellen Anwendungen von feinabgestimmten LLMs in verschiedenen Sektoren zweifellos zunehmen und weiterhin Innovation und Geschäftserfolg vorantreiben.
Sie möchten Ihr LLM optimieren oder mit den Vorteilen von Large Language Models durchstarten? Dann kontaktieren Sie uns für ein unverbindliches Erstgespräch.
Das Fine-Tuning von LLMs sollte unbedingt von geschulten Fachkräften erfolgen. Sehen wir uns an, welche Herausforderungen bei der Feinabstimmung von bestehen und wie diese zu lösen sind.
Herausforderungen und Lösungen bei der Umsetzung von KI-Strategien
Die Implementierung von KI-Strategien, einschließlich des Fine-Tunings von LLMs, bringt verschiedene Herausforderungen mit sich. Es gibt jedoch spezifische Lösungsansätze, die helfen können, diese Herausforderungen zu bewältigen:
Sie möchten Ihr LLM optimieren oder mit den Vorteilen von Large Language Models durchstarten? Dann kontaktieren Sie uns für ein unverbindliches Erstgespräch.
| Kategorie | Herausforderung | Lösung |
| Datenschutz und Datensicherheit | Die Verwendung sensibler Daten für das Training kann Datenschutzrisiken bergen. | Implementierung von robusten Datenanonymisierungs- und Verschlüsselungstechniken, um Vertraulichkeit und Sicherheit sensibler Daten zu gewährleisten. |
| Modellverzerrung und Fairness | KI-Modelle können die Verzerrungen und Vorurteile der Trainingsdaten übernehmen. | Verwendung diversifizierter und ausgewogener Trainingsdatensätze sowie die Anwendung von Fairness-Algorithmen, um Verzerrungen zu reduzieren. |
| Ressourcenintensität | Fine-Tuning von LLMs erfordert erhebliche Rechenleistung und kann teuer sein. | Einsatz von Cloud-Computing-Diensten und Optimierung der Modellarchitekturen, um den Ressourcenverbrauch zu senken und Kosten effizient zu verwalten. |
| Technologische Schnelllebigkeit | KI-Technologien entwickeln sich rasant, sodass Modelle schnell veraltet sein können. | Aufbau von kontinuierlichen Lern- und Modellaktualisierungsprozessen, um mit den neuesten Entwicklungen Schritt zu halten. |
| Kompetenzlücke | Der Umgang mit LLMs erfordert spezialisierte Kenntnisse, die oft intern fehlen. | Investition in Schulungs- und Weiterbildungsprogramme oder Zusammenarbeit mit externen KI-Experten, um fehlende Fähigkeiten zu kompensieren. |
Durch die gezielte Bewältigung dieser Herausforderungen können Sie KI-Strategien effektiv implementieren, um eine erfolgreiche Integration zu gewährleisten und die Vorteile der KI zu maximieren. Zuletzt stellen wir Ihnen Best Practices vor, die uns bei dem Fine-Tuning von Large Language Models geholfen haben.
Feinabstimmung von LLMs: Best-Practices
Der Prozess der Feinabstimmung und die Einhaltung von Best Practices sind entscheidend, um vortrainierte Modelle für spezifische Anwendungen zu optimieren. Dies umfasst mehrere Schritte:
Sie wollen mit Feinabstimmung starten? Dann schauen Sie sich an, wie wir Sie dabei unterstützen:
- Datenvorbereitung: Die Qualität und Relevanz der Trainingsdaten sind von zentraler Bedeutung. Daten sollten vor dem Fine-Tuning gründlich bereinigt werden, um Rauschen zu entfernen, fehlende Werte zu behandeln und sicherzustellen, dass sie konsistent und korrekt formatiert sind. Darüber hinaus kann Datenanreicherung (z.B. durch zusätzliche relevante Datensätze oder synthetische Daten) dazu beitragen, die Robustheit des Modells zu erhöhen. Wichtig ist auch, sicherzustellen, dass die Trainingsdaten keine Verzerrungen enthalten, um faire und präzise Modelle zu entwickeln.
- Auswahl des vortrainierten Modells: Die Wahl des richtigen Modells ist der Ausgangspunkt für erfolgreiches Fine-Tuning. Faktoren wie Modellarchitektur, Größe und vorgängige Trainingsdatensollten mit der Zielanwendung übereinstimmen. Beispielsweise wäre ein Modell der GPT-Reihe besser geeignet für generative Aufgaben, während spezialisierte Modelle wie BERT besser für textuelle Klassifikationsaufgaben funktionieren könnten. Achten Sie darauf, Modelle zu wählen, die bereits in Ihrer Domäne oder Anwendung gute Ergebnisse gezeigt haben.
- Feinabstimmungs–Stragie: abhängig von technischer und fachlicher Anforderung ist es essenziell die richtige Methode für die Feinabstimmung zu wählen. Wie bereits zuvor beschrieben, gibt es dort eine mannigfaltige Auswahl an Möglichkeiten, aus denen die Beste ausgewählt werden sollte.
- Validierung: Verwenden Sie einen Validierungssatz, um die Leistung zu bewerten und bestimmen Sie im voraus dafür adäquate Metriken. Dies hilft, den Feinabstimmungsprozess zu verfeinern und das Modell zu optimieren.
- Modelliteration: Verfeinern Sie das Modell basierend auf Leistungsbewertungen, indem Sie Parameter anpassen und verschiedene Strategien wie Regularisierung oder architektonische Anpassungen erforschen.
- Modellimplementierung: Integrieren Sie das feinabgestimmte Modell in die Zielumgebung und berücksichtigen Sie dabei Hardware- und Softwareanforderungen, Skalierbarkeit und Sicherheit.
Durch die Anwendung dieser Best Practices können Unternehmen sicherstellen, dass sie die Leistungsfähigkeit von LLMs optimal nutzen, um spezialisierte und anwendungsbezogene Modelle zu erstellen, die effizient, genau und gut angepasst sind.
Fazit
Das Fine-Tuning von LLMs ist essenziell, um die Interaktion zwischen Kunden und Mitarbeitern zu optimieren, Produktempfehlungen zu personalisieren, Mitarbeiter zu entlasten und Prozesse zu beschleunigen. Der Schlüssel zum Erfolg liegt in der effektiven und ethischen Implementierung dieser Technologien, um sicherzustellen, dass sie mit Geschäftszielen und gesellschaftlichen Normen übereinstimmen. Dieser Fortschritt betrifft nicht nur die technologische Verbesserung, sondern auch eine strategische Neuausrichtung hin zu stärker datengetriebenen, KI-informierten Entscheidungsprozessen.
Der Weg hin zu einer Data Driven Company beginnt mit einem einzigen Klick.
FAQ – Die wichtigsten Fragen schnell beantwortet
Fine-Tuning bezieht sich auf den Prozess der Anpassung eines bereits vortrainierten Großen Sprachmodells (LLM) an spezifische Aufgaben, Datensätze oder Anforderungen. Durch das Training des Modells mit einem zielgerichteten Datensatz lernt es, besser auf die Nuancen und Spezifika der gewünschten Anwendung zu reagieren.
Obwohl vortrainierte LLMs ein breites Verständnis der Sprache besitzen, sind sie möglicherweise nicht optimal auf die spezifischen Bedürfnisse oder den Jargon einer bestimmten Branche, Aufgabe oder Datenart abgestimmt. Durch das Fine-Tuning kann das Modell feiner auf diese spezifischen Anforderungen eingestellt werden, was zu einer verbesserten Leistung führt.
Ja, das Fine-Tuning kann die Generalisierungsfähigkeit eines Modells beeinflussen. Während es das Modell besser auf spezifische Aufgaben abstimmt, kann eine zu starke Spezialisierung dazu führen, dass das Modell weniger effektiv auf allgemeinere oder unterschiedliche Aufgaben reagiert. Ein ausgewogenes Fine-Tuning ist entscheidend, um die Spezialisierung ohne signifikante Einbußen bei der Generalisierung zu erreichen.
Ein feinabgestimmtes LLM ist in erster Linie für die Aufgabe oder den Datensatz optimiert, für den es angepasst wurde. Es kann jedoch für verwandte Aufgaben innerhalb eines ähnlichen Anwendungsbereichs oder einer Branche effektiv sein. Für deutlich unterschiedliche Aufgaben könnte ein erneutes Fine-Tuning oder die Verwendung eines anderen vortrainierten Modells erforderlich sein.
Zu den Herausforderungen gehören die Beschaffung qualitativ hochwertiger, relevanter Trainingsdaten, die Vermeidung von Überanpassung (Overfitting), die Bewältigung der Rechenanforderungen und die Handhabung von Verzerrungen im Trainingsdatensatz. Darüber hinaus erfordert die Auswahl der optimalen Hyperparameter und die Integration des feinabgestimmten Modells in bestehende Systeme sorgfältige Überlegungen.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte




