


Data Mining ist ein analytischer Prozess, bei dem computergestützte Methoden eingesetzt werden, um möglichst selbstständig und effizient interessante Datenmuster in großen Datensätzen zu identifizieren. Die verwendeten Algorithmen stammen aus der Statistik, der künstlichen Intelligenz oder dem maschinellen Lernen.
Sie fragen sich, was Data Mining ist und welche Methoden es gibt? In diesem Artikel zeige ich Ihnen, welche Methoden es gibt, wo die Unterschiede zur klassischen Statistik liegen und wie Sie Data Mining im Customer Relationship Management (CRM) erfolgreich einsetzen können. Wenn Sie das interessiert, dann lesen Sie weiter!
Steigen wir direkt ein!
Was ist Data Mining?
Data Mining Definition: Data Mining ist ein analytischer Prozess, der eine möglichst autonome und effiziente Identifizierung und Beschreibung von interessanten Datenmustern aus großen Datenbeständen ermöglicht.
Bei Data Mining handelt es sich um einen interdisziplinären Ansatz, der Methoden aus der Informatik und der Statistik verwendet. Häufig kommen Verfahren aus dem Bereich der künstlichen Intelligenz und des maschinellen Lernens zum Einsatz. Eine kurze Einführung in das Thema „maschinelles Lernen“ habe ich bereits in einem Beitrag gegeben.
Es gibt keine allgemeingültige Definition von Data Mining. Wichtig ist jedoch die Abgrenzung zum so genannten Knowledge Discovery in Data Bases (KDD). In vielen Arbeiten werden diese Begriffe gleichgesetzt. Dies ist jedoch nicht ganz korrekt. Knowledge Discovery in Data Bases ist ein umfassenderer Prozess, der die Methoden des Data Mining einschließt. Es umfasst aber auch Aufgaben wie die Aufbereitung der Daten, die Überprüfung auf Interferenzen oder die Visualisierung der Ergebnisse.
Ziel des Data Mining ist in der Regel die Generierung von Hypothesen aus einem Datenbestand, ein sogenannter hypothesenfreier Bottom-up-Ansatz.
Die Definition von Data Mining wird häufig als Synonym für andere Begriffe verwendet: Machine Learning, maschinelles Lernen, Deep Learning, Künstliche Intelligenz (KI).
Welche Vorteile hat Data Mining?
Data Mining hilft Unternehmen, extrem große Datenmengen zu analysieren, interessante Muster zu erkennen und daraus die richtigen Entscheidungen zu treffen. Die Vorteile von Data Mining sind:
- Kundenbedürfnisse erkennen und besser verstehen
- Genaue Vorhersagen für die Zukunft erstellen
- Zeitreihenprognosen erstellen
- Trends und Anomalien frühzeitig erkennen
- Texte und Bilder maschinell verarbeiten
- Entscheidungsprozesse stützen
- Hypothesen zu validieren
- Geschäftsprozesse optimieren
Data Mining Methoden
Die Methoden des Data Minings lassen sich grundsätzlich in die Gruppen: Klassifikation, Prognose, Segmentierung und Abhängigkeitsentdeckung enteilen.
- Klassifikation – ist die Suche nach Mustern anhand eines Klassifikationsmerkmals. Dies kann zum Beispiel die Modellierung einer Produktaffinität sein. Durch die antrainierten Muster lassen sich beispielsweise Produktaffinitäten vorhersagen.
- Prognose – ist die Suche nach Mustern einer numerischen Zielvariable. Prognoseverfahren werden eigesetzt um Werte (bspw. Umsatz oder Absatz im nächsten Monat) für die Zukunft vorherzusagen.
- Gruppierung (Segmentierung & Clustering) – das Finden von Gruppen und Segmenten in einem Datenbestand. Oft werden im Marketing und CRM Kundensegmentierungen durchgeführt um diese dann zur genaueren Targetierung von Marketing Maßnahmen zu nutzen.
- Abhängigkeitsentdeckung (Assoziation & Sequenz) – ist die Suche nach Mustern, bei denen Elemente untereinander in Beziehung und Abhängigkeit stehen. Ein Beispiel dafür ist eine klassische Warenkorbanalyse.
Da mehrere Data-Mining-Methoden für die gleiche Problemstellung eingesetzt werden können, ist es sinnvoll, die Methoden nach Aufgabentypen zu gliedern. Die folgende Abbildung zeigt, dass sich die Aufgabentypen auf der obersten Ebene in Potenzial- und Beschreibungsaufgaben unterscheiden.
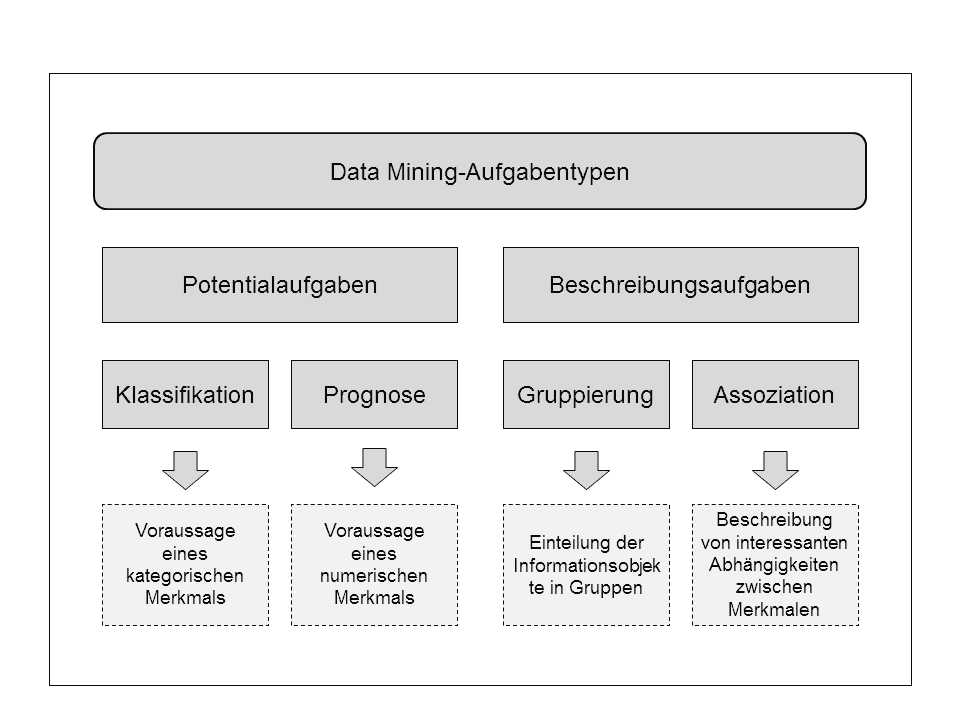
Klassifikation
Die Klassifikation von Datensätzen ist einer der weitverbreitetsten Data Mining-Methoden in der Praxis.
Bei der Klassifikation wird ein Objekt (z.B. ein Kunde) anhand seiner Merkmale einer zuvor definierten Klasse zugeordnet, z.B. ob ein Kunde auf eine bestimmte Kampagne reagiert hat oder nicht.
Grundlage für die Klassifikation sind Datensätze, die verschiedene (unabhängige) Merkmale sowie eine (abhängige) Zielgröße enthalten. In unserem Beispiel ist die Zielgröße die Reaktion auf die Kampagne mit einem Kauf, also Kauf ja oder nein.
Die beschriebenen Daten werden auch als Trainingsdaten oder Trainingsmenge bezeichnet. Ziel der Klassifikation ist es, ein Modell zu trainieren, das neue Objekte gut vorhersagen kann.
In unserem Fall wären dies neue Kunden, die mit Hilfe von Modellen hinsichtlich ihrer Reaktion bewertet werden können. Für die Klassifikation wird häufig ein Entscheidungsbaumverfahren verwendet.
Prognose
Ziel der Prognose ist es, ein Scoring-Modell zur Prognose eines stetigen Wertes (z.B. Kundenwert oder Umsatz) zu erstellen. Dabei wird ein Modell erstellt, das die Beziehungen einer abhängigen Variablen (z.B. Kundenwert) und einer oder mehreren unabhängigen Variablen (Alter, Anzahl Bestellungen, Kundentyp etc.) untersucht.
Wie bei der Klassifikation, wird bei der Prognose der Beispieldatensatz (Trainingsdatensatz) dazu genutzt, um ein Modell zu trainieren, welches Vorhersagen in der Zukunft treffen kann. Anstatt Klassen, ermöglicht die Prognose eine Vorhersage von steigenden Werten wie Umsätzen, Kundenwerten etc.
Segmentierung (Cluster-Analyse)
Deskriptive Aufgaben hingegen fassen die in den Datensätzen enthaltenen Verhaltensweisen von Kunden oder Objekten zu Mustern zusammen. Bei der Gruppierung bzw. Segmentierung wird die gesamte Datenmenge in mehrere Teilmengen bzw. Segmente aufgeteilt. Ziel ist es, die Datenmenge anhand von Merkmalen in möglichst homogene Teilmengen zu unterteilen.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
Assoziation (Abhängigkeitsentdeckung)
Bei der Assoziationsanalyse werden Assoziations- und Sequenzanalysen eingesetzt. Häufigeren Einsatz finden diese Data Mining Verfahren bei Warenkorbanalysen. Dies ist besonders hilfreich, wenn keine Kennung über den Kunden herstellbar ist und lediglich die Bondaten zur Verfügung stehen.
Mit Hilfe der Assoziationsanalyse können Regeln aus Datensätzen erstellt werden, ohne dass eine Zielvariable angegeben werden muss. Eine Regel könnte lauten: Wenn Artikel A gekauft wird, wird auch Artikel B gekauft.
Eine Erweiterung der Assoziationsanalyse stellt die Sequenzanalyse dar. Hier wird nach zeitbezogenen Assoziationsregeln gesucht, wie z.B.: In 80% der Fälle, in denen Artikel A gekauft wird, wird auch Artikel B und anschließend Artikel C gekauft.
Data Mining Algorithmen
Data Mining bietet verschiedene Verfahren und Algorithmen, um aus Daten wertvolle Muster zu erkennen. Ich habe Ihnen häufig verwendete Data Mining Algorithmen aufgelistet:
- Lineare Regression
- Logistische Regression
- Entscheidungsbäume
- ID3
- C4.5
- CART (Klassifikation und Regressions Entscheidungsbäume)
- CHAID (Chi-square)
- MARS
- Support Vector Machine (SVM)
- K-Nearest Neighbor
- Clustering Algorithmen
- K-Means
- DB-Scan
- Self Organizing Maps
- Hierarchisches Clustering
- Random Forest
- Gradient Boosted Trees:
- künstliche Neuronale Netze
- Feed forward neural networks
- Recurrent Neural Networks (RNN)
- viele weitere
- Recommernder Systeme
- Item Based Collaborative Filtering
- Content Based Collaborative Filtering
- Hybrid Collaborative Filtering
- ALS
- Assoziations Analysen
Anwendungsbeispiele von Data Mining
Data Mining wird in vielen Bereichen von Forschung und Wirtschaft eingesetzt und bietet für die Zukunft ein hohes Anwendungspotenzial. Anwendungsbeispiele finden sich im Customer Relationship Management (CRM), im Finanzsektor für Banken und Versicherungen, in der Telekommunikationsbranche, in der Produktion, in der Logistik sowie im E-Commerce. Im Folgenden wird auf die einzelnen Anwendungsbereiche näher eingegangen:
Data Mining im Marketing und CRM
Im Marketing und CRM kann Data Mining häufig branchenübergreifend sowohl in B2C- als auch in B2B-Geschäftsmodellen eingesetzt werden. Hier wird insbesondere das historische Kundenverhalten genutzt, um Prognosen für das zukünftige Kaufverhalten abzuleiten. So kann individuell auf Kundenbedürfnisse eingegangen werden.
Häufig fällt hier der Begriff „Personalisierung im Marketing“, also die kundenindividuelle Kommunikation mit jedem einzelnen Kunden. Dies kann nur durch eine starke Automatisierung und entsprechende Data Mining Methoden erreicht werden. Unternehmen können nicht selten durch Data Mining in ihren Marketingkampagnen langfristige Umsatzsteigerungen von 5-15% erreichen.
Handel und E-Commerce
Im Handel und E-Commerce ist Data Mining mit etlichen Anwendungsfällen vertreten. Hier sind besonders folgende Anwendungen interessant:
- Customer Lifetime Value Vorhersagen
- Cross- und Up-Selling Optimierung
- Warenkorbanalysen
- Absatz- und Bedarfsprognosen
- Preisoptimierung
- Recommender Systeme (Empfehlungssysteme)
- Kampagnenoptimierungen
- Kundensegmentierungen
Banken und Versicherungen
Vertragsbasierte Geschäftsmodelle haben häufig ähnliche Herausforderungen wie Unternehmen aus dem Handel und E-Commerce. Sie wollen die Kundenbeziehung profitabler machen und besser auf die Kundenbedürfnisse eingehen. Folgende Anwendungen werden häufig eingesetzt:
- Tarifwechsel-Prognosen
- Next Best Offer
- Fraud Prediction
- Kreditlimit-Optimierung
- Absatz- und Bedarfsprognosen
- Kundensegmentierungen
- Kundenabwanderungsprognose (Churn Prediction)
Energieversorger und Telekommunikation
Auch bei den Energieversorgern und in der Telekommunikationsbranche kann Data Mining eingesetzt werden, um das Kundenverhalten zu analysieren und damit Marketingkampagnen zu optimieren. Häufig kommen hierbei Anwendungsfälle wie Kundenabwanderungsprognosen, Next-Best-Offer Prognosen und Kundensegmentierungen zum Einsatz.
Medizin
In der Medizin kann Data Mining insbesondere dabei helfen, unstrukturierte Daten wie Bilder zu analysieren und dabei Muster zu erkennen. So haben Ärzte und Wissenschaftlicher die Möglichkeit, Krankheiten schneller oder mit einer höheren Genauigkeit zu identifizieren.
Produktion
Ein großes Themengebiet von Data Mining ist die Vorhersage von Maschinenausfällen. Häufig wird hier auch von Predictive Maintenance gesprochen, was in Deutsch sowas wie „vorausschauende Wartung“ bedeutet.
Logistik
Auch in der Logistik kann Data Mining eingesetzt werden, um Geschäftsprozesse und Lieferketten zu optimieren. Folgende Anwendungsfälle gibt es in der Logistik:
- Routenoptimierung
- Prognose von logistischen Bewegungen
- Prognose von Nachfrage
- Erkennen von Zusammenhängen in Versorgungsketten
Data Mining Prozess CRISP-DM
Im Jahr 2000 wurde mit dem CRISP-DM-Modell ein einheitlicher Standard für Data Mining Prozesse geschaffen. Grundlegendes Ziel des CRISP-DM-Modells ist es, Unternehmen einen standardisierten, branchen-, software- und anwendungsunabhängigen Prozessablauf für Data Mining zur Verfügung zu stellen.
Die ursprüngliche Veröffentlichung zum CRISP-DM-Modell finden Sie hier.
Ergebnisse des Data Minings sollen durch das CRISP-DM-Modell schneller und präziser zur Verfügung gestellt werden. Im Folgenden wird der CRISP-DM dargestellt, dieser ist in sechs Schritte unterteilt:
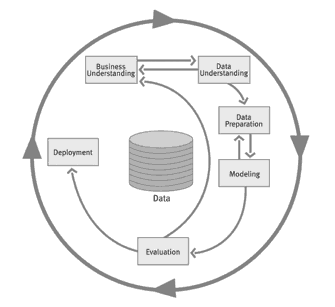
- 1. Phase: Business Understanding (Aufgabendefinition)
- 2. Phase: Data Understanding (Auswahl der relevanten Datenbestände)
- 3. Phase: Data Preparation (Datenaufbereitung)
- 4. Phase: Modeling (Auswahl und Anwendung von Methoden)
- 5. Phase: Evaluation (Bewertung und Interpretation der Ereignisse)
- 6. Phase: Deployment (Anwendung der Ergebnisse)
Die einzelnen Phasen sowie die Iterationen der einzelnen Phasen dieses Modells werden je nach Problemstellung unterschiedlich gewichtet. Jede Phase dieses Modells spielt eine entscheidende Rolle für den Erfolg eines Projektes. Die Abbildung zeigt, dass das CRISP-DM-Modell einen Kreislauf darstellt und somit iterativ ist.
Wer im Detail über den CRISP-DM-Prozess erfahren will, kann dies in diesem Artikel von mir tun.
Data Mining Tools und Programmiersprachen
Am Markt gibt es etliche Data Mining Tools und Softwareanbieter. Dieser Markt ist durch den Data Science Boom in den letzten Jahren extrem gewachsen. Dadurch haben sich auch Script- und Programmiersprachen entwickelt, mit denen sich Data Mining Modelle erstellen lassen.
Data Mining Tools
Dementsprechend gibt es verschiedene Data-Mining-Werkzeuge und Programmier- bzw. Skriptsprachen, die zur Mustererkennung in Daten verwendet werden können. Im Folgenden werden die bekanntesten Tools vorgestellt.
KNIME
KNIME steht für „Konstanz Information Miner“ und ist eine kostenlose Open Source Analytics Plattform. Das Tool stellt verschiedene Komponenten aus maschinellem Lernen und Data Mining zur Verfügung. Die Analyse findet auf einer grafischen Oberfläche statt und bietet hier eine visuelle Möglichkeit Daten zu verarbeiten. Dadurch sind kaum Programmierkenntnisse nötig, wodurch für den Einstieg in das Themenfeld Data Science gut geeignet ist.
Viele Schnittstellen zu verschiedensten Datenbanken, Big Data Systemen oder Cloudspeichern, machen die Software zu einem guten Werkzeugkasten für jeden Data Scientist. Teilweise wird das Data Mining Tool auch für verschiedenste ETL genutzt, wobei der Fokus stark auf den analytischen Fähigkeiten liegt. Wer KNIME professionell im Unternehmen nutzen möchte muss dennoch eine Lizenz kaufen, da für die regelmäßige Ausführung (Deployment), ein bestimmter Server benötigt wird.
Rapidminer
Auch RapidMiner ist ein Data Mining Tool, was über eine grafische Oberfläche bedient wird. Die Software wurde 2001 am Lehrstuhl für künstliche Intelligenz an der Technischen Universität Dortmund entwickelt. Das Tool wird häufig in der Forschung, an Hochschulen aber auch bei wirtschaftlichen Anwendungen genutzt.
Data Mining mit Programmiersprachen
R
Die R ist eine Open Source Programmiersprache für statistische Berechnungen, Data Mining und die Erstellung von Grafiken. R verfügt über eine extrem große Anzahl von statistischen Bibliotheken und verschiedensten Algorithmen (Zeitreihen, Klassifikation, Regression, Assoziation) für Data Mining.

R wurde vor allem um das Jahr 2010 extrem häufig für Data Mining Anwendungen genutzt, verlor ein bisschen an Popularität durch die Programmiersprache Python. An Hochschulen und in der Forschung wird R heute noch sehr häufig verwendet.
Python
Die Programmiersprache Python ist für maschinelles Lernen und Data Mining am populärsten. Python bietet alle wichtigen Methoden für die Verarbeitung von Daten und die Erstellung von Data Mining Modellen. Besonders durch das Thema Deep Learning hat Python an Nutzern dazugewonnen, denn viele Frameworks sind in Python geschrieben. Heute ist Python der Standard und jeder Data Scientist sollte Python beherrschen.
Statistik und Data Mining Methoden im Vergleich
Häufig werden Data Mining Methoden mit Statistik verglichen, die Unterschiede liegen jedoch vor allem in der Zielstellung, Datenmenge und der Berechnung.
| Statistik | Data Mining | |
|---|---|---|
| Datenmenge | kleine Datenmengen mit Fallzahl von 30 | größere Datenmengen bis hin zu Big Data |
| Übertragbarkeit | Schlussfolgerungen erfolgen anhand einer Stichprobe der Grundgesamtheit | Grundgesamtheit existiert oft nicht Stichprobe ist nicht definiert Datenbestände ändern sich ständig |
| Berechnung | Auf dem Papier und mit Taschenrechner möglich | Computer oder Server |
| Voraussetzungen | Es muss sehr genau geprüft werden welches Verfahren zum Einsatz kommt. | Data Mining Methoden sind nicht mehr theoretisch begründet und daher an den Daten verprobt. |
| Zielstellung | Testen von Hypothesen | Generieren von Hypothesen |
Data Mining und Big Data
Der Begriff Data Mining wird häufig im Zusammenhang mit Big Data verwendet. Diese Begriffe haben jedoch nicht die gleiche Bedeutung.
Big Data bezieht sich auf die Verarbeitung sehr großer Datenmengen, die sich mit den herkömmlichen Methoden nicht aufbereiten lassen. Es geht eher um die Plattform, die die Verarbeitung großer Datenmengen ermöglicht.
Die Data-Mining-Technik wird häufig auf große Datenmengen (Big Data) angewendet, da durch die große Datenmenge die herkömmliche Analyse von Daten kaum noch sinnvoll ist. Dabei lässt sich Data Mining einsetzen, um beispielsweise Muster zu erlernen und anschließend Vorhersagen für die Zukunft zu treffen.
Ein weiterer Vorteil von großen Datenmengen ist, dass die Data Mining Methoden oft deutlich besser funktionieren, wenn viele Beispieldatensätze für das Training der Modelle zur Verfügung stehen.
Unterschied zwischen Big Data und Data Mining
Folgende Tabelle erklärt den Unterschied zwischen Big Data und Data Mining:
| Data Mining | Big Data |
| Identifiziert und extrahiert relevante Informationen und Muster aus kleinen oder großen Datensätzen. | Sammeln, speichern und verarbeiten von großen Datenmengen. |
| Nutzt verschiedene Techniken der künstlichen Intelligenz und des maschinellen Lernens. | Durch die enorme Größe der Daten ist es unmöglich, diese auf herkömmlicher Soft- und Hardware zu halten. Big Data arbeitet auf verteilten Infrastrukturen (Big Data Technologie). |
| Liefert konkrete Resultate aus Analysen und Vorhersagemodellen. | Spezielle Technologie und Methoden werden benötigt, um die Menge der Daten zu verarbeiten. |
| Erstellt Prognosen, Vorhersagen von Wahrscheinlichkeiten und Segmentierungen. | Big Data dient als Eingabe für Data Mining und maschinelles Lernen. |
| Transformiert Informationen in Wissen und konkrete Handlungsempfehlungen. | Speichert Daten, um diese für Business Anwendungen oder Systeme aufzubereiten. |
Zusammenfassung
Data Mining hilft, Muster und Zusammenhänge in großen Datenmengen zu erkennen. Der interdisziplinäre Ansatz nutzt dazu Methoden aus der Statistik, der Informatik und dem maschinellen Lernen. In der Praxis lassen sich mit verschiedenen Data-Mining-Methoden präzise Vorhersagen für die Zukunft treffen oder Trends und Anomalien frühzeitig erkennen.
Das hilft Unternehmen, bessere Entscheidungen auf Basis von Daten zu treffen. So können Kundenbedürfnisse frühzeitig erkannt, Marketingkampagnen darauf abgestimmt und damit der Umsatz gesteigert werden.
Data Mining verwendet Methoden der Informatik und Statistik, um interessante Datenmuster in großen Datenmengen zu identifizieren. Der Prozess ist analytisch und die verwendeten Verfahren stammen häufig aus den Bereichen der künstlichen Intelligenz und des maschinellen Lernens.
Grundsätzlich lassen sich die Methoden des Data Mining in vier Gruppen einteilen:
Indem Muster in den Datenmengen eines Unternehmens durch Data Mining identifiziert werden, lassen sich daraus konkrete Handlungsempfehlungen ableiten. So unterstützen wir beispielsweise das Marketing- oder Vertriebsteam dabei:
· Kundenbedürfnisse zu verstehen
· Das Kaufverhalten der Kunden einzuschätzen
· Trends und Anomalien frühzeitig zu erkennen
· U.v.m.
Der Knowledge Discovery in Data Bases (KDD) ist ein Prozess, welcher sich mit der Wissensentdeckung in Datenbanken beschäftigt. Der Unterschied zum Data Mining liegt darin, dass Data Mining als Teilprozess in dem umfassenden Prozess der KDD zu sehen ist.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte









