


Die Identifizierung und Analyse großer Textmengen stellt einen wichtigen Antreiber für eine Vielzahl unternehmensrelevanter Entscheidungen dar. Grund ist der hohe Erkenntnisgewinn, der durch Analyse dieser Textmengen entsteht. Da die Extraktion von Wissen jedoch oftmals schwierig und zeitaufwendig ist, vernachlässigen viele Unternehmen diesen Bereich.
Durch fortschrittlichste Technologien zur Verarbeitung natürlicher Sprache auf Basis von maschinellem Lernen gestaltet sich die Analyse von Texten und der damit verbundene Erkenntnisgewinn jedoch immer einfach.
Im nachfolgenden Text wird Ihnen erklärt was Textklassifikation ist, wie sie funktioniert und welche Anwendungsbereiche für Textklassifikation bestehen.
Das Wichtigste auf einen Blick:
- Textklassifikation ist eine Methode von maschinellem Lernen und beschäftigt sich mit der Analyse und Strukturierung und Kategorisierung großer Textmengen
- Textklassifikation hilft vor allem in Bereichen wie der Echtzeit-Analyse, Skalierbarkeit des Unternehmens und der Vereinheitlichung unternehmensrelevanter Kriterien
- Regelbasiere Systeme, Machine Learning basierte Systeme und Hybride Systeme tragen zur automatisierten Textklassifikation bei
- Die Erkennung von Kundenbeschwerden, Automatisierung des Kundensupports oder die Analyse von Kundenmeinungen sind wesentliche Anwendungsgebiete von Textklassifikation
- Neben dem Bezug relevanter Daten stellt die Wahl eines passenden Tools einen wichtigen Faktor zur Erstellung eines Klassifikators dar
Was ist Textklassifikation?
Textklassifikation ist eine Methode des maschinellen Lernens, um große Textmengen vordefinierten Kategorien zuzuweisen. Dabei lässt sich Textklassifikation verwenden, um jegliche Arten von Texten zu strukturieren und organisieren. Wissenschaftliche Dokumente, medizinische Studien oder Texte des Webs lassen sich mithilfe von Textklassifikation strukturiert aufbereiten.
Beispielsweise lassen sich Artikel unterschiedlichen Themen zuordnen. Zudem besteht die Möglichkeit, dass man Kundenbewertungen nach Stimmung und Zufriedenheit kategorisiert, sodass sich Mitarbeiter zuerst mit dringlichen Anfragen beschäftigen können.
Auch ChatGPT oder Google Bart nutzen Textklassifikationen, gehören aber zum Bereich Large Language Model.
Warum ist Textklassifikation wichtig?
Schätzungen zufolge sind etwa 80% aller Informationen unstrukturiert. Dabei stellen Texte einen Großteil dieser unstrukturierten Daten und Informationen dar. Dadurch, dass Texte oftmals unübersichtlich sind, stellt die Organisation und Strukturierung von Texten einen zeitaufwendigen Faktor dar. Somit nutzt eine Vielzahl der Unternehmen nicht ihr volles Potenzial aus, da man vorliegende Daten- und Textbestände nicht ausreichend analysiert.
Mithilfe von Textklassifikation auf Basis von Machine Learning lässt sich dieses Potenzial ausschöpfen. Textklassifikation bietet dem Nutzer bzw. Unternehmen die Möglichkeit, verschiedenen Arten von Texten wie beispielsweise Texten sozialer Medien, E-Mails, Umfragen oder vielen weiteren Anwendungsgebieten, automatisch zu strukturieren. Anhand dieser strukturierten Texte lassen sich i weiteren Verlauf wesentliche Geschäftsentscheidungen einfacher ableiten. Zu den wesentlichen Gründen, maschinelles Lernen zur Textklassifikation zu nutzen, gehören:
- Echtzeit-Analyse: Durch die derzeitige Schnelllebigkeit des Internets und der damit verbundenen Dynamik, müssen Unternehmen oftmals extrem schnell auf Marktveränderungen oder Unternehmenserwähnungen reagieren. Durch eine auf Basis von maschinellem Lernen getätigte Analyse in Echtzeit hat das Unternehmen einen sofortigen Überblick über verschiedene Aktivitäten und kann in Echtzeit agieren.
- Vereinheitlichung von Kriterien: Ein Textklassifizierungsmodell auf Basis von Machine Learning agiert weitaus präziser als es jeder Mensch tut. Da im Bereich von Unternehmensentscheidungen oftmals einer Verzerrung durch menschliche Fehler wie Müdigkeit, fehlende Konzentration oder Langeweile auftritt, ist es hilfreich Modelle auf Basis von Machine Learning zu nutzen. Machine Learning zeichnet sich vor allem dadurch aus, da ein solches System vollkommen objektiv handelt und keine Verzerrung bei der Wahl von Kriterien stattfindet.
- Skalierbarkeit: Da eine manuelle Textklassifikation oftmals sehr mühselig und arbeitsaufwendig ist, bietet es sich an, auf maschinelles Lernen zurückzugreifen. Dank maschinellem Lernen können große Mengen an Umfragen, Kommentaren oder E-Mails binnen weniger Sekunden analysiert werden. Dadurch kann das Unternehmen verschiedenen Anforderungen gerecht werden und die Skalierbarkeit des Unternehmens steigern.
Wie funktioniert Textklassifikation?
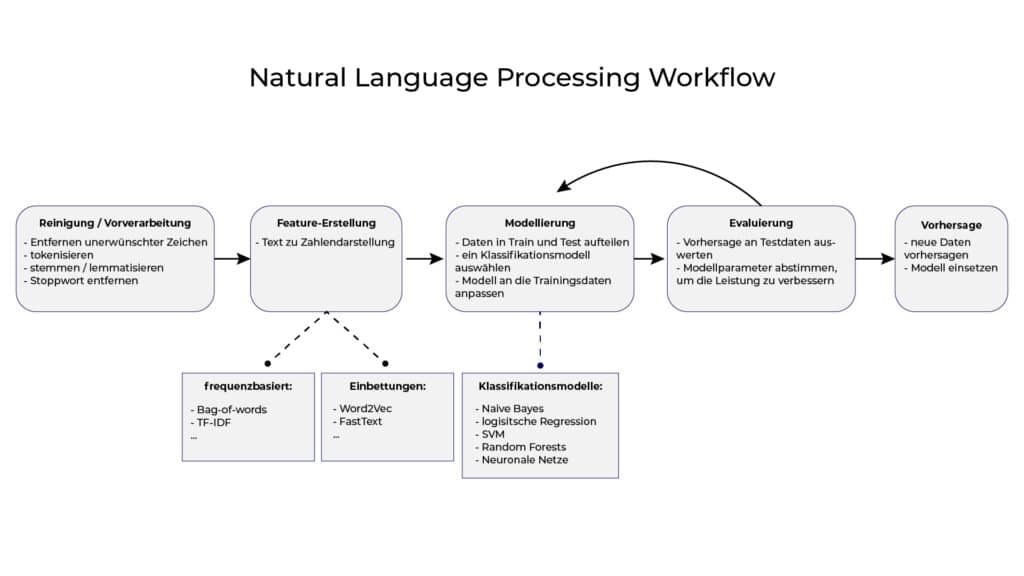
Innerhalb der Praxis lässt sich Textklassifikation auf verschiedenen Arten umsetzen. Einerseits lässt sich Textklassifikation automatisiert und andererseits manuell ausführen. Zwar bietet die manuelle Analyse von Texten oftmals präzise Ergebnisse, so ist die Art der Textklassifikation jedoch ziemlich zeitaufwendig.
Um riesige Textdateien daher schneller zu analysieren, bietet es sich an, auf Machine Learning– Algorithmen zuzugreifen. Diese agieren nicht nur schneller, sondern sind in ihrer Arbeit meist wesentlich genauer und kostengünstiger. Zur automatisierten Textklassifikation gibt es eine Vielzahl an Möglichkeiten. Grundsätzlich lassen sich jedoch drei Arten der automatisierten Textklassifikation nennen:
| Art | Merkmale |
|---|---|
| Ruled-based systems | Klassifizieren Texte in organisierte Gruppen, indem handgefertigte linguistische Regeln angewendet werden. Regelbasierte Systeme sind jedoch zum einen zeitaufwendig und zum anderen setzt die Umsetzung ein gewissen Fachwissen voraus. |
| Machine Learning based systems | Anstatt die Textklassifikation auf Basis vordefinierter Regeln zu gestalten, lernt die Textklassifikation auf Basis von Machine Learning jeweilige Klassifikationen auf Basis von frühen Beobachtungen eigenständig zu treffen. Textklassifikation auf Basis von maschinellem Lernen ist weitaus genauer als die vom Menschen selbst erstellten Regeln im Rahmen von Ruled-based Systemen. |
| Hybrid Systems | Hybride Systeme stellen eine Mischung beider zuvor vorgestellten Systeme dar. Hybride Systeme kombinieren einen durch maschinelles Lernen trainierten Basisklassifikator mit einem regelbasierten System und die Genauigkeit und Aussagekraft zu verbessern. |
Welche Funktionen bietet Textklassifikation?
Textklassifikation lässt sich in unterschiedlichen Bereichen einsetzen. Vorwiegend wird die Klassifikation von Texten jedoch zur Organisation großer Textdokumente oder der Klassifizierung kurzer Text im Bereich von sozialen Netzwerken genutzt. Zu den Hauptaufgaben von Textklassifikation gehören:
Spracherkennung
Innerhalb der Praxis wird Textklassifikation oftmals zur Spracherkennung genutzt. Durch Spracherkennung lassen sich unterschiedliche Bereiche eines Unternehmens stark automatisieren. Beispielsweise können im Kundensupport verschiedenen Anliegen der Kunden automatisch erkannt werden, sodass diese im weiteren Schritt je nach Belangen an zur Verfügung stehende Mitarbeiter weitergeleitet werden können. Zudem lässt sich zur Analyse vorliegende Sprache nach Herkunft der Sprache identifizieren und unterscheiden. Somit können vor allem Kundenanfragen zu global agierenden Unternehmen von unterschiedlichen Mitarbeitern je nach Landessprache bearbeitet werden.
Erkennung von Absichten
Zu erkennen, was ein Kunde als nächstes tun möchte ist für jedes Unternehmen wahnsinnig hilfreich. Dies liegt primär daran, dass sich das Unternehmen dadurch auf entsprechendes Verhalten eines Kunden einstellen kann und gegebenenfalls Maßnahmen daraus ableitet. Aufgrund der Unterschiedlichkeit aller Kunden ist es meist für das Unternehmen nicht ersichtlich, ob ein Kunde die Absicht hat etwas zu kaufen, oder aber eine Beschwerde aussprechen möchte. Die Erkennung von Absichten durch die Analyse von Texten ist daher einer der wichtigsten Bereiche im Rahmen von Textklassifikation. Praxisbezogen werden dabei vor allem E-Mails oder Chatbot-Unterhaltungen analysiert, sodass sich entsprechende Anliegen im Anschluss von der richtigen Abteilung bearbeiten lassen.
Sentimentanalyse
Die Sentimentanalyse gehört mitunter zu den bekanntesten Aufgabengebiete im Bereich von Textklassifikation. Sentimentanalyse beschäftigt sich vorrangig mit der Analyse von Stimmungen. Dadurch lassen sich Sentiment-Klassifikatoren in den unterschiedlichen Bereichen wie etwa der Analyse von Produktrezensionen, Analyse des Marktes, Untersuchung von E-Mails oder im Bereich des Kundensupports einsetzen. Mithilfe der Sentimentanalyse lassen sich die Gefühle sowie Emotionen des Verfassers analysieren.
Topic labeling
Im Rahmen der Organisation und Strukturierung großer Textdateien spielt die Textklassifikation zur Kennzeichnung von Themen eine große Rolle. In der Praxis geht es darum zu erkennen, mit welchen Themen sich ein Text beschäftigt und welche Überschrift zum jeweiligen Text passt. Somit spart das Unternehmen durch die automatisierte Analyse des Textes eine Menge an Zeit. Diese gewonnene Zeit lässt sich vom Unternehmen in andere wichtige Bereiche investieren.
In welchen Anwendungsbereichen dient Textklassifikation?
Textklassifikation findet in verschiedenen Unternehmensbereichen Anwendung. Sei es im Bereich des Marketings, der Erstellung von Produkten oder der Automatisierung von Geschäftsprozessen. Textklassifikation bietet aufgrund seiner großen Bandbreite an Funktionen in jeglichen Bereichen Vorteile. Im nachfolgenden Text werden Ihnen einige vielversprechende Beispiele von Textklassifikation aus der unternehmerischen Praxis aufgezeigt.
Benötigen Sie Unterstützung?
Mit Hilfe von Natural Language Processing gelingt die Textklassifikation.
Analyse der Kundenmeinungen
Oftmals nutzen Unternehmen den sogenannten Net Promoter Score, um die Stimmung des Kundenstamms zu analysiere. Dabei lassen sich diese Werte mithilfe einer vorliegenden Skala recht einfach messen. Hingegen ist es bei der Analyse von offenen Kundenmeinungen weitaus schwieriger, die Intention des Kunden zu erkennen. Mithilfe von maschinellem Lernen lassen sich quantitative Kundenmeinungen so analysieren, dass sich der Sinn sowie die Intention einer Meinung herauskristallisiert.
Zudem dienen solche Klassifizierungsmodelle, um aussagekräftige Muster innerhalb der Kundenmeinungen zu erkennen. Dadurch erfährt das Unternehmen beispielsweise, welche konkreten Produkte oder Dienstleistungen besonders gefragt sind, oder welche Verbesserungspotenziale bislang ungenutzt blieben.
Automatisierung im Bereich des Kundensupports
Im Bereich des Kundensupports kann Textklassifikation vorwiegend dazu dienen, dem Kunden ein ausgezeichnetes Kundenerlebnis zu kreieren. Dies wird vor allem dadurch erzielt, indem bestimmte Aufgaben des Unternehmens völlig automatisiert ablaufen. Dazu gehören beispielsweise die automatisierte Weiterleitung von Kundenanfragen an freie Mitarbeiter. Demzufolge verringert sich die Wartezeit eines Kunden drastisch, wodurch die Zufriedenheit dieses Kunden steigt.
Erkennung von Kundenbeschwerden
Um die Zufriedenheit des Kundenstamms langfristig zu wahren, sollten Kundenbeschwerden vom Unternehmen ernst sowie frühzeitig erkannt werden. Durch Textklassifikation auf Basis von maschinellem Lernen lassen sich riesige Textmengen untersuchen, um beispielsweise unzufriedenen Kunden zu erkennen. Vor allem Kunden, welche kurz vor der Kündigung stehen, sollten vom Unternehmen mit besonderer Dringlichkeit und Vorsicht beachtet werden.
Welche Ressourcen werden für Textklassifikation benötigt?
Um Textklassifikation erfolgreich zu gestalten, sind vor allem folgende Ressourcen wichtig:
Daten
Damit Algorithmen im Rahmen von maschinellem Lernen aussagekräftige Vorhersagen treffen können, müssen diese im Vorhinein mithilfe von Daten trainiert werden. Dabei wird der Algorithmus so trainiert, dass dieser zukünftigen Entscheidungen eigenständig ableiten kann.
Die benötigten Daten können einerseits aus internen Daten des Unternehmens stammen. Dazu eignen sich vor allem Daten, welche man durch genutzte Technologien der Nutzer generiert. Diese Daten lassen sich im Anschluss in eine CSV-Dabei exportieren, um das Training eines Klassifikators in Anschluss umzusetzen.
Zudem kann das Unternehmen ebenfalls auf externe Trainingsdaten zugreifen. Dazu eignen sich primär Daten des Webs oder weiteren öffentlich zugängliche Datenbestände wie beispielsweise:
- 20 Newsgroups: Dieser besteht aus rund 20000 Dokumenten, welche sich aus verschiedenen Themenbereichen zusammensetzen. Diese eignet sich bestens um sie zum Training eines Textklassifikators zu nutzen.
- Reuters News Dataset: Reuters News Dataset setzt sich aus rund 21000 Nachrichtenartikeln zusammen die sich aus einer großen Anzahl von über 130 Kategorien zusammensetzen.
- Amazon Product Reviews: Amazon Product Reviews greift auf rund 140 Millionen Produktbewertungen zu. Dieser riesige Datenbestand lässt sich vor allem zur Erstellung einer Sentimentanalyse nutzen.
- Spambase: Mithilfe von Spambase lassen sich vorwiegend Klassifikatoren im Rahmen von E-Mails bei der Erkennung von Spam-Mails kreieren. Spambase greift auf rund 4600 Mails zu, welche bereits nach Spam und Nicht-Spam identifiziert wurden.
Software
Nachdem der erste Schritt der Arbeit, die Aufbereitung von Daten, bewerkstelligt wurde, ist es im nächsten Schritt an der Zeit diese zum Training eines Algorithmus zu nutzen. Bei der Umsetzung kann das Unternehmen entweder auf Open-Source Software zugreifen oder konkrete Tools nutzen. Zu den beliebtesten Möglichkeiten zur Erstellung eines Textklassifikators gehören:
- Python: Aufgrund der großen Community und der großen wissenschaftlichen Bibliotheken gehört Python mit zu den bekanntesten und beliebtesten Programmiersprachen für Entwickler und Datenwissenschaftler. Zu den wichtigsten Bibliotheken im Bereich von Machine Learning gehört Scikit-learn. Es bietet eine Vielzahl an Algorithmen und gestaltet sich in der Arbeit einfach und effizient bei der Erstellung eines Textklassifikators.
NLTK ist eine weitere beliebte Bibliothek zur Verarbeitung natürlicher Sprache. Diese Bibliothek bietet dem Anwender eine große Menge nützlicher Werkzeuge und Anwendungen zur Erstellung eines Textklassifikators. Zu den Hauptaufgaben gehören dabei die Aufteilung von Absätzen in Sätze, Unterteilung von Wörtern nach Sinn oder das Erkennen von Wortarten. Weitere beliebte Bibliotheken sind:
- Java: Java stellt eine weitere Programmiersprache zur Erstellung von Machine Learning-Algorithmen im Rahmen der Textklassifikation dar. Neben Python greift Java ebenfalls auf eine riesige Community drauf zu und bietet eine Vielzahl an Open-Source-Bibliotheken zur Erstellung von Machine Learning-Algorithmen. CoreNLP ist eines der beliebtesten Frameworks für Natural Language Processing. CoreNLP bietet ein großes Fundament nützlicher Anwendungen zum Verständnis und der Verarbeitung natürlicher Sprache. Dazu gehören vor allem Textparser, Part-of-Speech Tagger oder Named Entity Recognizer.
OpenNLP und Weka sind weitere beliebte Bibliotheken, wenn es um die Verarbeitung natürlicher Sprache geht. OpenNLP bietet eine große Bandbreite linguistischer Analysewerkzeuge, die vor allem Tokenisierung, Satzsegmentierung, Part-of-Speech-Tagging oder Parsing nützlich sind. Weka hingegen hat den Vorteil, dass dem Nutzer eine grafische Benutzeroberfläche angeboten wird, wodurch der Nutzer bestimmte Algorithmen direkt für einen Datensatz anwenden kann.
Weitere:
- R: R gilt derzeit als eine der beliebtesten Programmiersprachen. Dies liegt vorwiegend daran, dass R eine weitreichende Auswahl für Aufgaben im Bereich von Textklassifizierung bietet. Besonders zu erwähnen ist Caret. Caret bietet eine große Menge an Werkzeugen, wenn es um die Erstellung von Machine Learning Algorithmen geht.
Zudem biete es eine Schnittstelle zur Verwendung weiterer nützlicher Werkzeuge zur Vorverarbeitung von Texten, Merkmalsauswahl oder der Optimierung verschiedener Modelle. Mlr ist im Rahmen von R ebenfalls zu erwähnen. Es bietet ein Gesamtpaket, welches auf Basis einer standardisierten Schnittstelle zu Anwendungen zur Nutzung von Klassifikations- und Regressionsalgorithmen bietet. - SaaS Textklassifikator APIs Open-Source Software hat auf jeden Fall seine Daseinsberechtigung und zeichnet sich durch zahlreiche Vorteile aus. Dennoch ist nicht zu vernachlässigen, dass sich eine Vielzahl von Open-Source Software meist an erfahrene Nutzer richtet. Gerade im Bereich von Textklassifikation setzen Programmiersprachen wie Python, Java oder R grundsätzlich ein gewisses Fachwissen im Umgang mit Machine Leaning Algorithmen voraus.
Damit ein Unternehmen dennoch die Möglichkeit hat, Textklassifikation innerhalb der Praxis anzuwenden, bietet es sich an, auf kostenpflichte SaaS-Plattformen zurückzugreifen. Zu den bekanntesten SaaS-Lösungen gehören: Google Cloud NLP, Amazon Comprehend, Aylien, IBM Watson, Lexalytics und Meaning Cloud.
Fazit
Für die Organisation und Strukturierung eines Unternehmens, kann Textklassifikation als großartiger Antreiber dienen. Damit sich Geschäftsentscheidungen auf Basis aussagekräftiger Informationen stützen, ist es hilfreich, ungenutzte Datenbestände und Texte zur Erkenntnisgewinnung zu nutzen und weitreichende Potenziale auszuschöpfen. Zudem gewährt die hohe Automatisierung durch Machine Learning-Algorithmen dem Unternehmen eine wertvolle Zeitersparnis mühseliger Aufgaben.
Interessiert Sie das Thema oder haben sie weiteren Fragen? Kontaktieren Sie mich gerne.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte







