


Viele unserer betreuten Kunden stehen vor ähnlichen Herausforderungen: mehr Databricks Use-Cases werden umgesetzt und neue Nutzer kommen auf die Plattform und somit steigen die monatlichen DBU-Kosten.
Genau hier setzt FinOps auf Databricks an – ein strategischer Ansatz, um Ausgaben transparent zu steuern, Ressourcen effizient zu nutzen und Governance zu automatisieren.
Aus unserer Erfahrung zeigt sich: Wer FinOps früh in seine Databricks-Plattform integriert, schafft die Grundlage für niedrige Kosten bei maximalen Nutzen (und vermeidet böse Überraschungen).
Alles, was Sie über FinOps wissen müssen, erfahren Sie in diesem Beitrag.
Was ist FinOps auf Databricks?
FinOps (kurz für Cloud Financial Operations) bedeutet, finanzielle Verantwortung in technische Teams zu bringen.
Auf Databricks geht es dabei um die systematische Steuerung und Optimierung von Compute-, Storage- und Job-Kosten – mit einem Ziel:
Mehr Transparenz, Effizienz und Governance im Data-&-AI-Betrieb.
Databricks liefert dafür die passenden Bausteine:
- System Tables für Nutzungs- und Kostendaten
- Cluster Policies und Budget Tools zur Governance
- Alerts und Dashboards für automatische Steuerung & Alerting
Was sind die Ziele von FinOps auf Databricks?
Das Ziel besteht darin, eine Balance zwischen Kostenbewusstsein und Handlungsfreiheit zu schaffen. Sie wollen ihre Entwickler nämlich nicht unnötig ausbremsen, sondern ihnen einen Rahmen definieren, in dem sie autonom handeln können.
Unternehmen wollen wissen, wer welche Kosten verursacht, wie sie Compute effizienter nutzen und welche Budgets oder Policies für nachhaltige Steuerung sorgen.
Die vier entscheidenden Säulen sind:
- Transparenz: Nutzung und Kosten nachvollziehbar machen
- Effizienz: Rechenressourcen optimal einsetzen
- Governance: Klare Richtlinien und Budgets etablieren
- Automatisierung: Technische Kontrolle durchsetzen
Machen Sie Databricks zu Ihrem Wettbewerbsvorteil
Als Databricks Select Partner unterstützen wir Unternehmen dabei, genau diese Balance zu erreichen – mit klaren Policies, wiederverwendbaren Templates und Dashboards, die technische und wirtschaftliche Perspektiven verbinden.
Databricks liefert dafür alle relevanten Bausteine – von System Tables für Kostendaten über Cluster Policies bis hin zu Budget Tools und automatisierten Alerts.
Typische Herausforderungen beim Skalieren
In vielen unserer Kundenprojekte zeigt sich: Wenn Databricks-Workspaces wachsen, steigen nicht nur die Datenmengen, sondern auch die Komplexität der Kostenkontrolle.
Gerade beim Übergang vom PoC in den produktiven Betrieb werden Effizienzprobleme sichtbar, die sich über verschiedene Ebenen der Architektur hinweg auswirken – von der Datenhaltung bis zur Compute-Konfiguration.
Effizienzprobleme entstehen meist auf drei Ebenen:
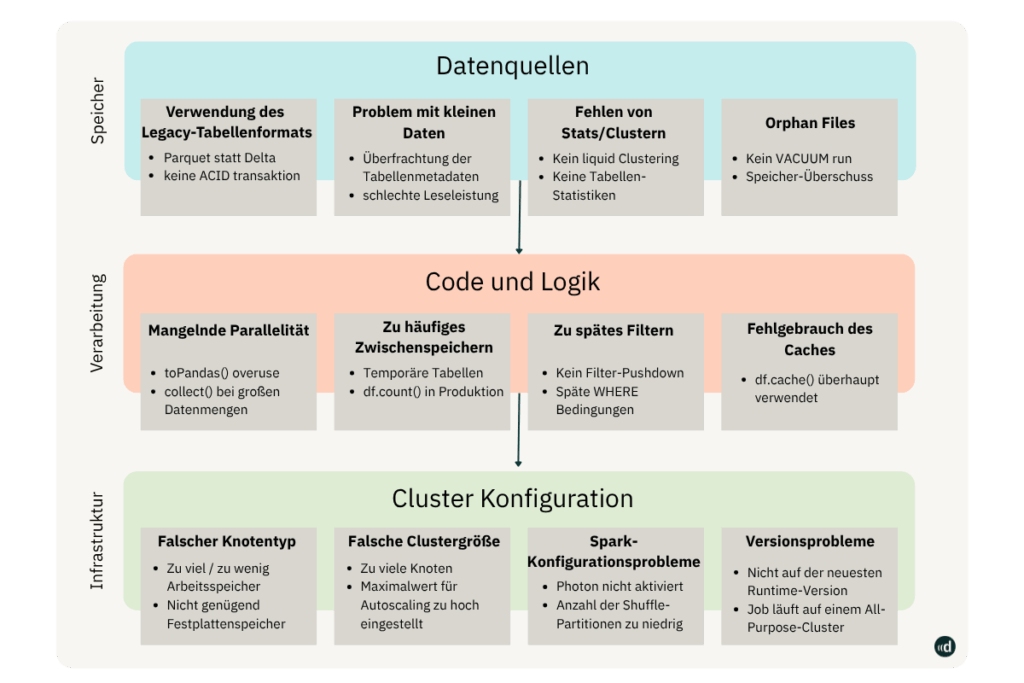
Die einzelnen Ebenen sehen wir uns nun im Detail an.
1. Data Sources – Ineffiziente Datenhaltung
Ein häufiger Kostenfaktor liegt bereits auf Storage-Ebene.
Unternehmen verwenden oft noch veraltete Tabellenformate (z. B. Parquet statt Delta), wodurch Transaktionen, Time Travel oder ACID-Funktionen fehlen.
Auch „Small Files“-Probleme oder fehlende Statistiken und Clustering führen dazu, dass Jobs länger laufen und unnötige Compute-Kosten verursachen.
Ein weiteres Muster sind verwaiste Dateien (Orphan Files) durch fehlendes VACUUM-Management – ein Klassiker bei wachsendem Datenvolumen.
Unsere Projekterfahrung zeigt: Ein klar definierter Data Lifecycle ist entscheidend. Automatisierte Bereinigung, konsistente Delta-Table-Standards und regelmäßige Analysen der Storage-Effizienz sorgen für nachhaltige Kostentransparenz.
2. Code and Logic – Unoptimierte Workloads
Auf der Verarbeitungsebene entstehen Kosten häufig durch suboptimale Abfragen und unnötige Persistenzschritte.
Ein verbreitetes Muster ist, dass Entwickler temporäre Tabellen oder df.count()-Operationen in produktiven Jobs verwenden, was zu dauerhaftem Rechenaufwand führt.
Auch fehlendes Predicate Pushdown – also das Filtern erst am Ende einer Query – kann die Kosten exponentiell erhöhen.
Ein weiteres Problem ist die falsche Nutzung von Cache, insbesondere bei großen Datensätzen, die nicht im Speicher gehalten werden sollten.
Hier setzen wir bei Kundenprojekten auf Code Audits und automatisierte Job-Analysen, um ineffiziente Transformationen frühzeitig zu erkennen und systematisch zu optimieren.
3. Cluster Configuration – Technische Ineffizienz
Die unterste Ebene betrifft die Infrastruktur.
Fehlerhafte Cluster-Einstellungen sind einer der größten Kostentreiber – etwa falsche Node-Typen, überdimensionierte Clustergrößen oder nicht aktiviertes Autoscaling.
Häufig laufen Jobs auf veralteten Runtimes oder auf All-Purpose-Clustern, obwohl dedizierte Job-Cluster deutlich günstiger wären.
Hier zeigt sich die Stärke eines aktiven FinOps-Ansatzes: Durch Cluster Policies, Timeouts, automatisiertes Rightsizing oder die Nutzung von Serverless Clustern werden Ressourcen präzise gesteuert und Kosten nachhaltig optimiert.
Zu unseren Databricks Use Cases
In unseren Projekten konnten wir damit regelmäßig über 30 % der Ausgaben reduzieren – ohne Einbußen bei Performance oder Stabilität.
Zusammenfassung
Die Herausforderungen beim Skalieren sind selten auf ein einzelnes Problem zurückzuführen.
Vielmehr entsteht Kostenineffizienz durch eine Kombination aus
- technischer Fehlkonfiguration,
- ungenutztem Lifecycle-Management
- und mangelnder Transparenz über Workloads.
Ein systematischer FinOps-Ansatz auf Databricks adressiert genau diese Punkte – über alle drei Ebenen hinweg.
Organisationsmodelle für FinOps: Zentralisiert vs. Förderiert
Wir beobachten zwei Ansätze bei unseren Kunden: zentralisiert oder föderiert.
Beide Modelle haben ihre Berechtigung, unterscheiden sich jedoch deutlich in Governance-Struktur, Geschwindigkeit und Verantwortlichkeiten.
1. Zentralisiertes Modell
In diesem Ansatz liegen alle FinOps-Aufgaben – also Policies, Budgets, Dashboards und Reporting – im zentralen Data Platform Team. Dieses Team definiert Standards, überwacht die Einhaltung von Budgets und setzt Richtlinien zur Compute-Nutzung oder Tagging-Struktur durch.
Der Vorteil liegt klar in der Kontrolle und Konsistenz: Entscheidungen werden zentral getroffen, Abweichungen können schnell erkannt werden, und die Plattform bleibt technisch homogen.
Allerdings zeigt sich in der Praxis, dass dieses Modell bei wachsender Zahl an Teams oder Use Cases schnell an seine Grenzen stößt. Fachbereiche verlieren Handlungsspielraum, und das zentrale Team wird zum Flaschenhals für Änderungen und Freigaben.
Lesen Sie auch:
2. Föderiertes Modell (Modern FinOps)
Das föderierte Modell hat sich in modernen Cloud-Architekturen zunehmend bewährt. Hier sorgt ein zentrales Framework für Governance und Standards – etwa durch vordefinierte Cluster Policies, Namenskonventionen oder Tagging-Regeln.
Die eigentliche Verantwortung für die Kosten liegt jedoch in den Teams selbst. Sie verwalten ihre Budgets, beobachten ihre Dashboards und reagieren eigenständig auf Auffälligkeiten oder Limitüberschreitungen.
Das zentrale Team agiert in diesem Modell nicht mehr als Controller, sondern als Enabler: Es stellt Tools, Templates und Monitoring-Mechanismen bereit, die Transparenz schaffen und Eigenverantwortung fördern.
Dieses Modell setzen wir in den meisten Projekten um – es kombiniert Transparenz mit Eigenverantwortung und skaliert mit der Organisation.
Best Practices aus unseren Projekten
Unabhängig vom Organisationsmodell gibt es zentrale Erfolgsfaktoren, die in allen FinOps-Initiativen eine entscheidende Rolle spielen.
Basierend auf unseren Projekten mit Unternehmen aus Branchen wie Telekommunikation, Energie und Industrie haben sich insbesondere fünf Best Practices als wirksam erwiesen:
1. Klare Tagging-Strategie
Ohne einheitliche Namenskonventionen und Tags verliert jede Kostenanalyse an Aussagekraft. Eine feste Taxonomie für Team, Projekt, Environment und Kostenstelle ist die Basis, um Kosten richtig zuzuordnen und Dashboards sinnvoll auszuwerten.
2. Automatisierung statt Kontrolle
Manuelle Freigaben oder nachträgliche Prüfungen sind fehleranfällig. Policies, Budgets und Alerts sollten über Infrastructure-as-Code verwaltet werden – beispielsweise mit Terraform und Databricks Asset Bundles. So bleibt Governance reproduzierbar und versioniert.
3. Transparenz für alle Rollen
FinOps funktioniert nur, wenn die richtigen Personen Zugriff auf die richtigen Informationen haben. Dashboards müssen sowohl IT- als auch Finanz- und Business-Perspektiven abbilden – von der technischen Ressourcennutzung bis zur Budgetentwicklung.
4. Proaktive Steuerung
Unternehmen, die FinOps erfolgreich leben, reagieren nicht erst auf Kostenüberschreitungen. Sie arbeiten mit Forecasts, Trendanalysen und Alerts, um frühzeitig gegenzusteuern. Wir integrieren in vielen Projekten automatisierte Benachrichtigungen über E-Mail, Teams oder Slack, sobald Schwellenwerte überschritten werden.
5. Kulturwandel statt Kontrolle
FinOps ist kein reines Finance- oder IT-Thema, sondern eine gemeinsame Verantwortung. Es geht darum, Bewusstsein für Kosten und Effizienz zu schaffen – von Data Engineers über Product Owner bis zum Management.
Erfolgreiche Teams etablieren eine Kultur, in der Kostenkennzahlen genauso selbstverständlich überwacht werden wie Performance- oder Qualitätsmetriken.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Das Zusammenspiel aus föderierter Organisation, Automatisierung und klarer Governance schafft die Grundlage für nachhaltige Kostentransparenz. FinOps wird damit nicht zu einem Kontrollmechanismus, sondern zu einem integralen Bestandteil der Plattformstrategie ein kontinuierlicher Verbesserungsprozess, der technische Exzellenz mit wirtschaftlicher Verantwortung verbindet.
In der Regel gilt: Optimieren, dann Operieren.
Optimieren: Kosten und Performance ausbalancieren
Sobald Transparenz sichergestellt ist, geht es um Optimierung.
Hier sehen wir bei Datasolut den größten Hebel: Die meisten Einsparpotenziale entstehen nicht durch harte Limits, sondern durch intelligente Automatisierung und sauberes Lifecycle-Management.
Dazu zählen:
- Auto-Termination & Scale-to-Zero
- Enhanced Autoscaling in DLT-Pipelines
- Timeout-Parameter zur Kontrolle von Rechenlast
- Policies für Node-Typen und Pflicht-Tags
Ebenso wichtig sind Query- und Job-Limits wie STATEMENT_TIMEOUT oder spark.databricks.execution.timeout, die unkontrollierte Rechenlast verhindern.
Ein weiterer zentraler Bestandteil ist das Policy Management:
Admins definieren Cluster Policies, etwa feste Node-Typen, GPU-Beschränkungen oder Pflicht-Tags wie cost_center oder team. Wir empfehlen dabei, Policies nicht zu restriktiv zu gestalten – zu enge Grenzen blockieren oft neue Use Cases.
Im Ergebnis entsteht eine Architektur, in der Compute- und Budgetregeln technisch durchgesetzt werden, ohne die Agilität der Teams zu mindern.
Bei einem Telekommunikationskunden konnten wir durch aktivierte Timeouts und Budget Alerts die monatlichen Kosten um 40 % senken.
Operate – Kontinuierlich steuern und automatisieren
Der letzte Schritt im FinOps-Lifecycle ist Operate – also kontinuierliche Steuerung.
Databricks bietet hier native Unterstützung mit:
- Budget Policies pro Workspace oder Projekt
- System Tables für Echtzeitverbrauch
- SDKs und Webhooks für automatische Reaktionen
Teams können Budgets pro Workspace oder Projekt definieren, den Verbrauch visuell nachverfolgen und Alerts bei Überschreitungen auslösen lassen.
So wird FinOps Teil des Plattformbetriebs – nicht als Kontrollmechanismus, sondern als integrierter Verbesserungsprozess.
Best Practices und Erfolgsfaktoren
In unseren Databricks-Projekten hat sich gezeigt: Fünf Faktoren sind entscheidend für den Erfolg von FinOps.
- Klare Tagging-Strategie – Einheitliche Taxonomie für Team, Projekt, Environment und Kostenstelle.
- Automatisierung – Budgets, Policies und Alerts sollten über Terraform oder Asset Bundles versioniert und verwaltet werden.
- Transparenz für alle Rollen – Dashboards müssen sowohl IT als auch Finance und Business adressieren.
- Proaktive Steuerung – Frühzeitige Alerts und Forecasts statt nachträglicher Kostenanalysen.
- Kulturwandel – FinOps ist keine reine Finance-Aufgabe, sondern ein gemeinsamer Prozess von Data, IT und Controlling.
Fazit
FinOps auf Databricks ist kein Sparprogramm – sondern ein strategischer Steuerungsansatz für moderne Datenplattformen.
Unternehmen, die FinOps aktiv umsetzen, profitieren von:
- Vollständiger Kostentransparenz
- Technischer Governance über Compute
- Automatisierter Steuerung und Forecasting
Wir bei Datasolut unterstützen Unternehmen dabei, FinOps als festen Bestandteil ihrer Databricks-Plattform zu etablieren – von der Implementierung der System Tables bis hin zur Entwicklung maßgeschneiderter Dashboards und Automatisierungen. Kontaktieren Sie uns jetzt.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte
FAQ – Die wichtigsten Fragen rund um FinOps schnell beantwortet
FinOps auf Databricks bezeichnet die systematische Steuerung und Optimierung von Cloud-Kosten innerhalb der Databricks-Plattform. Ziel ist es, Transparenz, Governance und Effizienz über alle Data- & AI-Workloads hinweg zu schaffen.
Mit zunehmender Nutzung von Databricks steigen auch die Kosten für Compute und Storage. FinOps sorgt dafür, dass diese Kosten kontrollierbar bleiben – durch klare Verantwortlichkeiten, automatisierte Budgets und technische Richtlinien.
Unternehmen profitieren von:
– vollständiger Kostentransparenz
– automatisierter Governance über Cluster und Jobs
– besserer Auslastung und Performance
– Forecasting und Budgetsteuerung in Echtzeit
Databricks stellt mit System Tables, Cluster Policies, Budgets und Alerts alle notwendigen Werkzeuge bereit, um Kostenanalysen, Automatisierungen und Governance zentral umzusetzen.
Als Databricks Partner begleitet Datasolut Unternehmen beim Aufbau eines ganzheitlichen FinOps-Frameworks – von der Einführung technischer Policies bis zur Entwicklung maßgeschneiderter Dashboards und Alerts.







