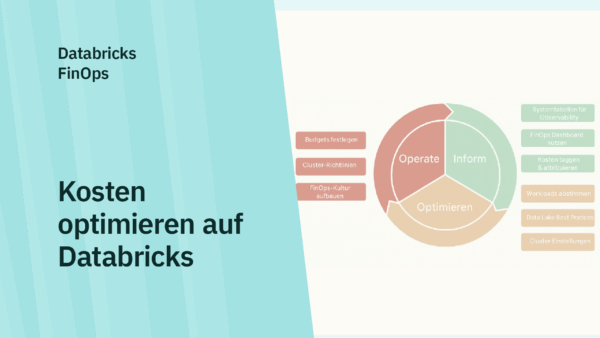
Das Databricks Kostenmodell basiert auf einem Pay-as-you-go Modell, deshalb ist es wichtig zu wissen, wie Sie die Ausgaben auf Databricks kontrollieren und die Kosten somit optimieren können.
In diesem Beitrag erfahren Sie Tipps, wie Sie die Kosten bei Databricks optimieren können.
Die Herausforderungen des Databricks-Zahlungsmodells
Die Verwendung von Databricks bedeutet einen weiteren Kostenpunkt in der IT-Abteilung. Sie müssen die neuen Rechnungsdaten in die bestehenden Cloud-Ausgaben integrieren. Falls Sie keine optimierte Methode gefunden haben, um diese Integration zu gewährleisten, findet ein neuer, zeitaufwendiger manueller Arbeitsaufwand statt.
Neben der Herausforderung der neuen Kostenstelle, gibt es weitere:
- Fehlender Ausgabeleitfaden: Databricks Kostenwarnfunktionen sind begrenzt und minimal. So passiert es schnell, dass Sie keinen Überblick über die Ausgabe haben.
- Zwei Kostenpunkte: Databricks Kostenmodell besteht sowohl aus der Rechenleistung in DBUs (Databricks Units) als auch aus den Kosten für den Server in der jeweiligen Cloud. Diese Aufteilung macht es schwer, die Gesamtkosten von Databricks zu beurteilen. Hier lohnt es sich ein Reporting auf Seiten des Cloudanbieters zu erstellen und die Warnfunktionen für Budgetüberschreitungen zu nutzen.
- Gründe für die Nutzung: Sie können Databricks sowohl für Data Engineering als auch Machine Learning und SQL-Projekte verwenden. Die Kosten unterscheiden sich je nach Bereich – somit ist es auch hier eine Kostenabschätzung erschwert.
Um die Kosten zu handeln, gibt es ein paar Tipps.
Wie können Sie die Kosten auf Databricks optimieren?
Zum einen gibt es die Möglichkeit Databricks als Community Edition zu verwenden. Diese Version ist kostenlos und eignet sich, um Ihr bestehendes Data Team zu schulen. Für komplexe Projekte eignet sich diese Version aufgrund fehlender/limitierter Features nicht.
Neben der light Version bietet Databricks eine 14-tägige kostenlose Probezeit für die Vollversion – danach rechnet Databricks die Nutzung zum normalen Preis ab. Es ist allerdings möglich, Vergünstigungen auf die Standart-Rate zu erhalten:
- Sie einigen sich vor Verwendung der Cloud-Plattform auf eine bestimmte Verbrauchsrate. Je größer diese Rate, desto größer der Rabatt.
- Verwenden Sie Spot Instances wenn möglich, um bis zu 90% Rabatt auf die Standart-Kosten zu erhalten.
Sie wissen nicht, wie Databricks Kosten kalkuliert? Dann sind Sie bei unserem Beitrag zum Kostenmodell von Databricks richtig!
Neben den Spar-Optionen die Databricks anbietet, ist es möglich durch geschickte Planung erheblich Kosten zu sparen. Wie, zeigen wir Ihnen!
Machen Sie Databricks zu Ihrem Wettbewerbsvorteil
Mit unserer Databricks-Beratung entwickeln Sie eine skalierbare Architektur, realisieren produktive Use Cases und befähigen Ihr Team nachhaltig.
5 Tipps, um Databricks Kosten einzusparen
Databricks bietet verschiedene Funktionen an – vom Streaming bis Machine Learning -, somit gibt es verschiedene Möglichkeiten, um Ausgaben gering zu halten.
1. Streaming
Cluster:
Lassen Sie Ihre Cluster nicht 24/7 laufen. Damit Real-Time Data Ingestion trotzdem funktioniert, supportet Databricks den Trigger: trigger(availableNow=True). Außerdem bietet Apache Spark die Möglichkeit, neue Daten von der Quelle als single micro-batch mit dem Befehl .trigger(once=true) durchzuführen.
Databricks hat einen Beitrag veröffentlicht, in dem Sie auf Streaming mit Hilfe eines Triggers genauer eingehen.
Indem Sie die Größe und Anzahl der Cluster auf Ihren Use Case abstimmen, sparen Sie viele Kosten. Die Cluster-Konfiguration ist flexibel und kann verschiedene Herausforderungen beinhalten. Achten Sie bei der Konfiguration auf folgende Punkte:
- Wer soll den Cluster verwenden? Ein Data Scientist oder Data Engineer?
- Welche Workloads sollen im Cluster ausgeführt warden? Batch-Aufträge oder analytische Aufgaben?
- Welche Service Level Bestimmungen sollen Sie einhalten und welches Budget haben Sie zur Verfügung?
Automatisches Skalieren:
Automatisches Skalieren findet häufig bei Standard-Streaming Workloads statt, obwohl sich das negativ auf Kosten auswirkt. Standard-Steaming wird automatisch die maximale Anzahl von Knoten anrechnen und sie während des Prozesses auf Maximal halten. Stattdessen bietet Databricks die Möglichkeit, Delta Live Tables (DLT) mit erweiterter Autoskalierung anzuwenden. DLT schaltet unzureichend ausgelastete Knoten proaktiv ab.
Databricks Blog-Post: Running Streaming Once a Day For 10x Cost Savings.
2. Cluster
In dem Sie All-Purpose von Job Clustern effektiv einsetzen, sparen Sie Kosten. Erwenden Sie teuren All-Purpose Cluster nur bei ad-hoc Analysen, Data Exploration oder Entwicklung. Für produzierende Jobs verwenden Sie Job Cluster.
Databricks Beratung
Aggressive Auto-Termination:
Verwenden Sie agressive Auto-Termination, bei All-Purpose Clustern. In 15 bis 30 Minuten sollten Sie das Cluster schließen.
Dasselbe gilt für Personal Compute: Auch hier sollten 15 bis 30 Minuten ausreichen.
Databricks Blog-Post: Best practices: Cluster configuration.
3. Laufzeit
Sie sollten Ihre Laufzeit regelmäßig aktualisieren und Gebrauch von neuen Funktionen, Fehlerbehebungen und Sicherheitspatches machen.
- Sind Sie schon zu DBR 7.x und Spark 3 gewechselt?
- Verwenden Sie die aktuelle LTS-Version?
- Verwenden Sie Photon?
Die Verwendung der neusten Updates und Funktionen wird Ihre Kosten drastisch senken.
4. Daten
Halten Sie die folgenden 5 Tips ein, um mit Ihren Daten möglichst sparsam umzugehen:
- Verwenden Sie Delta Lake, z.B. das Data Lakehouse
- Halten Sie Ihre Tabellen kompakt
- Verwenden Sie die Z-Reihenfolge
- Säubern Sie Ihre Tabellen regelmäßig
- Verwenden Sie Low Shuffle Merge und setzen Sie die Shuffle-Partitionen auf Auto
5. Cloud
Wenn Sie diese 5 Tipps befolgen, können Sie bei der Verwendung der Cloud Kosten sparen:
- Verwenden Sie Spot-Instances, wenn möglich
- Schutz vor zusätzlichen Kosten? Verwenden Sie Spot fall back on-demand
- Sie können Ihren VM-Verbrauch für nächstes Jahr abschätzen? Dann verwenden Sie Instance-Pools
- Achten Sie auf die regionsübergreifende Datenübertragung
- Verwenden Sie regionale VPC-Endpunkte auf AWS oder Private Link/Service-Endpunkte auf Azure.
Neben diesen Tipps bietet Databricks einen Kostenrechner an: Der DBU-Rechner. Mit dem Databricks Unit-Rechner können Sie besser nachvollziehen, wie sich einzelnen Faktoren (z.B. Speichergröße, Anzahl der Knoten) auf Ihre Gesamtkosten auswirken.
Hier ist der direkte Link zum Databricks-Rechner: Pricing Calculator
Fazit
Das Databricks Kostenmodell ist komplex und beinhaltet viele Stolpersteine mit versteckten Kosten. Daher lohnt es sich, die Verwendung von Databricks genau planen. Indem Sie wissen, wie viele Cluster Sie für Ihre Use Cases benötigen und wie groß diese sein müssen sparen Sie viele Databricks Units und somit echtes Geld.
Databricks selbst bietet Tipps zur Kostenoptimierung an und Sie können Ihre Kosten von einem Databricks-Rechner vorkalkulieren lassen.
Sie möchten mehr zum Thema Databricks erfahren? Als offizieller Databricks-Partner stehen wir Ihnen gerne beratend zur Seite! Kontaktieren Sie uns.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte