Die Entscheidung, ob Databricks Serverless Compute im bestehenden Workspace aktiviert werden sollte, ist für viele Unternehmen eine wichtige strategische Auswahl.
Die wichtigsten Punkte im Überblick zu Databricks Serverless Compute:
- Vollautomatisierte Compute-Option von Databricks, sekundenschnell startklar.
- Abrechnung nur für genutzte Ressourcen, keine Leerlaufkosten.
- Zwei Varianten: Performance-Optimized (schnell) und Standard (bis 70 % günstiger).
- Sicherheit durch isolierte Infrastruktur und Unity Catalog.
- Empfehlung: Aktivieren für Flexibilität, besonders bei DLT, LakeFlow und interaktiven Workloads.
Dieser Beitrag erklärt, wie Serverless in Databricks funktioniert, zeigt die Unterschiede zu klassischen Compute-Modellen auf und beleuchtet zentrale Kriterien wie Leistungsfähigkeit, Vorteile, Einschränkungen, Kosten und Sicherheitsaspekte.
Ziel ist es, eine fundierte Entscheidungsgrundlage zu schaffen – sowohl für den produktiven Einsatz als auch für explorative Szenarien. Abschließend geben wir eine praxisorientierte Empfehlung, ob und wann sich die Aktivierung von Databricks Serverless für Ihr Unternehmen lohnt.
Lesen Sie auch:
Lassen Sie uns starten!
Was bedeutet Serverless bei Databricks?
Serverless Compute von Databricks steht für eine vollautomatisierte, vom Anbieter verwaltete Infrastruktur. Im Gegensatz zu dem klassischen Ansatz müssen Nutzer hier weder Hardware konfigurieren noch komplexe Wartungen durchführen.
Databricks kümmert sich vollständig um Ressourcenmanagement und Optimierung – Anwender zahlen nur für tatsächlich genutzte Kapazitäten. Das bedeutet keine fixen Infrastrukturkosten, geringere Komplexität und maximale Effizienz.
Die folgende Grafik zeigt auf, dass das „Compute Plane“ beim Einsatz von Serverless einfach über Ihren Databricks Account erreichbar ist.
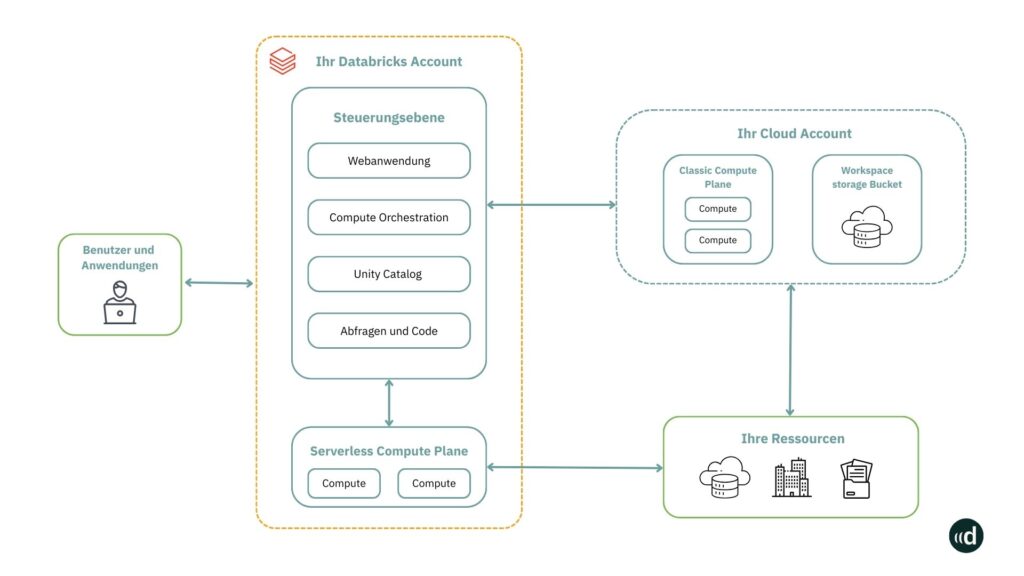
Hier sieht man, dass der Serverless Compute nicht in dem eigenen Cloud Account stattfindet, sondern bei Databricks. Durch Databricks Serverless erhalten alle Anwender eine integrierte Umgebung, um Abfragen durchzuführen, Pipelines zu erstellen und Modelle zu trainieren:
- Serverless Compute unterstützt bereits allgemein verfügbare Dienste wie Databricks SQL, Workflows, Notebooks und Delta Live Tables.
- Weiterhin bildet Databricks Serverless mit seinem „Elastic Compute Fabric“ die Grundlage moderner Data- und KI-Plattformen.
Bei dieser Methode werden Prozessorleistung, Arbeits- und Festplattenspeicher, je nach Bedarf, dynamisch erhöht oder reduziert. So sind Teams aus dem Data Engineering, Data Analytics, Data Science und Machine Learning in der Lage, flexibel auf strukturierte, semi-strukturierte und unstrukturierte Daten zuzugreifen.
Die folgende Grafik veranschaulicht diesen Sachverhalt:

Dabei stellt die Unified Governance sicher, dass die Compliance- und Sicherheitsrichtlinien stets eingehalten werden, ohne Nutzer in ihrer Arbeit einzuschränken.
Die verschiedenen Compute-Optionen im Überblick
Es gibt unterschiedliche Compute-Optionen für diverse Anwendungsfälle. Grundsätzlich unterscheidet man zwischen Classic-Compute und Serverless. Die folgende Tabelle gibt Aufschluss über die grundsätzlichen Eigenschaften:
Vergleich Serverless vs. Classic Compute
| Kriterium | Serverless Compute | Classic Compute |
| Ausführungsort | Databricks-Infrastruktur | Eigene Cloud-Umgebung |
| Verwaltung | Vollständig durch Databricks | Manuell oder automatisiert |
| Skalierung | Automatisch nach Bedarf | Manuell oder via Auto-Scaling |
| Infrastrukturzugriff | Kein direkter Zugriff | Volle Kontrolle (VMs, Konfig.) |
Databricks Serverless unterteilt sich nochmals in zwei Compute-Optionen:
- Performance-Optimized Serverless: Ideal für zeitkritische Workloads, mit sehr kurzen Startzeiten und doppelt so schneller Ausführung im Vergleich zu klassischen Optionen.
- Standard Serverless: Optimal für planbare ETL-Jobs. Hier sparen Unternehmen bis zu 70 % der Kosten im Vergleich zur Performance-Optimized-Version – ideal für budgetbewusste regelmäßige Aufgaben.
In der folgenden Tabelle sind die wesentlichen Unterschiede dargestellt:
| Serverless Optionen | Classic Compute | ||
| Performance-optimized | Standard | Klassische Jobs | |
| Startzeit | <50s (bald <10s) nicht in Rechnung gestellt, environment caching | 4-6 min nicht in Rechnung gestellt, environment caching | 4-6 min in Rechnung gestellt VMs + Library Installation |
| Geschwindigkeit | Üblicherweise 2x schneller als Classic Compute | Ähnlich Classic Compute | Üblicherweise langsamer als Performance-optimized, abhängig vom Setup der Infrastruktur |
| Übliche Workloads | Zeitkritische Anwendungen | Alle planmäßigen Jobs (inkl. ETL) | Alle planmäßigen Jobs (inkl. ETL) |
| Von Databricks verwaltete Infrastruktur | |||
Die Nutzung von Serverless muss auf Workspace-Ebene einmalig aktiviert werden. Dies geschieht in der Administrationskonsole des Workspaces über die Compute-Einstellungen.
Wichtig: Die Aktivierung von Serverless schließt die Nutzung klassischer Compute-Ressourcen nicht aus. Beide Betriebsmodelle – Serverless und klassische Cluster (All-Purpose oder Job Cluster) – können parallel verwendet werden, je nach Anwendungsfall.
Zum Vergleich: Bei All-Purpose Clustern erfolgt der Betrieb in der eigenen Cloud-Umgebung des Kunden. Hier definiert der Nutzer beim Anlegen eines Clusters manuell Parameter wie Instanztypen, Laufzeitumgebung, Netzwerkeinstellungen und Policies. Diese Cluster bleiben meist über längere Zeit aktiv und verursachen auch bei Nichtnutzung laufende Kosten. Sie eignen sich besonders für interaktive Workflows, explorative Datenanalysen oder kollaboratives Arbeiten.
Wir sind offizieller, zertifizierter Databricks Partner und finden die passende Lösung für Ihr Unternehmen. Kontaktieren Sie und für eine Databricks Beratung.
Job Cluster werden temporär für einen definierten Job gestartet und nach dessen Abschluss automatisch wieder beendet. Auch sie laufen in der Kundeninfrastruktur und müssen konfiguriert und verwaltet werden.
Serverless unterscheidet sich von beiden Varianten durch den vollautomatischen Betrieb: Compute-Ressourcen werden innerhalb weniger Sekunden dynamisch aus einem verwalteten Pool bereitgestellt – ohne Cluster-Konfiguration oder Infrastrukturpflege durch den Nutzer.
Kosten und Budgetierung
Auch im Bereich der Kosten und Budgetierung gibt es bei Databricks Serverless Änderungen. Zum einen wird eine Reduzierung der Gesamtbetriebskosten angestrebt. Außerdem bietet das sogenannte Tagging die Möglichkeit, Kosten direkt einer bestimmten Instanz zuzuordnen. Mit der Vergabe von Budgets haben Sie so die Kosten stets unter Kontrolle.
Hier kommen Sie zum allgemeinen Beitrag des Databricks Kostenmodells.
1. Reduzierung der Gesamtbetriebskosten (TCO)
Serverless konsolidiert Infrastruktur-, Betriebs- und DBU-Kosten (Databricks Units) in einer einzigen Abrechnung. Diese Vereinfachung reduziert nicht nur administrative Aufwände, sondern senkt auch die Gesamtbetriebskosten.
In der folgenden Grafik verdeutlichen wir diese Konsolidierung:
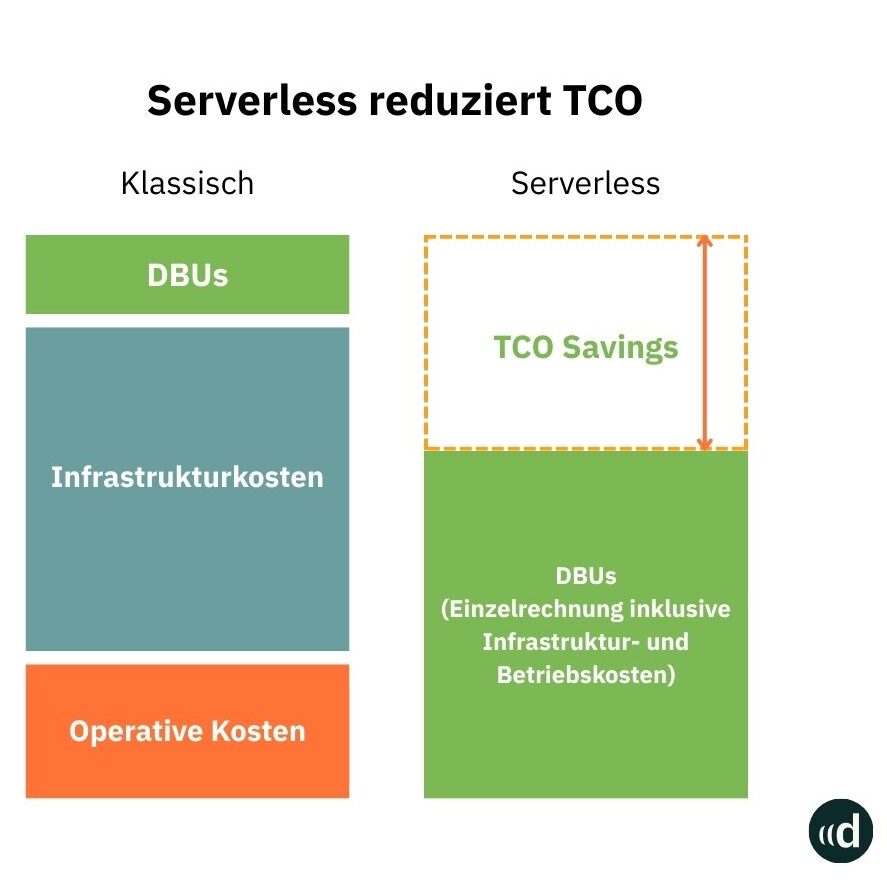
Databricks Serverless reduziert die Gesamtbetriebskosten dadurch, dass sowohl Infrastruktur- als auch operative Kosten reduziert werden. Dies geschieht durch die automatische Ressourcenverwaltung und Optimierung und weniger Overhead durch automatische Skalierung.
Die Abrechnung bei Serverless Compute erfolgt sekundengenau auf Basis der tatsächlichen Nutzung.
Das bedeutet: Es fallen nur Kosten an, wenn ein Job oder eine Abfrage aktiv ausgeführt wird. Leerlaufzeiten zwischen Aktivitäten verursachen keine Gebühren, da die Compute-Ressourcen in dieser Zeit nicht reserviert bleiben.
Im Vergleich zu klassischen All-Purpose Clustern kann dies erhebliche Kostenvorteile bringen – insbesondere bei unregelmäßiger oder kurzzeitiger Nutzung. Klassische Cluster laufen oft über längere Zeiträume hinweg und verursachen auch bei Inaktivität laufende Kosten für Compute-Instanzen und zugewiesene Speicher.
Im Gegensatz zu Serverless, bei dem nur die DBU-Kosten bei Databricks anfallen, entstehen bei Classic Compute auch Kosten für VMs im jeweiligen Hyperscaler-Account (z. B. Azure oder AWS).
Um einen fairen Vergleich zu erhalten, sollten die Kosten für die virtuelle Maschine in der Cloud daher ebenfalls berücksichtigt werden.
2. Kostentransparenz durch Budgetierung
Serverless von Databricks bietet mit der Tagging-Funktion eine präzise Zuordnung der Nutzungskosten. Durch die Möglichkeit, Kosten automatisiert Teams, Projekten oder Abteilungen zuzuordnen, behalten Unternehmen stets den Überblick über ihre Ausgaben.
Das Ergebnis:
- Bessere Planung durch klare Zuordnung der Kosten
- Vereinfachtes Reporting für die Finanzabteilung
- Vollständige Kostentransparenz und präzise Abrechnung
Achtung: Budgets verbessern Ihre Möglichkeiten zur Überwachung der Nutzung. Sie verhindern jedoch nicht die Nutzung oder die Entstehung von Kosten. Die tatsächliche Rechnung kann Ihre Budgetbeträge überschreiten.
3. Was ist günstiger? Übersicht der Kosten
In diesem Abschnitt möchten wir Ihnen kurz darstellen, welche Informationen Databricks bezüglich der Kosten von Serverless im Vergleich zum Classic Compute annimmt:
- Serverless – Performance-optimized: Vergleichbar mit „All purpose compute“
- Serverless – Standard: Bis zu 70% günstiger als Performance-optimized. (Vergleichbar mit On-Demand-Jobs im Classic Compute)
- Classic Compute: Kosten bleiben unverändert.
Achtung: Classic Compute kann bei optimierter Konfiguration (z.B. spot Azure Resource Management (ARM), aktueller Instanztyp) kostengünstiger sein als Serverless Standard!
Netzwerksicherheit
Ein zentraler Unterschied zwischen Serverless und klassischen Clustern liegt im Netzwerkmodell. Serverless-Compute läuft nicht in der Cloud-Umgebung des Kunden, sondern auf einer isolierten Infrastruktur, die vollständig von Databricks betrieben wird. Diese Umgebung ist von der Kundennetzwerkumgebung entkoppelt und verwendet eigene IP-Adressen, eigene Subnetze und eigene Sicherheitsrichtlinien.
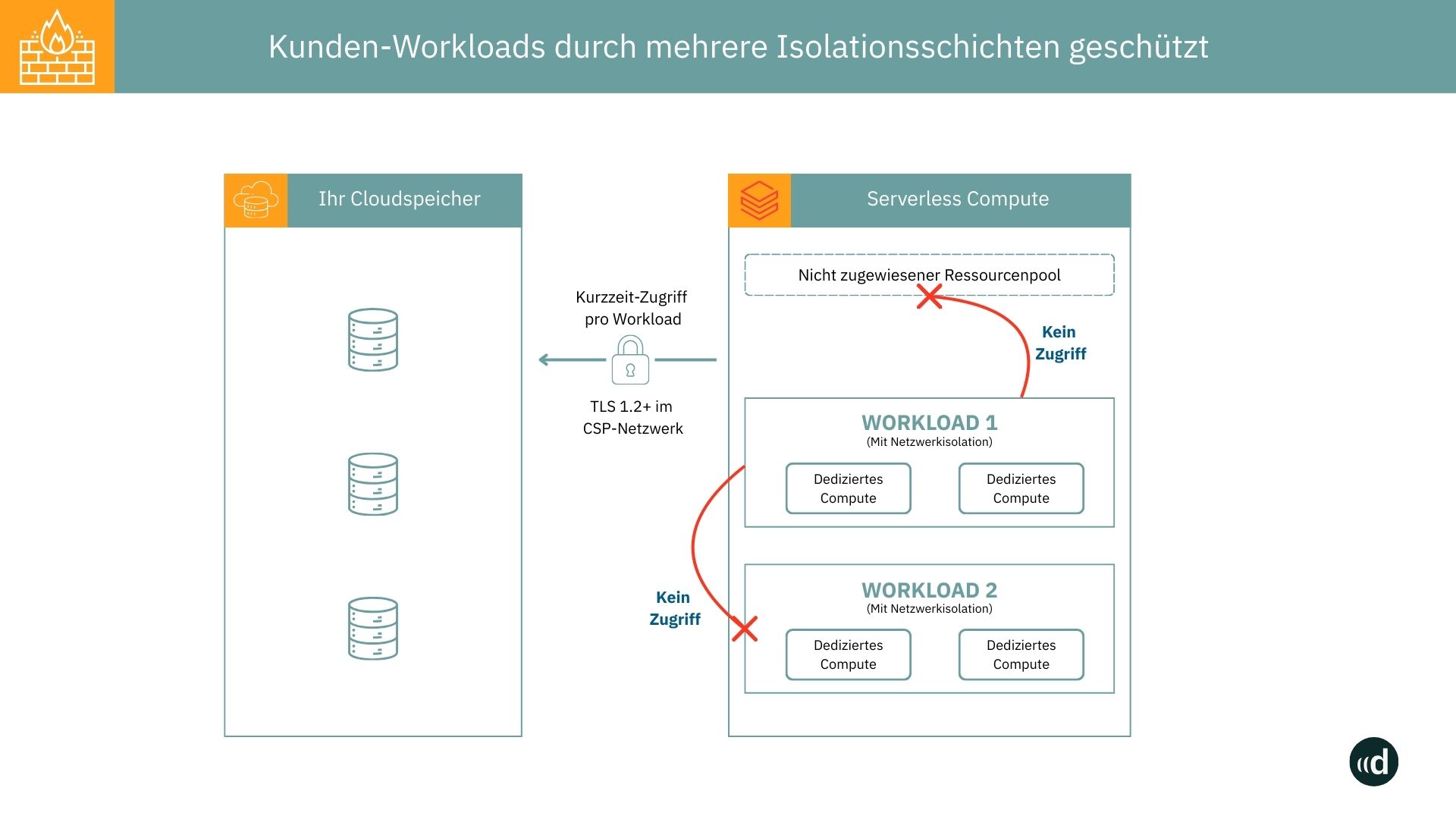
Wie in der Abbildung dargestellt, sorgt Databricks innerhalb dieser Umgebung für verschiedene Sicherheitsmaßnahmen, um Kundendaten abzusichern:
- Isolierte Ausführung jeder einzelnen Anfrage,
- automatische Ressourcentrennung zwischen verschiedenen Kunden,
- Verschlüsselung von Daten bei Übertragung und Speicherung.
Da sich die Serverless-Compute-Plattform innerhalb des Azure-Backbone-Netzwerks befindet, erfolgt die Kommunikation nicht über das öffentliche Internet. Zusätzlich sind alle Datenverbindungen per HTTPS verschlüsselt.
Wie bei All-Purpose- oder Job-Clustern benötigt auch Serverless Compute Zugriff auf Azure-Ressourcen des Kunden – insbesondere auf Storage Accounts. Dazu stehen zwei Varianten zur Verfügung:
- Allowlist über IP-Firewall (NCC):
Über eine sogenannte Network Connectivity Configuration (NCC) stellt Databricks einen Satz fester IP-Adressen bereit. Diese werden auf Kundenseite in die Firewall des Storage Accounts aufgenommen. Serverless Compute nutzt dann ausschließlich diese Adressen zur Verbindung mit den Azure-Ressourcen. - Kommunikation über Azure Private Endpoint:
Alternativ kann ein Azure Private Endpoint eingerichtet werden, über den die Kommunikation direkt innerhalb des Azure-Backbones erfolgt – ohne öffentliche IPs. Diese Methode bietet ein höheres Maß an Isolation und eignet sich für Umgebungen mit strikten Netzwerkrichtlinien.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Für Unternehmen mit regulierten oder besonders geschützten Netzwerkumgebungen ist eine sorgfältige Prüfung dieser Optionen notwendig. In manchen Fällen kann die Nutzung von Serverless Compute aus Governance- oder Datenschutzgründen eingeschränkt oder mit zusätzlichem Aufwand verbunden sein.
Vor- und Nachteile von Serverless Compute Databricks
Bei der Entscheidung, ob der Einsatz von Serverless für Ihr Unternehmen in Frage kommt, sollten wir uns über mögliche Vor- und Nachteile bewusst sein. In diesem Abschnitt fassen wir die für uns wichtigsten Punkte nochmals in Kurzform zusammen:
Vorteile von Databricks Serverless Compute:
- Einfachheit & Geschwindigkeit
- Kein Infrastrukturaufwand: Sofortiger Start ohne komplexe Konfiguration oder tiefes Infrastrukturwissen.
- Automatische Skalierung: Vorkonfigurierte Umgebungen mit intelligenter Ressourcensteuerung, die Wartezeiten minimieren.
- Kosteneffizienz & Governance
- Pay-per-use: Abrechnung nur für tatsächlich genutzte Kapazitäten, keine Kosten für Leerlauf.
- Automatische Ressourcenoptimierung: Kontinuierliche Updates und Optimierungen ohne manuellen Aufwand.
- Integrierte Kostenkontrolle: Budgetüberwachung und zentrale Abrechnung über eine einzige Databricks-Rechnung.
- Zuverlässigkeit & Sicherheit
- Mehrschichtige Sicherheitsstandards: Unity Catalog mit standardmäßiger Datenverschlüsselung und strikten Zugriffsrichtlinien.
- Automatisches Failover: Ausfallsichere Workloads durch intelligente Auswahl der Verfügbarkeitszonen.
Nachteile:
- Eingeschränkte Infrastrukturkontrolle
- Keine Wahl bestimmter Instanztypen oder Betriebssysteme, limitierte Cluster-Einstellungen.
- Eingeschränkter Zugriff auf Systemlogs und Netzwerkdiagnosen.
- Funktions- und Kompatibilitätsgrenzen
- Nicht alle Databricks-Funktionen verfügbar (z. B. bestimmte Runtime-Versionen, benutzerdefinierte Libraries, spezielle Spark-Konfigurationen).
- Libraries aus Unity Catalog noch im Ausbau.
- Kein paralleles Ausführen mehrerer Tasks in einem Notebook.
- Technische Limitierungen
- Vorgaben zu maximaler Arbeitsspeichermenge, Job-Laufzeit und aktiven Sessions sind von Databricks vorgegeben und nicht anpassbar.
- Einschränkungen bei Netzwerksicherheit
- Keine Ausführung im eigenen VNet, daher nicht in allen Szenarien mit strikten Governance- oder Netzwerkrichtlinien einsetzbar.
- VNet- oder Private-Link-basierter Zugriff auf Datenquellen nur eingeschränkt möglich.
Wichtig: Diese Nachteile bedeuten nicht, dass Serverless generell ungeeignet ist – sie unterstreichen lediglich, dass nicht jeder Workload von Serverless profitiert. Für datenintensive, langlaufende oder stark individualisierte Szenarien kann weiterhin ein klassischer Clusterbetrieb sinnvoll sein.
In welchen Szenarien sollte Serverless eingesetzt werden? Wann nicht?
Serverless Compute stellt eine wichtige Weiterentwicklung innerhalb der Databricks-Plattform dar und sollte aus strategischer Sicht generell im Workspace aktiviert werden, um zukünftige Funktionalitäten nicht auszuschließen. Die Plattform entwickelt sich zunehmend in Richtung serverloser Architekturen – insbesondere im Bereich Datenverarbeitung und Ingestion.
Für produktive ETL-Jobs empfehlen wir weiterhin den Einsatz klassischer Compute-Cluster, sofern keine konkreten Argumente für Serverless vorliegen – etwa besondere Anforderungen an Startzeit, Skalierung oder Infrastrukturentkopplung.
Im Bereich Delta Live Tables (DLT) bietet Serverless jedoch klare Vorteile: Die Ingestion-Pipelines, die wir künftig nutzen wollen, profitieren hier von einer deutlich effizienteren Verarbeitung.
Darüber hinaus wird LakeFlow Connect, die angekündigte zentrale Komponente für datengetriebene Ingestionsprozesse in Databricks, ausschließlich mit Serverless DLT kompatibel sein. Eine frühzeitige Aktivierung von Serverless sichert somit die technische Anschlussfähigkeit.
Auch für die interaktive Entwicklung bietet Serverless klare Mehrwerte. Die schnelle Verfügbarkeit von Ressourcen verbessert die Nutzererfahrung in Notebooks und verkürzt Entwicklungszyklen spürbar.
Fazit: Serverless aktivieren
Databricks Serverless Compute bietet Unternehmen die Chance, ihre Daten- und KI-Workloads deutlich effizienter zu betreiben. Die automatische Skalierung, sekundengenaue Abrechnung und der Wegfall komplexer Cluster-Verwaltung sorgen für weniger Administrationsaufwand und niedrigere Betriebskosten.
Gleichzeitig bleiben klassische Compute-Optionen für Szenarien mit speziellen Infrastruktur- oder Governance-Anforderungen weiterhin sinnvoll.
Unsere Empfehlung: Aktivieren Sie Serverless Compute in Ihrem Workspace, um maximale Flexibilität und Zukunftssicherheit zu gewährleisten.
Nutzen Sie die Vorteile insbesondere für schnelle Entwicklungszyklen, Delta Live Tables und moderne KI-Workloads – und setzen Sie klassische Cluster gezielt dort ein, wo volle Kontrolle und Individualisierung gefragt sind.
Für weitere Informationen zu diesem Thema besuchen Sie unsere Databricks Beratungsseite.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte
FAQ: Die wichtigsten Fragen schnell beantwortet
Databricks Serverless Compute ist eine vollständig verwaltete Compute-Option, die automatisch Rechenressourcen bereitstellt und skaliert. Nutzer müssen keine Cluster manuell konfigurieren, sondern profitieren von schnellerem Start, einfacher Skalierung und optimierten Kosten.
Die wichtigsten Vorteile sind automatische Skalierung, kürzere Startzeiten, geringere Administrationsaufwände und optimierte Kostenkontrolle. Zudem unterstützt Serverless Compute moderne Workloads wie Machine Learning, Streaming oder SQL-Abfragen ohne komplexe Infrastrukturverwaltung.
Im Gegensatz zu Classic Compute müssen bei Serverless Compute keine Cluster manuell verwaltet werden. Ressourcen werden automatisch durch Databricks bereitgestellt, skaliert und beendet. Dadurch sinken Verwaltungsaufwand und Kosten, während die Performance oft höher ist.