Ein Data Lakehouse-Ansatz bietet die Flexibilität und Skalierbarkeit eines Data Lakes in Kombination mit hoher Datenqualität, Transaktionssicherheit und vereinfachter und vereinheitlichter Verwaltung bzw. Governance des Data Warehouse.
Der Data Lakehouse Ansatz vereint somit die wichtigsten Funktionalitäten von Data Lakes und Data Warehouses.
Damit können Unternehmen das Datenarchiv des Data Warehouse-Ansatzes für eine einheitliche Speicherung nutzen, ohne auf die analytische Flexibilität und Skalierbarkeit von Data Lakes verzichten zu müssen. Ein Data Lake kann für viele analytische Themen genutzt werden, wie z.B. den Aufbau von themenbezogenen Data Marts, Dashboards oder Machine Learning Anwendungen.
Legen wir los!
Die Anforderungen an moderne Datenarchitekturen in der Cloud werden immer komplexer und viele Teams sind mit der Datenflut überfordert. Datenteams benötigen eine Datenarchitektur, die Daten kosteneffizient speichert, Skalierbarkeit und schnelle Verarbeitung ermöglicht und gleichzeitig eine zuverlässige Quelle für Analysen darstellt.
Genau hier setzt die Lakehouse-Architektur an. Denn sie verbindet die Flexibilität und Kosteneffizienz eines Data Lake mit den kontextbezogenen und schnellen Abfragemöglichkeiten eines Data Warehouse.
Schauen wir uns zunächst an, wie der Lakehouse-Ansatz definiert ist.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Was ist ein Data Lakehouse?
Ein Data Lakehouse besteht aus einem Data Lake, der durch eine Reihe von Komponenten die Vorteile eines DWH übernimmt und die Nachteile eines reinen Data Lakes behebt. Es versucht, den einfachen Zugriff und die Unterstützung für Geschäftsanalysen, die in Data Warehouses zu finden sind, mit der Flexibilität und den relativ niedrigen Kosten eines Data Lake zu kombinieren.
Herkömmliche Data Lakes haben zwei Herausforderungen:
- Eine sichere, flexible Datentransformation
- Data Governance
Zur Lösung der zwei Herausforderungen gibt es verschiedene Tools. Anbieter von Tools im Bereich Transformation sind Hudi, Iceberg und Delta mit Open-Source-Lösungen.
Eine Lösung für den Punkt Data Governance stellt der Unity Catalog dar. Die Data Lakehouse Architektur stellt eine übergreifende Lösung dar, welche die Tools (Delta Tables und Unity Catalog) für beide Herausforderungen bereitstellt.
Sehen wir uns an, wie das Data Lakehouse aufgebaut ist.
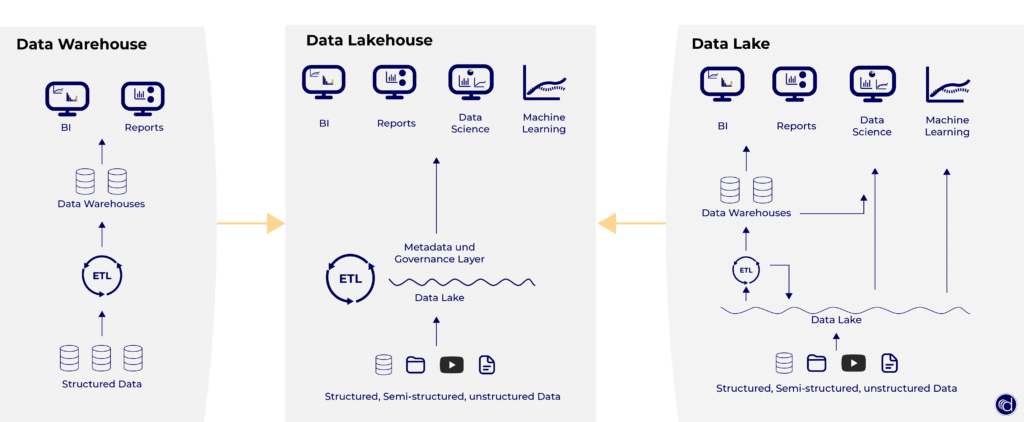
Der Aufbau des Data Lakehouse
In der folgenden Abbildung sehen Sie den Aufbau des Lakehouse: Jede Datenform kann in den Data Lake geladen werden. Im nächsten Schritt durchlaufen die Daten den ETL-Prozess und landen mit ACID-Compliance in der Governance Layer.
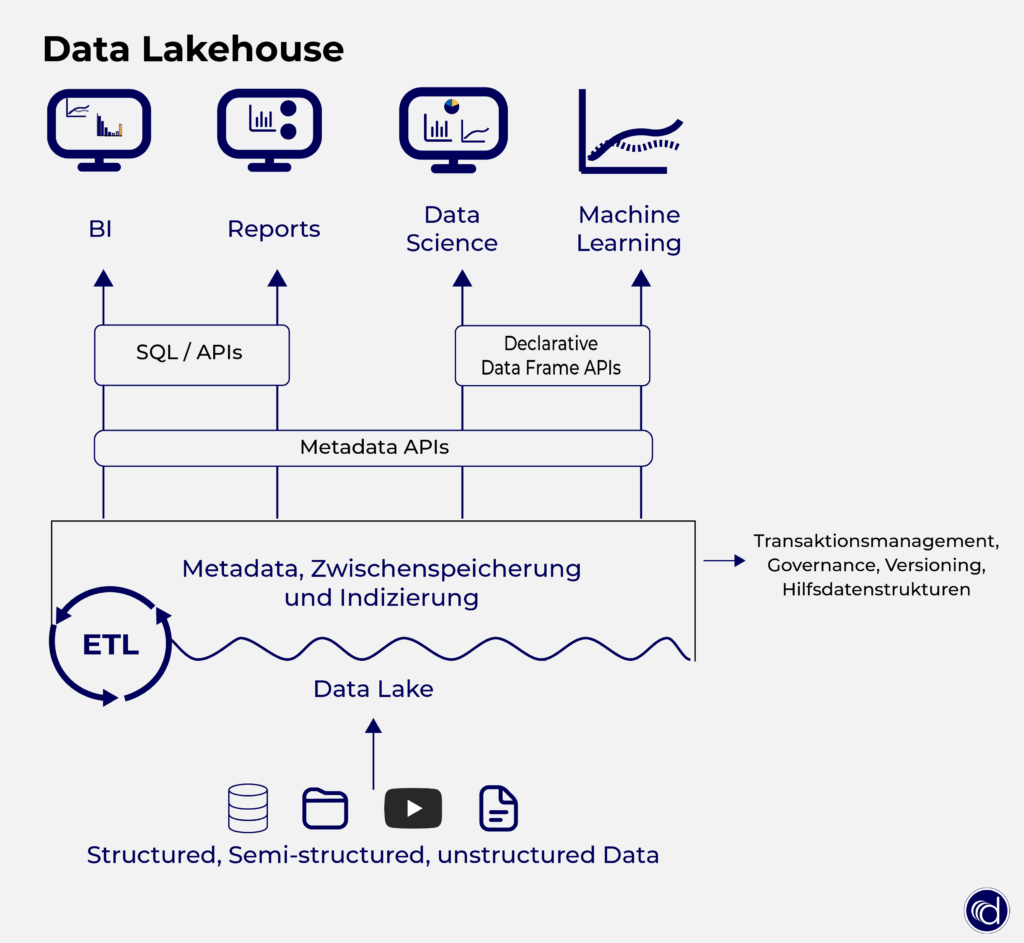
Der klassische Data Lake ist für Machine Learning und Data Science Anwendungen geeignet. Sie haben die Möglichkeit, direkt auf Parquet zuzugreifen und Sie haben einfachen Zugriff auf Daten aus vielen unterschiedlichen Quellen.
Für Reportings und BI (die mit SQL arbeiten) ist Data Lake weniger geeignet. Hier stellen die Tabellen-Metadaten-Formate (Delta o.a.) eine bessere Möglichkeit dar, um die Daten erfolgreich zu nutzen.
Diese Tabellen-Metadaten-Formate sind für den gesamten ETL-Prozess hilfreich für eine sichere, flexible Transformation. So wird beispielsweise verhindert, dass Dateien korrumpieren, wenn zwei Nutzer gleichzeitig auf dieselben Daten zugreifen. Außerdem sind komplexere Logiken wie UPSERTS oder Rollbacks möglich.
Die folgenden 5 Merkmale zeichnen den Lakehouse Ansatz aus und sollen Ihnen eine schnelle Übersicht gewähren:
| Merkmal | Eigenschaft |
|---|---|
| Dateneingabe | – Große strukturierte und unstrukturierte Datenmengen – ELT fähig |
| Datenverwaltung | – Kostengünstige skalierbare Objektspeicher wie AWS S3, Azure Blob Storage oder Google Cloud Storage |
| Abfrageart | – Abfrage muss Ad-Hoc-Analysen unterstützen |
| Massive parallele Verarbeitung | – Ermöglicht verteilte Ausführung von Abfragen durch mehrere Prozessoren, um Antwort zu beschleunigen |
| Indizierung | – Architektur umfasst verschiedene statistische Techniken (z.B. Bloom-Filter) – Techniken bewirken, dass nicht alle Daten auf einmal gelesen werden, somit werden massive Geschwindigkeitssteigerungen erzielt |
Wie genau das Data Lakehouse arbeitet, sehen wir uns im folgenden Abschnitt an.
Wie sieht eine Lakehouse Architektur aus?
Es gibt verschiedene Umsetzungsmöglichkeiten für eine Data Lakehouse Architektur. Wir sehen uns die Architektur an dem konkreten Beispiel der Data Lakehouse Architektur von Databricks an.
Die Lakehouse-Architektur besteht aus der so genannten Medaillon-Architektur. Diese beschreibt eine Reihe von Datenschichten (Bronze, Silber und Gold), welche die Qualität der im Lakehouse gespeicherten Daten kennzeichnet. Durch die Architektur soll eine Single Source of Truth aufgebaut werden, um die Daten von Unternehmen sicher zu verarbeiten.
Da die Daten mehrere Ebenen durchlaufen, bevor sie in einem für Analysen optimierten Layout gespeichert werden, garantiert die Architektur-Atomarität, Konsistenz, Isolierung und Dauerhaftigkeit.
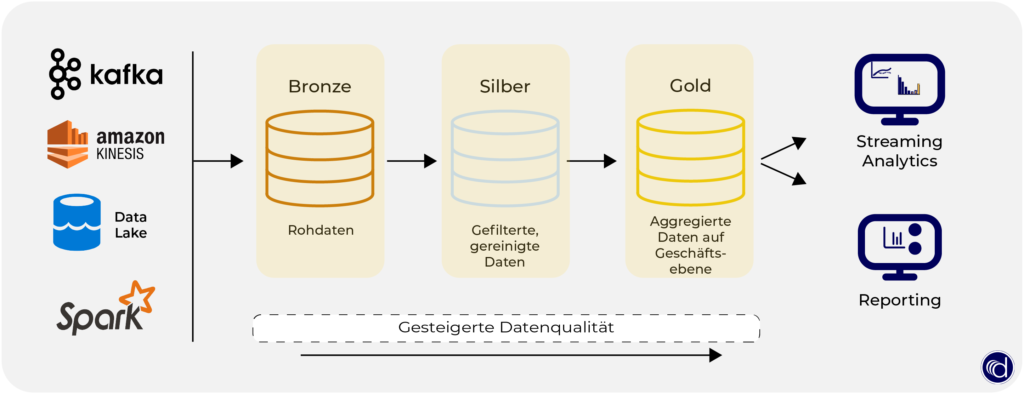
Sehen wir uns die einzelnen Schichten genauer an.
Bronzeschicht:
Daten, die in der Bronzeschicht aufgenommen werden, sind typischerweise unvalidiert und behalten den Rohzustand der Datenquelle bei. Sie werden inkrementell hinzugefügt und wachsen mit der Zeit an. Dabei handelt es sich um eine beliebige Kombination aus Streaming– und Batch-Transaktionen.
Die Aufbewahrung des vollständigen, unverarbeiteten Verlaufs jedes Datensatzes in einem effizienten Speicherformat ermöglicht es, jeden Zustand eines bestimmten Datensystems wiederherzustellen.
Zusätzliche Metadaten (z. B. Quelldateinamen oder Aufzeichnung des Zeitpunkts der Datenverarbeitung) können den Daten beim Einlesen hinzugefügt werden, um die Auffindbarkeit zu verbessern, den Zustand des Quelldatensatzes zu beschreiben und die Leistung in nachgelagerten Anwendungen zu optimieren.
Silberschicht:
Während die Bronzeschicht die gesamte Datenhistorie in einem nahezu rohen Zustand enthält, stellt die Silberschicht eine validierte, angereicherte Version unserer Daten dar. Diese können wir dann für nachgelagerte Analysen verwenden. Für jede Datenpipeline kann die Silberschicht mehr als eine Tabelle enthalten.
Goldschicht:
In der Goldschicht sind die „goldenen“ Daten stark verfeinert und aggregiert. Diese Daten unterstützen Analysen, maschinelles Lernen und Produktanwendungen. Während alle Tabellen im Lakehouse einem wichtigen Zweck dienen sollen, stellen die Gold-Tabellen Daten dar, die in Wissen umgewandelt wurden.
Aktualisierungen dieser Tabellen werden im Rahmen regelmäßig geplanter Produktionsworkloads durchgeführt, was zur Kostenkontrolle beiträgt und die Festlegung von Service Level Agreements (SLAs) für die Datenaktualität ermöglicht.
In dem Video erklären wir Ihnen alles, was Sie über die Medallion-Architektur wissen müssen:
Obwohl im Lakehouse nicht die gleichen Deadlock-Probleme auftreten wie in einem Enterprise Data Warehouse, werden Goldtabellen oft in einem separaten Speichercontainer gespeichert, um Cloud-Limits für Datenanfragen zu vermeiden.
Da Aggregationen, Joins und Filterungen verarbeitet werden, bevor wir die Daten in die Goldschicht schreiben, sollten die Benutzer im Allgemeinen eine geringe Latenz bei Abfragen auf Daten in Goldtabellen feststellen.
Databricks Lakehouse Plattform besteht zudem aus Delta Tables und dem Unity Catalog, die die Daten Governance und Transformation sichern.
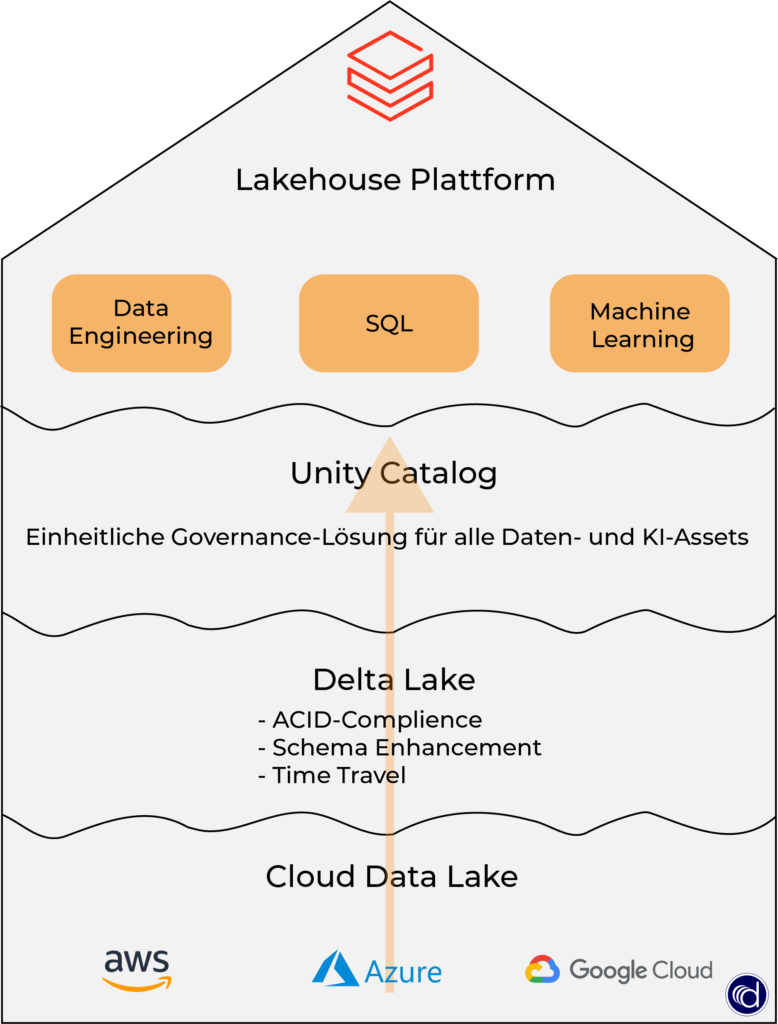
Delta Tables
Deltatabellen sind das Standard-Datentabellenformat in Databricks und eine Funktion des Delta Open-Source-Data-Frameworks. Wir verwenden die Tabellen in der Regel für Data Lakes, bei denen Daten per Streaming oder in großen Stapeln eingespeist werden. Delta Tables garantieren:
- ACID-Transaktion: Eine Deltatabelle ist eine verwaltete Tabelle, die die Databricks Delta Optimistic Concurrency Control-Funktion verwendet, um vollständige ACID-Transaktionen (Atomarität, Konsistenz, Isolation und Haltbarkeit) zu ermöglichen. Jeder Benutzer kann eine Delta-Tabelle mit Lesezugriff auf den zugrunde liegenden Speicher lesen.
- Data Versioning: Deltatabellen geben eine separate Protokollversion für das Lese- und das Schreibprotokoll an. Das Transaktionsprotokoll für eine Deltatabelle enthält Informationen über die Protokollversionierung, die die Entwicklung von Delta unterstützt. Die Protokollversionen bündeln alle Funktionen aus früheren Protokollen.
- ETL: Deltatabellen sind das Standard-Datentabellenformat in Databricks und eine Funktion der Delta Tables Open Source Data Frameworks. Deltatabellen werden in der Regel für Data Lakes verwendet, bei denen Daten per Streaming oder in großen Stapeln eingespeist werden
- Indexierung: Eine Databricks-Deltatabelle zeichnet Versionsänderungen oder Modifikationen in einer Featureklasse einer Tabelle in Delta auf. Im Gegensatz zu herkömmlichen Tabellen, die Daten in einem Zeilen- und Spaltenformat speichern, erleichtert die Databricks Delta Table ACID-Transaktionen und Zeitreisefunktionen zur Speicherung von Metadateninformationen für eine schnellere Datenaufnahme.
Unity Catalog
Unity Catalog bietet zentralisierte Zugriffskontrolle, Auditing, Lineage und Datenermittlungsfunktionen für alle Databricks-Arbeitsbereiche und somit einen zentralen Ort zur Verwaltung von Datenzugriffsrichtlinien, die für alle Arbeitsbereiche und Personas gelten.
- Data Governance: Die Data-Governance- und Data-Lineage-Tools von Unity Catalog stellen sicher, dass der Datenzugriff für alle föderierten Abfragen der Benutzer in Ihren Databricks-Arbeitsbereichen verwaltet und geprüft wird.
- Data Sharing: Mit der Databricks-to-Databricks-Freigabe können Sie Daten mit Databricks-Benutzern austauschen, die Zugriff auf einen anderen Unity Catalog-Metaspeicher haben als Sie. Databricks-to-Databricks unterstützt auch die gemeinsame Nutzung von Notebooks, was bei der offenen Freigabe nicht möglich ist.
- Data Auditing: Unity Catalog erfasst ein Audit-Protokoll der Aktionen, die mit dem Metastore durchgeführt wurden. Dies ermöglicht Administratoren den Zugriff auf detaillierte Details darüber, wer auf einen bestimmten Datensatz zugegriffen hat und welche Aktionen durchgeführt wurden.
Durch die Speicherung von Daten in Delta können wir von überall aus auf die Daten zugreifen und gleichzeitig mit ihnen arbeiten.
Unity Catalog stellt sicher, dass wir die vollständige Kontrolle darüber haben, wer auf welche Daten zugreifen darf, und bietet einen zentralen Mechanismus für die Verwaltung aller Data Governance- und Zugriffskontrollen, ohne Replizierung von Daten.
Die im Lakehouse gespeicherten Daten legen für die Unternehmen die erforderlichen Governance-, Nutzungs- und Zugriffsregeln fest. Das Ergebnis ist ein Rahmenwerk, das eine einzige Quelle der Wahrheit bietet und Unternehmen in die Lage versetzt, fortschrittliche Analysemöglichkeiten gleichzeitig zu nutzen. Werfen wir einen Blick auf die Vorteile des Lakehouse im Detail.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Was sind die Vorteile eines Lakehouse?
Ein speziell entwickeltes Data Lakehouse kann eine Vielzahl von Datenquellen aufnehmen, ohne dass Kompromisse zwischen kostspieliger Datenspeicherung, Geschwindigkeit und Skalierung eingegangen werden müssen. Wir haben euch die Key Features und Vorteile zusammengetragen.
- Transaktionsunterstützung: Das Lakehouse gewährleistet durch ACID-Transaktion die Konsistenz der Daten, wenn mehrere Personen auf diese gleichzeitig zugreifen.
- Schemadurchsetzung und Governance: Das Lakehouse unterstützt die Durchsetzung und Weiterentwicklung von Schemata. Gleichzeitig ist es in der Lage, Rückschlüsse auf die Datenintegrität zu ziehen, und bietet eine robuste Governance- und Prüfmechanismen.
- BI-Support: Lakehouses ermöglichen die Verwendung von BI-Tools direkt auf den Quelldaten. Dies reduziert die Veralterung, Latenzzeit und Kosten und verbessert die Aktualität der Operationalisierung.
- Die Speicherung ist von der Datenverarbeitung entkoppelt: Speicherung und Berechnung folgen in getrennten Clustern, so dass die Systeme für mehr Benutzer und größere Datenmengen skaliert werden können.
- Offenheit: Die Speicherformate sind offen und standardisiert, wie z. B. Parquet, und bieten eine API, so dass eine Vielzahl von Tools und Engines, einschließlich maschinellem Lernen und Python/R-Bibliotheken, effizient direkt auf die Daten zugreifen können.
- Unterstützung für verschiedene Datentypen, von unstrukturierten bis zu strukturierten Daten: Das Lakehouse kann zum Speichern, Verfeinern, Analysieren und Zugreifen auf Datentypen verwendet werden, die für viele neue Datenanwendungen benötigt werden (z.B. Bilder, Video, Audio, halbstrukturierte Daten und Text).
- Unterstützung für verschiedene Workloads: einschließlich Data Science, maschinelles Lernen, SQL und Analysen. Zur Unterstützung all dieser Arbeitslasten sind möglicherweise mehrere Tools erforderlich, die jedoch alle auf demselben Datenspeicher basieren.
Wie Sie das Lakehouse für Ihr Unternehmen implementieren, zeigen wir Ihnen hier: Lakehouse Architektur: 6 Best Practices
End-to-End-Streaming: Berichte in Echtzeit sind in vielen Unternehmen die Norm. Durch die Unterstützung von Streaming wird der Bedarf an separaten Systemen für die Bereitstellung von Echtzeitdatenanwendungen überflüssig.
Wir beantworten noch weitere Fragen, die vielleicht im Kontext mit dem Lakehouse entstehen könnten.
Welche Arten von Daten kann ein Lakehouse speichern und verarbeiten?
Das Data Lakehouse bietet durch den flexiblen Aufbau des Data Lakes die Möglichkeit alle Daten in Ihrer Rohform aufzunehmen, also strukturiert, semi-strukturiert und unstrukturiert. Dadurch bietet das Lakehouse die Möglichkeit mit großen Metadaten zu arbeiten.
Wie unterscheidet sich das Data Lakehouse hinsichtlich Kosten und Performance vom Data Warehouse?
Data Lakehouse-Systeme basieren auf separaten, elastisch skalierbaren Rechen- und Speichersystemen, um ihre Betriebskosten zu minimieren und die Leistung zu maximieren. Neuere Systeme bieten eine vergleichbare oder sogar bessere Leistung pro Dollar als herkömmliche Data Warehouses für SQL-Workloads, da sie dieselben Optimierungstechniken innerhalb ihrer Engines verwenden (z. B. Abfragekompilierung und Speicherlayout-Optimierung).
Darüber hinaus nutzen Lakehouse-Systeme häufig kostensparende Funktionen von Cloud-Anbietern, wie z. B. Spot-Instance-Preise (bei denen das System den Verlust von Worker-Knoten während einer Abfrage tolerieren muss) und ermäßigte Preise für Speicher, auf den nur selten zugegriffen wird, wofür herkömmliche Data-Warehouse-Engines in der Regel nicht ausgelegt sind.
Die Betriebskosten des Lakehouse sind wie die des Data Lakes gering. Durch die offene Struktur wird kein weiterer Anbieter benötigt, um die Daten zu verwalten.
Welche Weiterverarbeitungsoptionen unterstützt das Lakehouse?
Durch die offene Architektur, die Lokalität und die hohe Skalierbarkeit bietet das Data Lakehouse die ideale Grundlage für Analysen. So unterstützt das Lakehouse sowohl ACID-Transaktionen, Indizierung und Schema-Validierung als auch alle Arten von Analysen und Machine Learning. Außerdem hält das Data Lakehouse die Daten durch permanentes Streaming oder regelmäßiges Batch-Processing aktuell.
Welcher Vorteil ergibt sich für das Data-Team?
Es handelt sich bei dem Data Lakehouse um die Kombination der Vorteile eines Data Lake und eines Data Warehouse und das an einem Ort. Dadurch können sowohl Data Engineers als auch Data Scientists und Analysten an einem zentralen Ort zusammenarbeiten.
Neben der Vereinheitlichung der Datenteams hat jeder verantwortliche Mitarbeiter die Möglichkeit, auf die Daten in jeglicher Form zuzugreifen. Somit hat auch der Fachbereich einen einfachen Zugriff auf benötigte Informationen. Dies wird durch das vereinfachte Aufbrechen von Datensilos ermöglicht: Eine vollständige und feste Kopie der Daten in den Silos wird an einem zentralen Ort (dem Data Lakehouse) gespeichert.
Wir bei Datasolut sind Full-Stack-Anbieter und beraten Sie gerne hinsichtlich Data Engineering oder Data Science!
Data Warehouse vs. Data Lake vs. Data Lakehouse: Was ist der Unterschied?
Während Data Lakehouses die Flexibilität und Kosteneffizienz von Data Lakes mit den Abfragefunktionen von Data Warehouses kombinieren, ist es wichtig zu verstehen, wie sich diese Speicherumgebungen unterscheiden. Die folgende Tabelle gewährt einen Überblick:
| Eigenschaft | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Datenstruktur | Strukturiert (verarbeitet) | Strukturiert, semi-strukturiert, unstrukturiert (Roh) | Strukturiert, semi-strukturiert, unstrukturiert (Roh) |
| Verwendungszweck der Daten | Bereits festgelegt | Noch unbekannt | Noch unbekannt |
| Benutzer (Data Governance) | Business-Anwender, KPI-Reporting | Data Scientist | Business-Anwender, KPI-Reporting Data Scientist (alle relevanten Mitarbeiter) |
| Pflege | Einfach | Hoch | Einfach |
| Flexibilität | Gering | Hoch | Hoch |
| Skalierbarkeit | Gering | Hoch | Hoch |
| ACID-Compliance | Hoch | Gering | Hoch |
| Kosten | Hoch | Gering | Gering |
Die genaue Abgrenzung zwischen einem Data Lake und einem Data Lakehouse haben wir Ihnen in dem folgenden Video in 6 Minuten erklärt:
Sie möchten noch mehr über das Thema Data Lakehouse erfahren oder sind an der Implementierung eines Lakehouses in Ihrem Unternehmen interessiert? Dann kontaktieren Sie uns gerne! Wir helfen Ihnen bei der Planung und dem Aufbau ihres Lakehouses.
FAQ – Die wichtigsten Fragen rund ums Data Lakehouse
Ein Data Lake ist eine Datenverwaltungsarchitektur, die die Vorteile eines herkömmlichen Data Warehouse und eines Data Lake kombiniert. Es versucht, den einfachen Zugriff und die Unterstützung für Geschäftsanalysen, die in Data Warehouses zu finden sind, mit der Flexibilität und den relativ niedrigen Kosten eines Data Lake zu kombinieren.
Ein speziell entwickeltes Lakehouse kann eine Vielzahl von Datenquellen aufnehmen, ohne dass Kompromisse zwischen kostspieliger Datenspeicherung, Geschwindigkeit und Skalierung eingegangen werden müssen. Es bietet die Flexibilität und Kosteneffizienz eines
eines Data Lake mit den kontextbezogenen und schnellen Abfragefunktionen eines Data Warehouse.
Das Lakehouse verbindet die Vorteile des Data Lake mit denen des Data Warehouse. Somit ergänzt das Data Lakehouse den Data Lake um die Fähigkeit, kontextbezogen schnelle Abfragen von Daten zu ermöglichen.
Eine moderne Lakehouse-Architektur kann eine klassische Data Warehouse Architektur ablösen. Diese ermöglicht die skalierbare Speicherung und Verarbeitung von Daten, dabei bietet sie gleichzeigt die Möglichkeiten von relationalen Datenbanken Transaktionssicherheit, schnelle Abfragegeschwindigkeit und die Nutzung von SQL.
Das Lakehouse baut auf dem bestehenden Data Lake auf und ergänzt dieses um klassische Data Warehouse Eigenschaften wie ACID-Transaktionen, Datensicherheit und SQL-Unterstützung. Data Warehouses weisen Funktions- und Leistungseinschränkungen auf und bietet keine Unterstützung für Machine Learning oder Data Science-Anwendungsfälle.
Unternehmen müssen nicht alle ihre Daten in einem Lakehouse zentralisieren. Viele Unternehmen verwenden einen dezentralen Ansatz zur Speicherung und Verarbeitung von Daten, dafür aber einen zentralen Ansatz für Sicherheit, Governance und Discovery.
1. Jede Geschäftseinheit baut ihr eigenes Lakehouse auf, um die komplette Sicht auf ihr Geschäft zu erfassen
2. Jeder Funktionsbereich, z. B. Produktherstellung, Vertrieb und Marketing, könnte sein eigenes Lakehouse aufbauen, um die Abläufe innerhalb seines Geschäftsbereichs zu optimieren.
3. Einige Unternehmen gründen auch ein neues Lakehouse, um neue funktionsübergreifende strategische Initiativen wie z. B. Customer 360 abzubilden.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte