


Der ETL-Prozess setzt sich aus drei wesentlichen Einzelschritten zusammen und dient dazu, Daten aus verschiedenen Datenquellen nutzbar zu machen. Häufig kommt dieser Prozess zur Verarbeitung großer Datenmengen in Bereichen wie Big Data oder Business Intelligence zum Einsatz.
Lesen Sie auch:
Wir zeigen Ihnen was ein ETL-Prozess ist, was in den einzelnen Schritten passiert, auf was Sie beim Prozess achten müssen und welche Vorteile er bringt.
Lassen Sie uns starten!
Was ist ein ETL-Prozess?
Ein ETL-Prozess setzt sich aus den Einzelschritten Extract, Transform und Load zusammen und ermöglicht es, Daten aus unterschiedlichen Quellen zu verwenden.
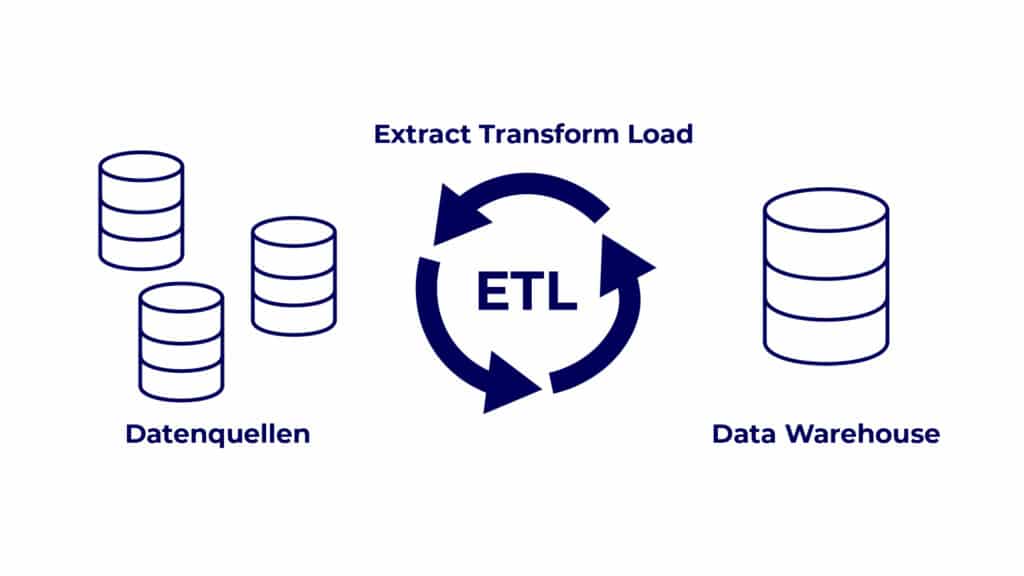
- Extraktion: Daten werden aus verschiedenen Quellen wie Datenbanken, APIs oder Dateien abgerufen.
- Transformation: Die Rohdaten werden bereinigt, vereinheitlicht und gegebenenfalls aggregiert oder umformatiert.
- Laden: Die transformierten Daten werden in ein Data Warehouse oder eine andere Zielumgebung überführt.
Die Nutzung eines ETL-Prozesses hängt primär damit zusammen, dass unternehmensrelevante Daten aus unterschiedlichen internen sowie externen Quellen stammen. Da diese Informationen unterschiedlichen Ursprung haben, müssen wir diese zunächst gebündelt erfassen. Aufgrund der Verschiedenheit dieser Daten, werden sie im nächsten Schritt bereinigt und es erfolgt eine Aufbereitung dieser Rohdaten.
Anschließend werden die bereinigten Daten innerhalb einer zentralisierten Datenbank wie dem Data Warehouse gespeichert, wodurch diese für eine Vielzahl an Anwendern zur Verfügung stehen.
Dieser Prozess dient dem Zweck vorhandene Daten zur Entscheidungsfindung innerhalb eines Unternehmens hinzuzuziehen und Prozesse zu optimieren. Mit der passenden Datenarchitektur wie dem Data Lakehouse ist das ganz einfach.
Data Warehouse vs. Lakehouse: Warum das Warehouse ausgedient hat.
Schauen wir uns die 3 Schritte im Detail an:
Extract = Herausfiltern
Nur wenige Unternehmen verlassen sich auf einen einzigen Datentyp. Die Vielzahl an Unternehmen setzt bei der Verwaltung ihres Datenbestands auf mehrere Datenquellen. Damit dies möglich ist, müssen zunächst einmal unterschiedliche Daten erfasst werden.
Extract beschreibt den ersten wichtigen Schritt eines ETL-Prozesses. Dabei geht es vorwiegend um die Auswahl der Daten für den nachfolgenden Transformationsprozess. Häufig werden hinsichtlich der Extraktion nur Teilbereiche einzelner Quelldatenbanken bezogen.
Damit die Daten stetig aktuell bleiben und das Data Warehouse mit aktuellen Daten versorgt wird, findet der Prozess der Extraktion regelmäßig statt.
Die Rohdaten im Rahmen des Extraktionsprozesses setzen sich größtenteils aus den folgenden Daten zusammen:
- Daten bestehender Datenbanken
- Vertriebs- und Marketingaktivitäten
- Daten von mobilen Geräten und Apps
- Daten aus CRM-Systeme
- Aktivitätsprotokolle
- Anwendungsbezogene Performance-Daten
- Transaktionsaktivitäten
Transform = Umwandlung
Grundlegend geht es innerhalb der Transformationsphase darum, dass extrahierte Daten mit dem Format der Zieldatenbank übereinstimmen. Dementsprechend unterteilt sich der Transformationsprozess in mehrere Einzelschritte. Diese sehen wie folgt aus:
- Bestimmung von Richtlinien bei der Formatierung
- Bereinigung von falschen Daten
- Entfernung doppelter Daten
- Sortierung und Zusammenfassung passender Daten
- Feinabstimmung von Datenbestand und Zielschemata
Der Transformationsprozess wird im Allgemeinen als wichtigster Schritt des ETL-Prozesses angesehen. Dies liegt vor allem daran, dass die Transformation der Daten die Datenintegrität erheblich verbessert und dazu beiträgt, dass bestehende Daten am Zielort einerseits vollständig kompatibel und andererseits einsatzbereit ankommen.
Load = Bereitstellen
Im letzten Schritt eines ETL-Prozesses werden die im vorigen Prozess umgewandelten und aufbereiteten Daten geladen. Dies bedeutet, dass das eigentliche Integrieren des bereinigten Datenbestands in ein Data Warehouse oder eine generelle Zieldatenbank erfolgt.
Während dieser Integration ist die Zieldatenbank oder das Data Warehouse häufig gesperrt, um fehlerhafte Auswertungen zu vermeiden. Zudem lassen sich nicht nur neue Daten in ein Data Warehouse integrieren. Auch bestehende Datenbestände innerhalb einer Zieldatenbank lassen sich stetig aktualisieren.
Zudem lassen sich Veränderungen des Data Warehouse protokollieren, sodass diese jederzeit wahrnehmbar sind.
Welche Vorteile bietet ein ETL-Prozess?
Ein gut strukturierter ETL-Prozess bietet zahlreiche Vorteile:
- Leistungsoptimierung: Effiziente Verarbeitung großer Datenmengen für Analyse- und Reportingzwecke.
- Datenintegration: Zusammenführen von Daten aus verschiedenen Quellen zu einer einheitlichen Sicht.
- Datenqualität: Bereinigung und Standardisierung der Daten zur Verbesserung der Konsistenz.
- Automatisierung: Wiederholbare und skalierbare Prozesse zur Reduzierung manueller Eingriffe.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Sehen wir uns weitere Vorteile im Detail an:
Verbesserung des ROI
Aufgrund der Digitalisierung und der damit verbundenen Ansammlung riesiger Datenmengen ist es für viele Unternehmen keine Leichtigkeit, Daten sinnvoll zu organisieren und verständlich bereitzustellen. Demnach bleiben oftmals einige Potentiale unausgeschöpft und wir verschwenden Ressourcen.
Zudem lassen sich mithilfe eines ETL-Prozesses Daten aus sämtlichen Quellen zusammenführen, sodass wir diese sinnvoll zur weiteren Verwendung nutzen können. Dieser verbesserte Überblick von unternehmensrelevanten Daten steht meist in einem festen Zusammenhang mit der Erhöhung des Umsatzes sowie der Verbesserung des ROI.
Skalierbarkeit der Leistung
Mit zunehmendem Wachstum und sich verändernden Marktdynamiken, sind Unternehmen gezwungen, ihre Ressourcen und angewandten Technologien zu optimieren und verändern. Dazu gehört vorwiegend, dass durch die Integration eines ETL-Systems, die Nutzung weiterer Technologien möglich ist.
Dahingehend lassen sich einige Tools im Sinne eines Add-Ons für den ETL-Prozess im Data Warehouse bereitstellen. Zu diesen Tools gehören beispielswiese Tools zur Extraktion großer Datenmengen oder Tools zur Datenvisualisierung. Die Integration solcher sinnvollen Anwendungen trägt zunehmend zur Verbesserung und Skalierbarkeit der Leistung eines Unternehmens bei.
Effiziente Business Intelligence
Technologien auf Basis eines ETL-Prozesses verbessern im Wesentlichen den Datenzugriff. Dadurch ist es beispielsweise jederzeit möglich, dass ein Unternehmen auf diejenigen Datensätze zurückgreifen kann, die für den jeweiligen Zeitpunkt relevant sind.
Diese Hilfestellung wirkt sich zunehmend auf das operative sowie strategische Geschäft aus, indem das Unternehmen auf Basis fundierter Daten seine Entscheidungen datengestützt ableiten kann. Schlussendlich erhalten Unternehmen die Möglichkeit, sich von der Konkurrenz durch verbesserte Entscheidungen langfristig abzusetzen.
Wir von Datasolut haben über 10 Jahre Erfahrung mit der Entwicklung von Datenplattformen zur idealen Datenspeicherung: Die Grundlage aller erfolgreichen Data-Projekte. Kontaktieren Sie uns jetzt.
Besonders in Zusammenhang mit einem Feature Store lassen sich für Unternehmen Vorteile generieren.
Herausforderungen beim ETL-Prozess
Trotz seiner Vorteile kann die Implementierung eines ETL-Prozesses einige Herausforderungen mit sich bringen:
- Komplexität: Die Verarbeitung und Transformation großer Datenmengen kann anspruchsvoll sein.
- Datenqualität: Inkonsistente oder unvollständige Daten erfordern eine aufwendige Bereinigung.
- Laufzeitoptimierung: Besonders bei großen Datenmengen kann der ETL-Prozess ressourcenintensiv sein.
ETL vs. ELT
Eine moderne Variante des ETL-Prozesses ist ELT (Extract, Load, Transform). Während beim klassischen ETL die Transformation vor dem Laden erfolgt, werden beim ELT-Prozess die Daten erst in ein Zielsystem geladen und anschließend dort transformiert. Dies ist insbesondere bei Cloud-basierten Architekturen von Vorteil, da moderne Data Warehouses über leistungsfähige Verarbeitungskapazitäten verfügen.
Wann ist ein ETL-Prozess sinnvoll?
Ein ETL-Prozess ist aufgrund der vielen Vorteile grundsätzlich sinnvoll. Entsprechend sollten Unternehmen Kosten und Zeitaufwand ins Verhältnis zum resultierenden Nutzen eines ETL-Prozesses stellen. Als Hilfestellung folgen 5 Anhaltspunkte, die Sie bei der Entscheidung berücksichtigen sollten.
- Kein einheitliches System: Ihr Unternehmen hat Probleme auf Daten unterschiedlicher Quellen zurückzugreifen, wodurch keine datengestützten Management-Entscheidungen getroffen werden können.
- Schwierigkeiten bei der Datenabfrage: Die Datenabfrage im Unternehmen gestaltet sich zunehmend kompliziert und ist mit Fehlern versehen. Teilweise ist eine Datenabfrage nicht möglich.
- Keine primäre Datenbank: Ihr Unternehmen wünscht den Zugriff auf eine einzige Datenbank? Ein ETL-Prozess hilft Ihnen, diesen Wunsch umzusetzen.
- Verarbeitung großer Datenmengen: Im Rahmen von Business Intelligence und Big Data Analytics müssen oftmals riesige Datenmengen verarbeitet werden. Darüber hinaus kann an dieser Stelle ein ETL-Prozess als Hilfestellung dienen.
- Informationsbedarf: Benötigt das Unternehmen verlässliche Informationsquellen, so lassen sich qualitative Informationen durch einen ETL-Prozess gebündelt in einer zentralen Datenbank zur Verfügung stellen.
Welche Eigenschaften sollte ein ETL-Tool besitzen?
Bei der Wahl des passenden Tools, sollte auf entsprechende Eigenschaften und Funktionen geachtet werden. Derzeit bietet der Markt eine Vielzahl an möglichen Anwendungen und Tools, wodurch der Überblick schnell verloren gehen kann.
Beispiele für verschiedene ETL-Tools sind:
- Kommerzielle Lösungen: Informatica PowerCenter, Microsoft SQL Server Integration Services (SSIS), Talend.
- Open-Source-Tools: Apache NiFi, Airflow, Pentaho Data Integration (PDI).
- Cloud-native Lösungen: AWS Glue, Google Dataflow, Azure Data Factory.
In diesem Video zeigen wir, wir Sie mit Apache Spark und Delta Tables in Databricks einen einfachen ETL-Prozess erstellen und Schritt für Schritt nachmachen können.
Im Folgenden werden Ihnen relevante Funktionen und Eigenschaften erläutert, welche ein entsprechendes Tool erbringen sollte.
- Schnittstelle: Ein gutes ETL-Tool zeichnet sich vorwiegend dadurch aus, dass eine Integration über viele Schnittstellen zu unterschiedlichen Datenbanksystemen möglich ist.
- Kompatibilität: Zusätzlich ist es hilfreich, dass das vorliegende Tool mit unterschiedlichen Cloudmodellen kompatibel ist.
- Bedienung: Eine einfache Bedienung und benutzerfreundliche Oberfläche ist wichtig, damit sämtliche Mitarbeiter eines Unternehmens zügig mit relevanten Funktionen vertraut sind und sich im Umgang mit dem Tool keine Probleme ergeben
- Visualisierung: Die Möglichkeit der Visualisierung ist ebenfalls immens wichtig, um verschiedenen Prozesse und ETL-Phasen übersichtlich darstellen zu können.
- Performance: Besitzt ihr Unternehmen riesige Datenbestände, so ist die generelle Performance des jeweiligen Tools ebenfalls wichtig. Im Rahmen der Verarbeitung großer Datenmengen sollten daher keinerlei Probleme auftreten.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Fazit
Die im ETL-Prozess gesammelten Daten bieten Entscheidungsträgern eine verbesserte und detailliertere Übersicht über die Lage des Unternehmens. Dadurch rückt das Bauchgefühl in den Hintergrund und Entscheidungen lassen sich auf Basis von Daten und Fakten treffen.
Schließlich bietet die Integration eines ETL-Prozesses die Möglichkeit, dass alle gesammelten Daten sinnvoll genutzt werden können, damit die Verschwendung wertvoller Ressourcen gemindert wird.
Nutzen auch Sie die Vorteile eines ETL-Prozesses, um die Effizienz Ihres Unternehmens zu steigern. Haben Sie Fragen zu diesem Thema und benötigen Hilfestellung? Kontaktieren Sie mich gerne.
FAQ: Die wichtigsten Fragen schnell beantwortet
Die Abkürzung ETL steht für die drei Teilschritte Extract, Transform, Load im Datenverarbeitungsprozess. Hier werden Daten in den drei Schritten extrahiert, transformiert und in den Zielablageort geladen.
Wir verwenden ETL immer dann, wenn wir Daten von einer Datenquelle in eine andere Datenquelle laden wollen, wie zum Beispiel in einen Data Lake oder ein Date Warehouse. Der Schritt der Transformation dient der Umwandlung von unstrukturierten in strukturierte Daten.
Durch den ETL-Prozess ist es Unternehmen möglich, ihre Daten zuverlässig zu verwalten und für Machine Learning oder Business Intelligence Analysen zu verwenden. So können beispielsweise Prognosen zu Themen wie dem Churn oder dem langfristigen CLV jedes Kunden erstellt werden.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte

