Was Sie zum Schutz personenbezogener Daten wissen müssen
Daten sind das Fundament moderner Analytics- und KI-Initiativen – gleichzeitig steigen die Anforderungen an Datenschutz, Compliance und Transparenz kontinuierlich. Unternehmen stehen vor der Herausforderung, personenbezogene Daten (PII) über komplexe Datenpipelines hinweg sicher zu identifizieren, zu schützen und regelkonform zu verwalten.
Databricks adressiert diese Anforderungen mit einem ganzheitlichen Ansatz für Data Privacy im Lakehouse. Statt isolierter Einzellösungen verbindet Databricks Data Discovery, Schutzmechanismen und Governance zu einem durchgängigen Konzept.
Lassen Sie uns starten!
Identify Protect, Manage – Die drei Säulen für einen sicheren Umgang mit personenbezogenen Daten
Der sichere und rechtskonforme Umgang mit personenbezogenen Daten erfordert einen strukturierten, ganzheitlichen Ansatz. Databricks verfolgt ein Ordnungsprinzip, das Data Privacy entlang des gesamten Datenlebenszyklus abbildet. Das zugrunde liegende Modell basiert auf drei zentralen Säulen: Identify, Protect und Manage:

Diese bauen logisch aufeinander auf und schaffen die Voraussetzung, Datenschutzanforderungen wie DSGVO oder CCPA skalierbar, nachvollziehbar und technisch sauber umzusetzen.
Wir erläutern zunächst diese 3 Säulen allgemein. Anschließend zeigen wir auf, welche Möglichkeiten und Funktionen Databricks für deren Umsetzung bietet.
1. Identify
Unternehmen müssen zunächst verstehen, welche personenbezogenen Daten (PII) sie verarbeiten und wo diese liegen.
Lesen Sie auch:
Dazu gehören:
- Data Discovery: Vollständige Dateninventuren helfen, sensible Informationen zu finden und zu kategorisieren.
- Data Classification: Klassifizierung nach Sensitivität – etwa PII, Finanz- oder Gesundheitsdaten – ermöglicht passende Schutzmaßnahmen.
- Data Mapping: Transparenz über Datenflüsse, Speicherorte und Zugriffsrechte ist essenziell für spätere Datenschutz- und Compliance-Prozesse.
2. Protect
Sind die Daten identifiziert, müssen technische und organisatorische Maßnahmen greifen:
- Data Security Measures: Verschlüsselung, Zugriffskontrollen und Firewalls schützen vor unbefugtem Zugriff.
- Data Handling: Datenminimierung und die Beschränkung der Verarbeitung auf das geschäftlich Notwendige unterstützen die DSGVO-Konformität.
3. Manage
Ein nachhaltiger Datenschutzansatz benötigt laufende Steuerung und Überwachung:
- Data Governance: Richtlinien und Prozesse definieren den verantwortungsvollen Umgang mit personenbezogenen Daten.
- Compliance Management: Sicherstellung der Einhaltung von DSGVO, CCPA, HIPAA und weiteren Standards.
- Monitoring & Auditing: Regelmäßige Überprüfung der Datenschutzpraktiken, um Risiken frühzeitig zu erkennen.
Wie schützen Sie Ihre Daten in Databricks?
Der Unity Catalog setzt die bereits beschriebenen „drei Säulen“ der Data Privacy systemseitig um. Die folgende Grafik zeigt dabei auf, bei welchen Schritten Sie Databricks unterstützt. Die Punkte, die Databricks nicht berücksichtigt, sind vor allem organisatorischer Natur:

In diesem Abschnitt gehen wir auf die Funktionalitäten im Detail ein.
Identify: System Tables & Catalog Explorer
Databricks bietet mit dem Unity Catalog grundsätzlich zwei Möglichkeiten, Zugriffe der Nutzer zu identifizieren, klassifizieren und zu verwalten: System Tables und Catalog Explorer.
Data Discovery: Wo sind PII-Daten?
Eine wesentliche Frage in Bezug auf Data Privacy ist, wo sich PII-Daten überhaupt befinden. Databricks bietet zunächst zwei „klassische“ Möglichkeiten: Die manuelle Suche über die System Tables und die grafisch unterstütze Suche über den Catalog Explorer. Viel komfortabler ist jedoch die PII-Erkennung, die Ihnen mithilfe einer künstlichen Intelligenz potenzielle PII-Daten ausliest. Im Folgenden werden diese Möglichkeiten grundsätzlich erläutert.
System Tables
Die Grundlage aller Abfragen bilden die System Tables. Hier können Sie sämtliche Informationen ermitteln. Im Folgenden sind die für uns wichtigsten Tabellen aufgeführt:

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Object Metadata:
Über die System- und Information-Schema-Tabellen ermöglicht Databricks eine tiefgehende Transparenz über Kataloge, Tabellen und Berechtigungen.
Unternehmen können zentral nachvollziehen:
- Welche Tabellen in einem bestimmten Katalog existieren
- Wer Zugriff auf eine bestimmte Tabelle hat
- Wer goldene Tabellen zuletzt aktualisiert hat
- Wem eine Tabelle gehört
Dies erleichtert Governance, Ownership-Management und technische Dokumentation enorm.
Lesen Sie auch:
Billing Logs:
Die Billing-Systemtabellen liefern detaillierte Einblicke in den Ressourcenverbrauch.
Typische Auswertungen umfassen:
- Tägliche DBU-Verbrauchstrends
- Nutzung einzelner SKUs im Monatsverlauf
- Welche Benutzer die meisten DBUs verbrauchen
- Welche Jobs die höchsten Kosten verursachen
Damit lassen sich Kosten transparent analysieren und Optimierungsmaßnahmen datenbasiert steuern.
Databricks Beratung mit Datasolut
Wir sind zertifizierte Databricks Partner und wissen auf was es ankommt.
Audit Logs:
Audit Logs ermöglichen nahezu in Echtzeit die Beantwortung kritischer Sicherheits- und Compliance-Fragen:
- Welche Tabelle wurde am häufigsten aufgerufen?
- Wer hat eine bestimmte Tabelle gelöscht?
- Was hat ein bestimmter Nutzer in den letzten 24 Stunden getan?
- Welche Tabellen werden von einem Nutzer besonders häufig abgefragt?
Diese Informationen unterstützen Security Monitoring, Incident Response und interne Audits.
Lineage Data:
Die Lineage-Systemtabellen decken Datenflüsse im Lakehouse ab – sowohl auf Tabellenebene als auch auf Spaltenebene:
- Welche Tabellen speisen eine bestimmte Zieltabelle?
- Welche User Queries lesen von einer bestimmten Tabelle?
Dies erleichtert Impact-Analysen, Fehlerdiagnosen und Change-Management in komplexen Datenplattformen.
Catalog Explorer
Mit dem Catalog Explorer gibt es auch eine grafische Anzeigemöglichkeit für diese Fragestellungen und Auskünfte.
Er ist das zentrale UI-Werkzeug, um alle Datenobjekte einer Databricks-Umgebung sichtbar, durchsuchbar und verwaltbar zu machen. Er bringt Datenkatalogisierung, Governance und Berechtigungsmanagement in eine einheitliche, intuitive Oberfläche:

PII-Erkennung
Die PII-Erkennung ist eine Funktion, welche Ihnen mittels einer KI potenzielle PII-Daten ausliest. Sie erstellt eine Liste von potenziellen PII-Informationen / Datensätzen, die man anschließend verschlüsseln kann. Diese Funktion beinhaltet sowohl Data Discovery als auch eine Möglichkeit der Data Classification.
Auf dem folgenden Screenshot haben wir dazu die Funktion Data Classification für einen Demo-Catalog aktiviert:

Über den Button View results kann man die Ergebnisse einsehen. Dabei werden Tags zur Klassifizierung direkt vorgeschlagen:

Der Button Review führt zur Detailansicht. Hier können automatisch Tags vergeben werden und auch Policies definiert und zugeordnet werden:

Data Classification: PII-Daten klassifizieren
Sobald die PII-Daten identifiziert wurden, kann man den Zugriff zu diesen Informationen auf verschiedene Arten reduzieren. So ist es in der Regel ratsam, PII-Daten mit Tags zu versehen und damit zu klassifizieren. (siehe vorherige Screenshots)
Über Sicherheitsrichtlinien (Policies) können Zugriffsrechte verwaltet werden.
Zum Verschlüsseln der Daten gibt es verschiedene Wege, die wir an späterer Stelle nochmal aufgreifen.
Data Mapping
Das Data Mapping beschreibt eine externe PII-Dokumentation. Sie wird beispielsweise als Microsoft Excel-Liste geführt und identifiziert die Daten, die geschützt werden müssen.
In der Regel beschreibt das Data Mapping weiterhin, wie – also mit welchen Schutzmechanismen (z.B. Masking oder Hashing) – bestimmte PII-Daten zu schützen sind.
Protect: So schützen Sie Daten in Databricks
In der Protect-Säule geht es um den eigentlichen Schutz der personenbezogenen Daten. Dabei erklären wir zunächst, wie Databricks generell abgesichert und verschlüsselt ist. Anschließend erklären wir in einer tabellarischen Übersicht, mit welchen Mechanismen Sie diese Daten schützen können.
Data Security Measures
Das Unity Catalog Security Model
Das Unity Catalog Security Model vereinheitlicht Zugriffe bzw. Anfragen. Sämtliche Anfragen werden gegen die Autorisierungseinstellungen des Unity Catalogs geprüft. So wird ein Wildwuchs der Berechtigungseinstellungen auf den verschiedenen Technologien, wie z.B. Data Lakes, Metadata, Data Warehouses sowie Machine Learning und AI-Anwendungen, entgegenzuwirken.
Somit entfallen auch Einschränkungen, wie fehlende Berechtigungseinstellungen auf Zeilen- und Spaltenebene in einem Data Lake.
Das folgende Schaubild beschreibt diesen Prozess:
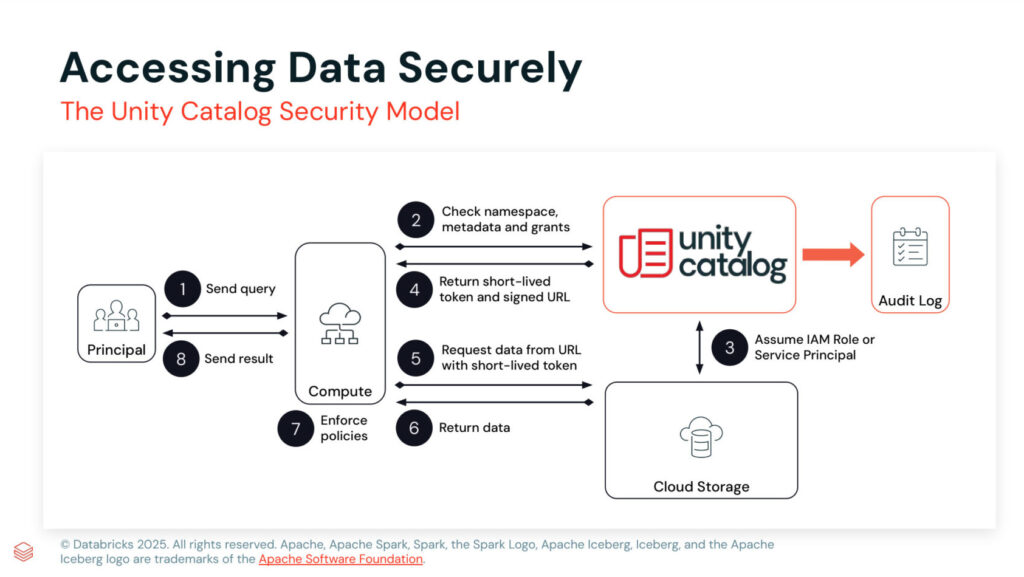
- Senden der Anfrage: Die zuständige Compute-Ressource verarbeitet die Anfrage.
- Die Anfrage wird an den Unity Catalog weitergeleitet:
Sie wird protokolliert und gegen alle Sicherheitsrichtlinien und Zugriffsberechtigungen, die im Metastore definiert sind, überprüft. - Für jedes Objekt in der Abfrage übernimmt Unity Catalog die notwendige Cloud-Zugangsberechtigung: Bei Managed Tables ist dies die dem Metastore zugeordnete Cloud Storage-Berechtigung. Bei externen Tabellen oder Dateien wird ein externer Speicherort verwendet, der über ein Storage Credential abgesichert ist.
- Für jedes Objekt generiert Unity Catalog ein temporäres, eingeschränktes Token sowie eine signierte URL: Diese erlaubt es dem Compute-Service, direkt und sicher auf die benötigten Daten im Storage zuzugreifen.
- Der Compute fordert die Daten mittels der signierten URL und des kurzlebigen Tokens an.
- Der Storage liefert die angeforderten Daten an Compute zurück.
- Der Compute setzt alle geltenden Richtlinien durch, einschließlich Row-Level- und Column-Level-Security sowie Masking-Regeln.
- Der Compute sendet das finale Abfrageergebnis an den Nutzer zurück.
Daten und Workload-Isolation
Ein weiterer Baustein einer sicheren Datenplattform ist die konsequente Trennung von Daten und Workloads. Databricks ermöglicht diese Isolation auf mehreren Ebenen – je nach Schutzbedarf und Organisationsstruktur des Unternehmens.
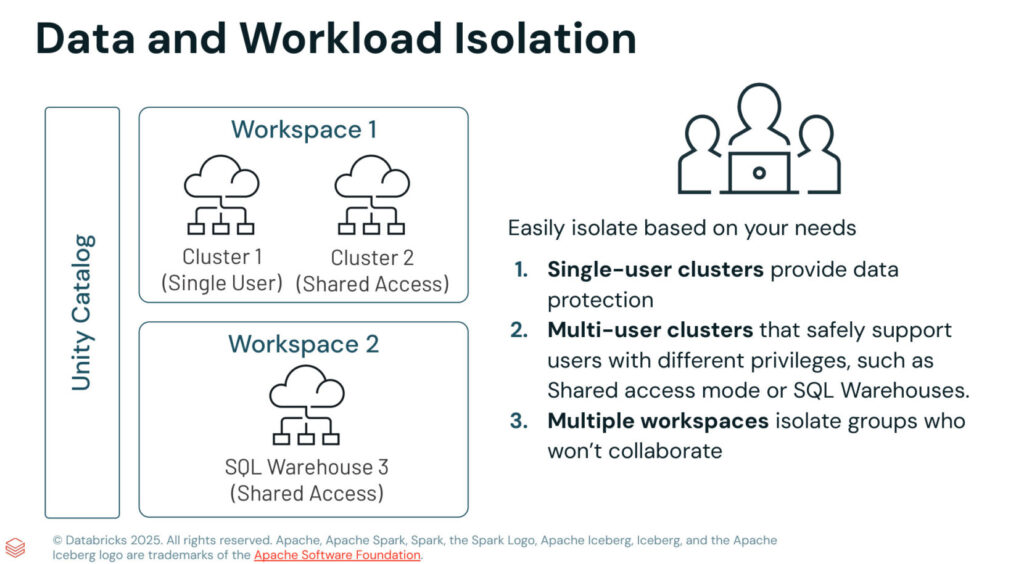
Zunächst lassen sich Single-User-Cluster nutzen, um maximale Datensicherheit zu gewährleisten. Diese Cluster werden ausschließlich von einer Person verwendet und eignen sich beispielsweise für sensible Prototypen oder POCs, bei denen keine Vermischung von Berechtigungen erfolgen darf.
Für kollaborative Szenarien stehen Multi-User-Cluster im Shared Access Mode oder SQL Warehouses bereit. Sie ermöglichen eine kontrollierte gemeinsame Nutzung, ohne dass die zugrunde liegenden Berechtigungen verletzt werden. Rollenbasierte Zugriffe und Unity Catalog regeln präzise, welche Daten Anwender einsehen dürfen.
Eine zusätzliche Ebene der Isolation bieten separate Workspaces. Teams, die nicht miteinander arbeiten oder unterschiedliche Compliance-Anforderungen haben, können vollständig getrennt voneinander agieren – inklusive eigener Cluster, SQL Warehouses und Berechtigungsstrukturen. Damit lassen sich etwa Entwicklungs-, Test- und Produktivumgebungen sauber voneinander abgrenzen.
Das Zusammenspiel dieser Mechanismen sorgt dafür, dass Unternehmen Daten sicher bereitstellen können, ohne Flexibilität oder Zusammenarbeit einzuschränken.
Encryption by default
Bei Databricks werden sämtliche Datenflüsse und Speicherbereiche automatisch verschlüsselt. Dadurch wird sichergestellt, dass sensible Informationen jederzeit geschützt bleiben.
Databricks verschlüsselt standardmäßig:
- Alle Verbindungen zwischen Control Plane und Data Plane
- Alle Verbindungen zwischen Usern und der Control Plane
- Sämtliche Speicherbereiche innerhalb des Databricks-Kontos
- Alle EBS-Volumes
- Den gesamten Datenverkehr zu AWS APIs

Während Daten übertragen werden, kommen TLS/SSL-Protokolle zum Einsatz, die eine sichere Kommunikation gewährleisten. Im Ruhezustand schützt AES-256-Verschlüsselung Daten in Azure Storage und auf Amazon EBS.
Für besonders sensible Informationen innerhalb der Control Plane setzt Databricks zusätzlich auf Envelope Encryption: Dabei wird der eigentliche Datenschlüssel (DEK) zunächst mit einem Customer-Managed Key (CMK) verschlüsselt und anschließend erneut mit einem Databricks-verwalteten Schlüssel geschützt. Unternehmen behalten damit die volle Kontrolle über ihre Schlüsselverwaltung, während Databricks die technische Umsetzung sicherstellt.
Diese konsequente „Encryption by Default“ schafft ein hohes Sicherheitsniveau und reduziert gleichzeitig den Administrationsaufwand erheblich – ein zentraler Vorteil für Unternehmen, die Skalierbarkeit und Compliance gleichermaßen im Blick haben.
Data Handling
Dem Schutz von persönlich identifizierbaren Informationen ist ein kritischer Aspekt im Umgang mit Daten. Databricks bietet hierzu eine Vielzahl an Schutzmechanismen.
Schutz von persönlich identifizierbaren Informationen (PII): Ein Überblick
In der folgenden Tabelle sind Diese aufgeführt. Dabei haben wir zusätzlich Vor-, Nachteile und ein Schutzlevel angegeben:
| Technik | Beschreibung | Beispiel | Anwendungsfälle | Vorteile | Nachteile | Schutzniveau |
|---|---|---|---|---|---|---|
| Daten-maskierung | Verbirgt Original-daten durch ver-änderte Inhalte. Dynamische Maskierung in Databricks ermöglicht die Definition von Maskierungsregeln. | gXXX.dXXXX@datasolut.com | Schutz sensibler Daten bei gleich-zeitiger Erhaltung der Nutzbarkeit. | – Daten-format bleibt erhalten – Teil-informationen können bestehen bleiben und die Privatsphäre wird erhöht | -Daten-verteilung ändert sich – Rück-schluss über verbundene Spalten möglich – Nicht zur Verknüpf-ung von Daten geeignet | Niedrig bis Mittel |
| Pseudo-nymisierung | Ersetzt Werte durch Pseudonyme oder andere künstliche Werte. | peter.pan@datasolut.com | Medizinische Studien, bei denen Patienten über Zeit verfolgt werden müssen, ihre Identität aber geschützt bleibt. | – Statistische Verteilung bleibt erhalten – Verknüpfung mehrerer Datensätze möglich | – Rückschluss auf Originalwerte aus Verteilungen möglich – Re-Identifikation über verbundene Spalten möglich – Zuordnung zum Originalwert muss sicher gespeichert werden | Niedrig bis Mittel |
| Hashing | Transformation von Daten in eine irreversible Zeichenkette. | cf35dd9aafff028e5dcc… | Speicherung von Passwörtern | – Sicher und nicht umkehrbar – Datenverknüpfung möglich – Statistische Verteilung bleibt erhalten | – Rückschlüsse aus Hash-Verteilungen möglich – Wiederherstellung der Originaldaten nicht möglich | Mittel bis Hoch |
| Spaltenverschlüsselung (Column Encryption) | Verschlüsselt Daten auf Spaltenebene. In Databricks werden sensible Daten vor der Speicherung verschlüsselt. | 0582e62c284e8ad8d… | Absicherung einzelner besonders sensibler Datenspalten | – Sehr hohes Sicherheitsniveau – Einzelwerte und Verteilungen werden verschleiert | – Erfordert Schlüsselmanagement – Datenmenge steigt deutlich – Datenverknüpfung erschwert – Datenverteilung verändert sich | Hoch |
| Tokenisierung | Ersetzt sensible Daten durch Tokens. | d08fa46b7a79e1201d… | Kreditkartentransaktionen | – Tokens können echte Daten in operativen Prozessen ersetzen | – Erfordert ein robustes Tokenisierungssystem – Bei Kompromittierung des Token-Systems sind alle Daten rekonstruierbar | Hoch |
Sie wollen erfahren, wie Sie diese Schutzmechanismen in Databricks umsetzen können? Dann klicken Sie auf diesen Artikel.
Manage: So verwalten Sie Daten in Databricks
Databricks unterstützt Sie beim Managen der Zugriffe auf Ihre Daten. Dabei spielt der Unity Catalog die zentrale Rolle bei der Umsetzung bzw. bildet eine vollständige Data Governance-Lösung.
Data Governance
Als Basis für die Data Governance ist eine Datenvereinheitlichung von elementarer Bedeutung. Der Unity Catalog bietet: Eine einheitliche Sicht auf alle Daten- und KI-Assets über verschiedene Plattformen hinweg, die Duplikate reduziert und unkontrollierte Daten- und Tool-Zersplitterung vermeidet.
Weiterhin ist die Zugriffskontrolle ein zentraler Punkt. Wer hat welche Zugriffe? Gibt es Probleme für Anwender? Die Vergabe und Verwaltung von Berechtigungen (auch Rollen- und/oder Attributs-basiert), sowie die auf externe Systeme sind hier als Kernaufgaben des Unity Catalogs hervorzuheben.
Die Data Discoverbility oder Daten-Auffindbarkeit beschreibt die Möglichkeit, relevante Daten und Datenprodukte schnell, einfach und zuverlässig zu finden, zu verstehen und zu nutzen. Auch hier bietet Databricks Funktionen wie den Catalog Explorer zum Durchsuchen und Auffinden von Daten und Metadaten wie Kommentaren und Tags.
Weiterhin hervorzuheben ist die Data Lineage zur transparenten Nachverfolgbarkeit von Daten über ihren gesamten Lebenszyklus hinweg. Wo kommen Daten her? Wo und von wem werden sie verwendet?
Data-Quality-Monitoring hilft dabei, die Qualität aller Daten-Assets im Unity Catalog sicherzustellen. Es umfasst Anomalie-Erkennung, um die Datenqualität aller Tabellen in einem Katalog oder Schema zu überwachen, sowie Daten-Profiling, um die statistischen Eigenschaften und die Qualität der Daten einer einzelnen Tabelle kontinuierlich zu analysieren.
Datenkollaboration und Datenaustausch:
Der Unity Catalog ermöglicht es Ihren Anwendern, innerhalb derselben Region Workspace-übergreifend auf dieselben Daten zuzugreifen und gemeinsam daran zu arbeiten. Wenn eine Zusammenarbeit über verschiedene Workspace-Regionen, Organisationen oder Plattformen hinweg erforderlich ist, stellt Unity Catalog die Grundlage für verschiedene Sharing-Mechanismen, wie beispielsweise Delta Sharing, bereit.
Compliance Management
Compliance Management bezeichnet die systematische Umsetzung, Überwachung und Durchsetzung von regulatorischen, rechtlichen und internen Vorgaben beim Umgang mit Daten, Analytics und KI-Workloads auf der Datenplattform. In Databricks sind wesentliche externe Vorgaben, wie beispielsweise GDPR (EU) oder CCPA (USA), im Standard umsetzbar.
In diesen Regulierungen wird vor allem definiert, welche Nutzergruppen, welche Zugriffe auf PII-Daten erhalten. Ein weiterer zentraler Baustein ist das „Recht auf Vergessenwerden“ (Right to Be Forgotten, RTBF) bzw. das Recht auf Löschung der eigenen Daten.
Eine Übersicht der umsetzbaren Regulierungen und Zertifikate finden Sie unter dem folgenden Link: Databricks trust compliance
Unternehmen sind verpflichtet, sämtliche personenbezogenen Daten (PII), die sie über einen Kunden gespeichert haben, vollständig und dauerhaft zu löschen, sobald der Kunde dies ausdrücklich verlangt.
Weitere Informationen können unter folgendem Link eingesehen werden: Databricks AWS security
Bei stark regulierten Unternehmen kann bei Bedarf das Add-On Enhanced Security and Compliance auf Databricks installiert werden. Damit werden auch spezielle bzw. branchenspezifische Regularien (z.B. Health Insurance Portability and Accountability Act – HIPAA) umsetzbar.

Monitoring & Auditing
Monitoring ist der Prozess der kontinuierlichen Überwachung und Analyse der Leistung, Qualität und Nutzungsmuster von Anwendungen oder Systemen.
Databricks stellt Audit-Logs bereit, mit denen sich Benutzeraktionen, Datenzugriffe und Sicherheitsereignisse überwachen und nachvollziehen lassen. Diese Protokolle sind besonders wichtig für Compliance-Anforderungen, das Sicherheitsmonitoring und das Verständnis, wie Daten in Ihrer Umgebung genutzt werden.
Hier ist eine Auflistung von klassischen Monitoren/Logs:
- Nutzer-Aktionen (Queries, Tabellenzugriffe, etc.)
- Logins & Konfigurationsänderungen
- Berechtigungsänderungen
- Tabellenerzeugung, -löschung, -änderung
Der folgende Screenshot zeigt eine einfache Abfrage der zugrundeliegenden system.access.audit-Tabelle:

Löschen von PII-Daten
Das gezielte Löschen personenbezogener Daten (PII) ist ein zentraler Baustein für Data Privacy in Databricks. Die Löschung muss strikt nach Datenschutzvorgaben wie GDPR und CCPA erfolgen.
Da klassische ETL-Pipelines meist append-only arbeiten, werden Löschprozesse in separaten Pipelines umgesetzt.
Über Delta Lake lassen sich PII-Daten regelkonform und nachvollziehbar entfernen – etwa durch DELETE- und MERGE-Operationen auf Tabellenebene oder durch logische Löschkonzepte in Kombination mit Time Travel. In Verbindung mit dem Unity Catalog können Löschprozesse zentral gesteuert, auditiert und mit Data-Governance-Richtlinien verknüpft werden.
Fazit
Data Privacy ist kein isoliertes Feature, sondern eine zentrale Eigenschaft moderner Datenplattformen. Databricks zeigt mit dem Zusammenspiel aus Lakehouse-Architektur und Unity Catalog, wie sich Datenschutzanforderungen strukturiert, skalierbar und praxisnah umsetzen lassen.
Das Identify–Protect–Manage-Modell schafft eine klare Leitlinie entlang des gesamten Datenlebenszyklus – von der Identifikation und Klassifizierung von PII über technische Schutzmechanismen bis hin zu Governance, Monitoring und regelkonformer Löschung.
Unternehmen profitieren dabei von einer einheitlichen Sicherheits- und Governance-Schicht, die Analytics, BI und KI gleichermaßen abdeckt, ohne Innovationsgeschwindigkeit oder Zusammenarbeit einzuschränken.
Entscheidend ist jedoch: Technische Funktionen allein reichen nicht aus. Erst im Zusammenspiel mit klaren organisatorischen Prozessen, Verantwortlichkeiten und einer durchdachten Datenstrategie entfaltet Databricks sein volles Potenzial als datenschutzkonforme Daten- und KI-Plattform.
Sie benötigen Unterstützung oder weitere Informationen rund um das Thema? Dann vereinbaren Sie gerne einen unverbindlichen Beratungstermin mit uns!

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte