


Der Delta Lake ist ein Open-Source-Speicherformat, welches das Parquet-Format um ACID-Funktionalität und weiteren Datenbankfeatures erweitert. Die Zuverlässigkeit, Sicherheit und Leistung des Data Lake wird durch das Delta Lake Format verbessert. Es unterstützt ACID-Transaktionen, skalierbare Metadaten, Zeitreise, Change Data Capture Funktionalitäten für Streaming und Batch-Datenverarbeitung.
In diesem Beitrag beschäftigen wir uns damit, was das Delta Lake Format ist, wie es funktioniert und wofür Sie es im Aufbau eines Data Lakes verwenden können.
Lassen Sie uns direkt ins Thema einsteigen.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Was ist das Delta Lake Format?
Ein Delta Lake ist ein Open-Source-Dateiformat, welches darauf ausgelegt ist, die Nachteile klassischer Data Lakes zu minimieren und somit die Zuverlässigkeit, Sicherheit und Leistungsfähigkeit eines Data Lakes zu verbessern. Das Speicherformat Delta Lake unterstützt ACID-Transaktionen, skalierbare Metadaten, vereinheitlichtes Streaming und die Verarbeitung in Batches.
Delta Lake setzt also da an, wo ein Data Lake reinbasierend auf Parquet- und CSV-Dateien viele Nachteile mit sich bringt. Dem Parquet-Format, worauf auch Delta Lake basiert, fehlen grundsätzliche Funktionalitäten einer Datenbank. So kann man in einer Parquet-Datei keine Datensätze löschen, ohne die komplette Datei erneut wegzuschreiben. Delta Lake stellt wichtige Eigenschaften wie Updates, Deletes oder Inserts zur Verfügung und erweitert somit das Parquet-Format.
Data Lakes bringen folgende Herausforderungen mit sich:
- Data Lakes sind wenig strukturiert, da Sie hier alle Daten abspeichern können
- Im Data Lake liegen häufig kleine, unstrukturierte Daten vor, die schwer zu lesen sind
- Nicht selten liegen im Data Lake beschädigte Daten, die nicht zu analysieren sind
Diese Herausforderungen erschweren die verlässliche Analyse von großen Datenmengen und man läuft Gefahr, falsche Ergebnisse und Erkenntnisse im Bereich BI oder Machine Learning zu produzieren.
Im Folgenden schauen wir uns an, wie die Delta-Lake-Funktionalitäten diese Nachteile eliminieren.
Wie funktioniert Delta Lake und wie sieht die Architektur aus?
Delta Lake erweitert die offene Parquet-Speicherumgebung für strukturierte, halbstrukturierte und unstrukturierte Daten mit einer Ebene für intelligentes Datenmanagement und Governance. So unterstützt die Speicherschicht sowohl Streaming- als auch Batch-Operationen aus einer einzigen Quelle.
Um die Funktionsweise von der Speicherschicht zu verstehen, ist es notwendig, die Funktionsweise von Transaktionsprotokollen zu kennen. Das Transaktionsprotokoll ist der rote Faden, der sich durch viele der wichtigsten Funktionen zieht, darunter ACID-Transaktionen, skalierbare Metadatenverarbeitung, Zeitreisen usw.
Delta Lake bietet ACID-Transaktionen über ein Protokoll, das mit jeder in Ihrem Speicherkonzept erstellten Delta-Tabelle verknüpft ist. Dieses Protokoll zeichnet die Historie aller Vorgänge auf, die jemals an dieser Datentabelle oder diesem Datensatz vorgenommen wurden, wodurch Sie ein hohes Maß an Zuverlässigkeit und Stabilität für Ihren Data Lake erhalten.
Wann immer ein Benutzer einen geänderten Befehl ausführt, unterteilt die Speicherschicht diesen in eine Reihe von Schritten, die aus einer oder mehreren Aktionen bestehen. In der folgenden Abbildung sehen Sie die einzelnen Schritte, die Daten in einem Delta Lake durchlaufen.
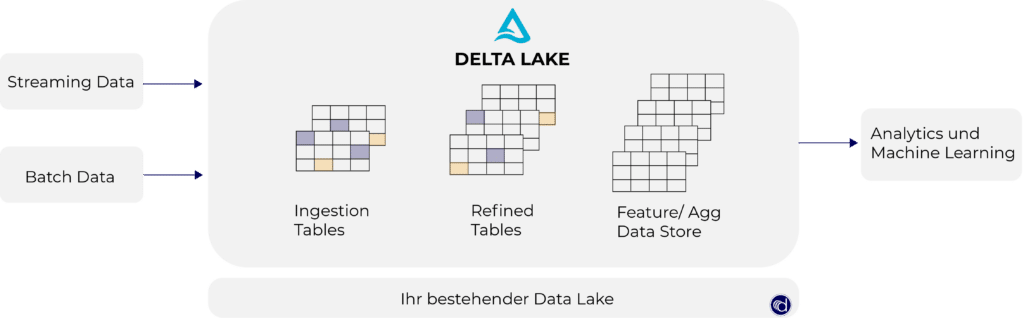
Sehen wir uns nun an, welche Merkmale ein Delta Lake besitzt und welche Vorteile diese Merkmale bringen.
Was sind die Merkmale und Vorteile von Delta Lake?
Der Delta Lake ist eine Speicherschicht aufbauend auf einem bestehenden Data Lake. Diese Speicherschicht verfügt über Merkmale, die die Nachteile des Data Lake ausgleichen. Wir können die Merkmale auf fünf große Punkte aufteilen. Diese Merkmale sind gleichzeitig auch die fünf Vorteile der Speicherschicht.
Die fünf größten Vorteile
- Offenes Format: Delta Lake verwendet das quelloffene Apache Parquet-Format und ist vollständig kompatibel mit der Apache Spark Unified Analytics Engine für leistungsstarke, flexible Operationen.
- ACID-Transaktionen: Delta Lake ermöglicht ACID-Transaktionen (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) für Big Data-Workloads. Es erfasst alle an den Daten vorgenommenen Änderungen in einem serialisierten Transaktionsprotokoll, wodurch die Integrität und Zuverlässigkeit der Daten geschützt und vollständige, genaue Prüfprotokolle bereitgestellt werden.
- Time Travel: Das Transaktionsprotokoll von Delta Lake bietet einen Master-Datensatz für jede an den Daten vorgenommene Änderung, so dass der genaue Zustand eines Datensatzes zu jedem beliebigen Zeitpunkt wiederhergestellt werden kann. Die Datenversionierung macht Datenanalysen und Experimente vollständig reproduzierbar.
- Schema-Durchsetzung: Die Speicherschicht schützt die Qualität und Konsistenz Ihrer Daten mit einer robusten Schemaerzwingung, die sicherstellt, dass die Datentypen korrekt und vollständig sind, und verhindert, dass fehlerhafte Daten kritische Prozesse beeinträchtigen.
- Zusammenführen, Aktualisieren, Löschen: Delta Lake unterstützt DML-Operationen (Data Manipulation Language) einschließlich Merge-, Update- und Delete-Befehlen für Compliance und komplexe Anwendungsfälle wie Streaming-Upserts, Change-Data-Capture, SCD-Operationen (Slow-Changing-Dimension) und mehr.
Ihr Team kennt die Konzepte aber nicht den produktiven Alltag auf der Plattform?
Verstehen ist der erste Schritt – Anwenden der zweite.
Warum sollte man Delta Lakes verwenden?
Die Entwicklung, der Betrieb und die Wartung von Big-Data-Architekturen sind derzeit eine Herausforderung. Streaming-Systeme, Data Lakes und Data Warehouses werden in modernen Datenarchitekturen in der Regel auf mindestens drei Arten eingesetzt.
- Geschäftsdaten werden über Streaming-Netzwerke wie Amazon Kinesis und Apache Kafka übertragen, die eine schnellere Bereitstellung bevorzugen und anschließend in Data Lakes gesammelt. Diese sind für eine groß angelegte, kostengünstige Speicherung ausgelegt und umfassen Apache Hadoop oder Amazon S3.
- Die wichtigsten Daten werden in Data Warehouses hochgeladen, da Data Lakes allein leider nicht in der Lage sind, High-End-Geschäftsanwendungen in Bezug auf Leistung oder Qualität zu unterstützen. Diese haben deutlich höhere Speicherkosten als Data Lakes, sind aber auf erhebliche Performance, Gleichzeitigkeit und Sicherheit getrimmt.
- Ein Batch- und ein Streaming-System bereiten Datensätze gleichzeitig in einer Lambda-Architektur vor, einer gängigen Technik zur Datensatzvorbereitung. Die Ergebnisse werden dann während der Abfragezeit kombiniert, um eine umfassende Antwort zu liefern. Aufgrund der strengen Latenzanforderungen für die Verarbeitung sowohl kürzlich erzeugter als auch älterer Ereignisse erlangte diese Architektur Berühmtheit.
Der Hauptnachteil dieser Architektur ist der Entwicklungs- und Betriebsaufwand, der durch die Wartung zweier unabhängiger Systeme entsteht. In der Vergangenheit wurden Versuche unternommen, Stapelverarbeitung und Streaming in ein einziges System zu integrieren. Allerdings waren die Unternehmen dabei nicht immer erfolgreich.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Eine Schlüsselkomponente der großen Mehrheit der Datenbanken ist ACID. Es ist jedoch eine Herausforderung, das gleiche Maß an Zuverlässigkeit zu bieten, welches ACID-Datenbanken bieten, wenn es um HDFS oder S3 geht.
Delta Lake implementiert ACID-Transaktionen in einem Transaktionsprotokoll, indem es alle im Datensatzverzeichnis vorgenommenen Übertragungen verfolgt. Die Delta Lake-Architektur bietet reliable Isolationsebenen, um die Datenkonsistenz zwischen zahlreichen Benutzern zu gewährleisten.
Wo werden Delta Lakes bereits eingesetzt?
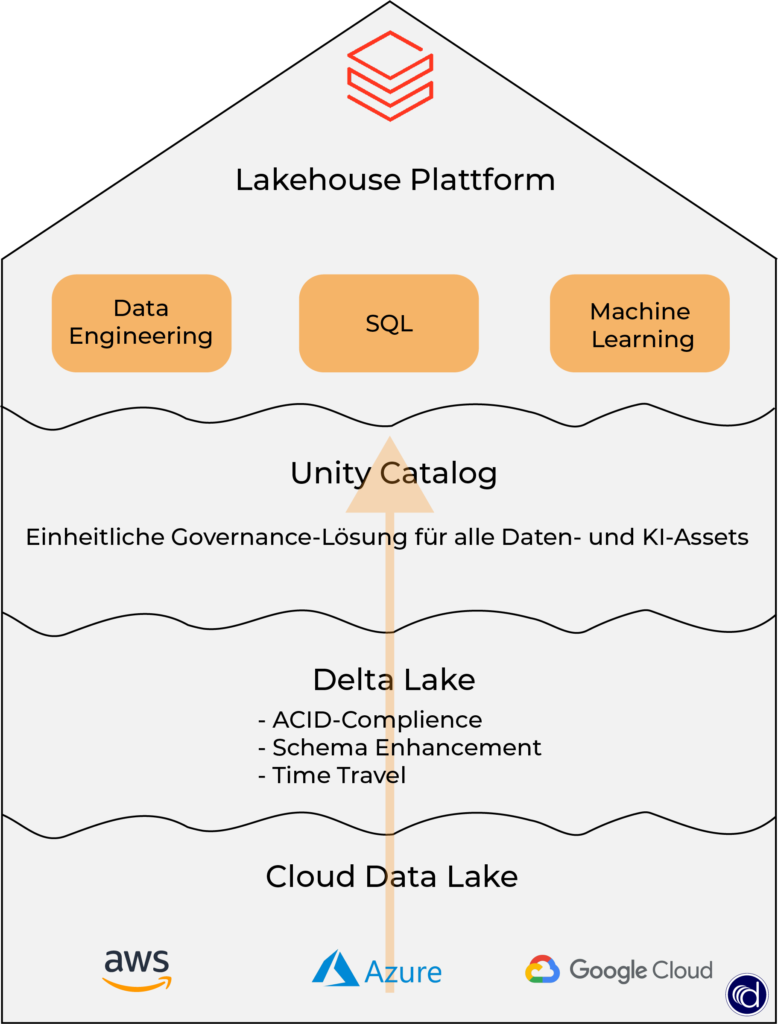
Delta Lake ist eine Technologie, die für den Aufbau robuster Data Lakes verwendet wird und stellt eine Komponente der Cloud Data Platform dar. Die Open-Source-Speicherschicht verleiht Data Lakes Zuverlässigkeit durch Schema Enforcment, ACID-Transaktionen und vielem mehr. In den folgenden drei Fällen wird der Delta Lake erfolgreich zur Optimierung verwendet.
Databricks
Delta Lake wird von Databricks in einem Data Lakehouse Konzept eingesetzt. Das Lakehouse entsteht durch die Verbindung des Data Lakes mit dem Speicherformat Delta Lake. Durch diese Verbindung bietet das Lakehouse die Vorteile des Data Lake und Data Warehouse.
Amazon S3
Amazon S3 verwendet Delta Lake als rohe und kurative Speicherebene im Data Lake. Die Daten werden in Amazon S3 in den Raw-Bucket kopiert. In diesem führt ein AWS Glue-ETL Auftrag die erforderliche Transformation durch und kopiert die Daten in die Delta Lake Ebene. Die Delta Lake Ebene gewährleistet dann die – für Machine Learning und BI – benötigte ACID-Konformität der Quelldaten.
Azure Databricks
Delta Lake ist das Standardspeicherformat für alle Vorgänge in Azure Databricks. Es handelt sich bei den Tabellen in Azure Databricks um Delta-Tabellen. Sofern nicht anders angegeben, sind alle Tabellen auf Azure Databricks Delta-Tabellen. Databricks hat dieses Protokoll ursprünglich entwickelt und trägt weiterhin aktiv zum Open-Source-Projekt bei.
Fazit
So wie sich die Bedürfnisse und Anliegen eines Unternehmens entwickeln, so entwickelt sich auch die Form der Daten. Delta Lake macht es jedoch einfach, zusätzliche Dimensionen hinzuzufügen, wenn sich die Daten ändern. Die Leistung, Zuverlässigkeit und Verwaltbarkeit von Data Lakes werden durch Delta Lakes verbessert.
Delta Lake bietet eine einheitliche Plattform, die sowohl Batch- als auch Stream-Processing-Workloads auf einer einzigen Plattform unterstützt. Daher sind Delta Lakes für Data Operations unverzichtbar.
Sie möchten mehr zum Thema Datenverarbeitung erfahren? Dann kontaktieren Sie uns!
FAQ: Die wichtigsten Fragen schnell beantwortet
Ein Delta Lake ist eine Open-Source-Speicherschicht, die auf einem bestehenden Data Lake ausgeführt werden kann und dessen Zuverlässigkeit, Sicherheit und Leistung verbessert. Delta Lakes unterstützen ACID-Transaktionen, skalierbare Metadaten, einheitliches Streaming und Batch-Datenverarbeitung.
Delta Lakes können effizient mit Stream- und Batch-Datenverarbeitung arbeiten und inkrementelle und Streaming-Workloads problemlos verwalten. Eine Delta Lake-Tabelle ist sowohl eine Stapeltabelle als auch eine Streaming-Senke oder -Quelle. Delta Lake unterstützt die Aufnahme von Streaming-Daten und Backfill-Batch-Daten.
Databricks Lakehouse basiert auf offenen Standards und hat eine Open-Source-Grundlage (Spark). Delta Lake ist ebenfalls Open-Source und kann verwendet werden, um eine Data-Warehousing-Rechenschicht über einem herkömmlichen Data Lake zu ermöglichen. Databricks bietet SQL-Unterstützung und wird von talentierten Ingenieuren unterstützt, die an Apache Spark arbeiten.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte









