Die Databricks-Plattform entwickelt sich rasant weiter – besonders im Bereich der Datenintegration. Zwei zentrale Konzepte stehen dabei im Fokus: Lakehouse Federation und Lakeflow Connect. Beide Ansätze ermöglichen den Zugriff auf Daten aus unterschiedlichen Quellen, unterscheiden sich jedoch grundlegend in Architektur, Performance und Governance.
Außerdem zeigen wir, welche Rolle Materialized Views als Zwischenlösung spielen und wie Sie die passende Strategie für Ihr Unternehmen wählen – von schnellen Proof of Concepts bis hin zu skalierbaren, produktiven Lakehouse-Architekturen.
Aus diesen Unterschieden geht klar hervor, was für Szenarien mit welchem Ansatz angegangen werden sollten. Bei dieser Bewertung greifen wir auf Best Practises aus der Umsetzung in unseren Kundenprojekten zurück.
Vorstellung der Tools: Was ist Lakehouse Federation vs. Lakeflow Connect?
Bevor wir mit den Unterschieden beginnen, stellen wir klar, was Lakehouse Federation und Lakeflow Connect eigentlich ist. Zusätzlich erläutern wir eine dritte Möglichkeit: Lakehouse Federation + Materialized View.
Was ist Lakehouse Federation?
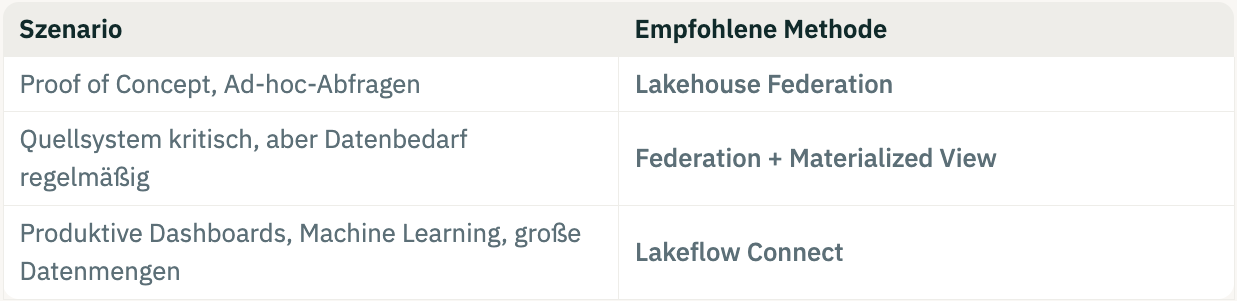
Bei Lakehouse Federation wird eine Tabelle mit Metadaten in den Unity Catalog gespeichert. Man simuliert damit, dass die Tabellen für die Abfragen im Unity Catalog liegen. In Wirklichkeit wird lediglich ein Zeiger (über JDBC) auf die Quelldatenbank (z.B. SQL) gelegt.
Die Datenbank wird im Unity Catalog registriert und somit kann man Abfragen/Queries auf die Quelldatenbank ausführen. Diese werden direkt auf der Datenbank verarbeitet und zurückgeliefert (evtl. aggregiert oder per Select-Anweisung).
Der eigentliche Compute (Aufwand/Leistung) findet also nicht in Databricks, sondern auf dem Quellsystem statt.
Die folgende Grafik verdeutlicht, wie Lakehouse Federation funktioniert:
Welche Datenquellen unterstützt Databricks Lakehouse Federation?
Nicht alle Datenquellen sind mit allen Verfahren nutzbar und wir empfehlen Federation vor allem zum Bewegen kleiner Datenmengen.
Lakehouse Federation unterstützt die folgenden Datenquellen:
- Mircosoft SQL Server
- Databricks
- MySQL
- PostgresSQL
- Teradata
- Oracle
- Amazon Redshift
- Salesforce Data Cloud
- Snowflake
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
Was ist Lakeflow Connect?
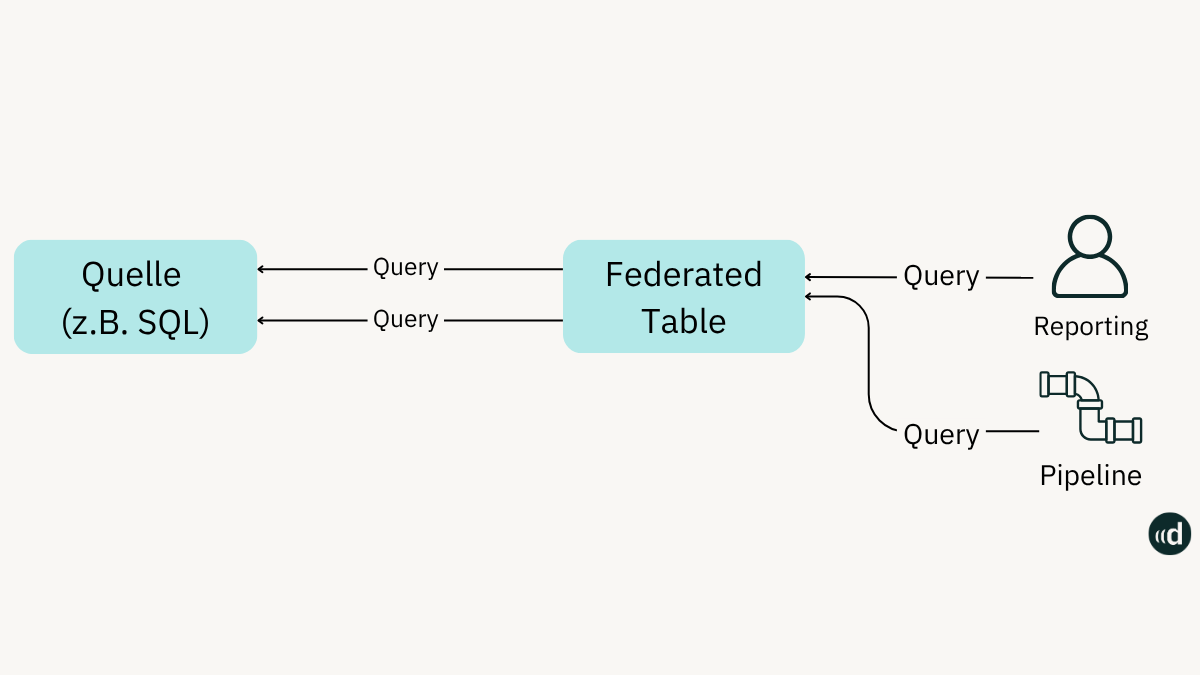
Bei diesem Ansatz erfolgt eine Ingestion über Lakeflow Connect. Der Prozess funktioniert wie folgt:
Über eine Ingestion Pipeline wird die Quelldatenbank (voll oder inkrementell) abgefragt. Die Daten werden von der Pipeline in das Table Format auf dem Cloud Storage abgelegt und gleichzeitig über den Unity Catalog registriert.
Bei einer Abfrage werden die Daten über den Unity Catalog und den Compute, welcher bei Databricks hochgefahren ist, abgefragt und bereitgestellt:
Welche Datenquellen unterstützt Databricks Lakeflow Connect?
Lakeflow Connect unterstützt die folgenden Datenquellen mit Ingestion Connectoren:
- SQL Server
- Google Analytics
- Salesforce
- Workday
- ServiceNow
- Sharepoint
Dabei gibt es teilweise Limitierungen in den Features bzw. der Kompatibilität. Nähere Details hierzu finden Sie in der Databricks-Dokumentation zum Thema Lakeflow-Connect.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Neben den beiden Lösungen gibt es noch eine dritte: Lakehouse Federation feat Materialized View. Diese Lösung ergänzt Federation um die Fähigkeiten von Lakeflow.
Lakehouse Federation + Materialized View:
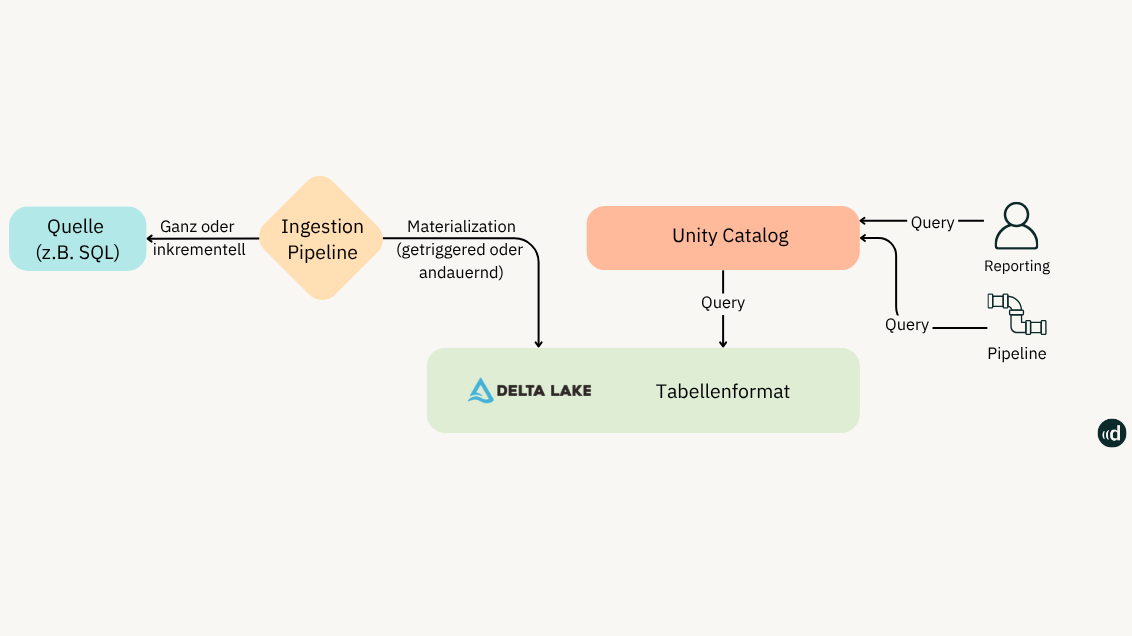
Bei diesem Ansatz handelt es sich um eine Art „Zwischenlösung“ aus Lakehouse Federation und Lakeflow Connect. Wie bei der klassischen Lakehouse Federation wird ein Datenbank-Link zu den föderierten Tabellen im Unity Catalog geschaffen.
Damit die Last der Abfragen nicht auf die Quelldatenbank geht, wird eine Materialized View dazwischen gehängt und Daten persistieren dort. Diese werden in periodischen Abständen (z.B. 1x pro Tag) vom Quellsystem abgerufen und im Unity Catalog materialisiert.
Der Vorteil: Der Compute liegt bei Databricks. Damit wird das operative System, wie beim Lakeflow Connect, entlastet:
Nachdem wir uns alle Tools angesehen haben, schauen wir uns nun die 5 Vergleichspunkte an:
- Performance
- Aktualität
- Kosten
- Governance
- Anwendungsfälle
1. Performance – schnell vs. skalierbar
Wenn Sie mit Datenintegration beginnen, zählt oft Tempo. Mit Lakehouse Federation stellen Sie eine Verbindung zur Quelle her und können sofort loslegen. Die Abfragen laufen direkt auf dem Quellsystem, ohne dass Daten ins Lakehouse kopiert werden. Für Proof of Concepts oder Ad-hoc-Analysen ist das ideal.
Doch je mehr Nutzer und Daten dazukommen, desto stärker leidet die Performance. Abfragen werden langsamer, das Quellsystem wird belastet. Das kann vor allem dann kritisch sein, wenn das Quellsystem im Produktionsbetrieb ist. Durch direkte Anfragen auf die Quelldatenbank können (je nach Anzahl und Umfang) große Lasten auf den operativen Systemen entstehen.
Lakeflow Connect setzt hingegen auf Ingestion. Dabei werden die Daten ins Lakehouse geladen und dort verarbeitet. Der eigentliche Compute findet nicht auf der Quelldatenbank statt. Damit können Sie große Volumina effizient abfragen, Dashboards stabil bereitstellen und viele Nutzer parallel versorgen.
Grundsätzlich gilt also: Wenn Geschwindigkeit/ein schnelles Ergebnis eine zentrale Anforderung ist, kann man zunächst auf Lakehouse Federation setzen. Bei größeren Datenmengen und Zugriffszahlen sollten Sie Lakeflow Connect nutzen. Dieser Ansatz ist nachhaltiger und beeinflusst die operative Arbeit weniger.
Machen Sie Databricks zu Ihrem Wettbewerbsvorteil
Mit unserer Databricks-Beratung entwickeln Sie eine skalierbare Architektur, realisieren produktive Use Cases und befähigen Ihr Team nachhaltig.
2. Aktualität – Echtzeit vs. Refresh-Zyklen
Lakehouse Federation liefert Live-Daten. Jede Abfrage spiegelt den aktuellen Stand im Quellsystem wider. Für kurzfristige Controlling-Reports oder operative Analysen kann das ein Vorteil oder sogar eine Notwendigkeit sein.
Lakeflow Connect arbeitet mit Snapshots oder Change Data Capture (CDC) feeds, die in definierten Intervallen geladen werden – minütlich, stündlich oder täglich. Sie entscheiden, wie aktuell die Daten sein müssen. Damit entlasten Sie das Quellsystem und gewinnen eine konsistente Basis für Transformationen und Machine Learning.
Für Sie auch interessant:
3. Kosten – Storage vs. Quellsystem-Belastung
Lakehouse Federation wirkt auf den ersten Blick günstiger, weil keine zusätzlichen Speicherkosten im Lakehouse anfallen. Doch Abfragen können teuer werden, wenn das Quellsystem belastet wird oder Lizenzgebühren steigen – etwa bei SAP, wo intensive Abfragen zusätzliche Kosten verursachen können.
Lakeflow Connect verursacht zwar Speicherkosten, doch die Abfragen laufen im Lakehouse. Sie können Rechenlast besser steuern, optimieren und planbar budgetieren.
Die folgende Tabelle gibt Aufschluss über zu berücksichtigende Aspekte:
| Aspekt | Federation | Lakeflow Connect |
|---|---|---|
| Storage-Kosten | Keine zusätzlichen Kosten im Lakehouse | Zusätzliche Ingestion-Kosten |
| Quellsystem | Belastung durch viele Abfragen | Entlastung, da Abfragen im Lakehouse |
| Kostenkontrolle | Abhängig von Nutzung und Lizenzen | Planbarer, optimierbar |
4. Governance – Flexibilität vs. Kontrolle
Die Nutzung von Lakehouse Federation bringt Flexibilität. Neue Quellen sind schnell angebunden, Daten sofort verfügbar. Doch mit wachsender Nutzung wird es schwieriger, Governance zentral durchzusetzen.
Lakeflow Connect integriert Governance direkt im Unity Catalog. Damit greifen Zugriffe, Rollen und Policies an einer zentralen Stelle. Besonders in regulierten Branchen ist das ein entscheidender Vorteil: Sie können sicherstellen, dass Compliance- und Audit-Anforderungen eingehalten werden.
Dabei gibt es zwei grundsätzliche Möglichkeiten: Role-Based-Access-Control (RBAC) und Attribute-Based-Access-Control (ABAC).
Bei Ersterem werden Berechtigungen auf der Basis von zugeordneten Rollen auf Databricks-Ebene vergeben:
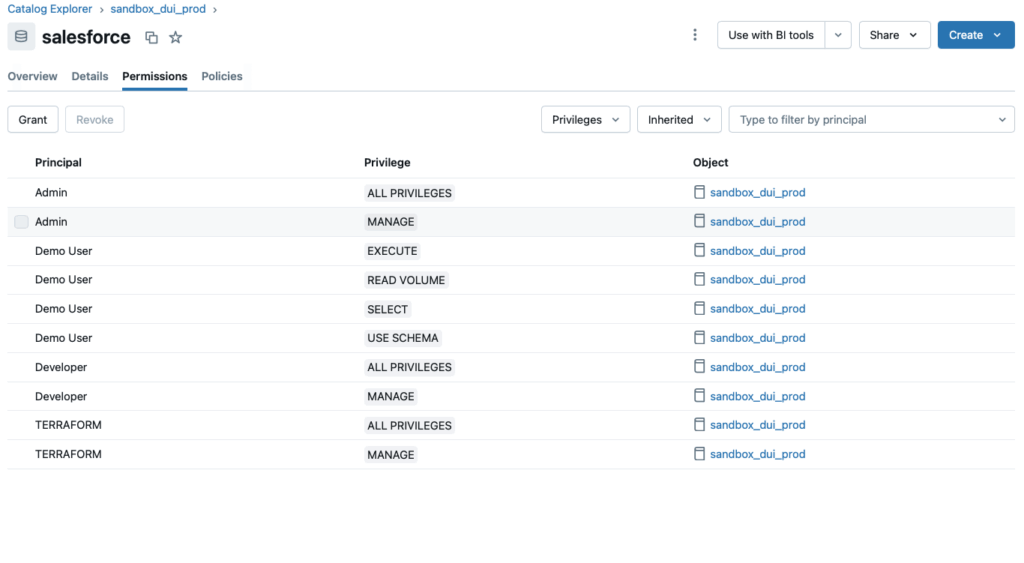
Die zweite Variante beschreibt die Berechtigungen über Attribute. Diese Berechtigungen finden auf Datenbankebene statt:
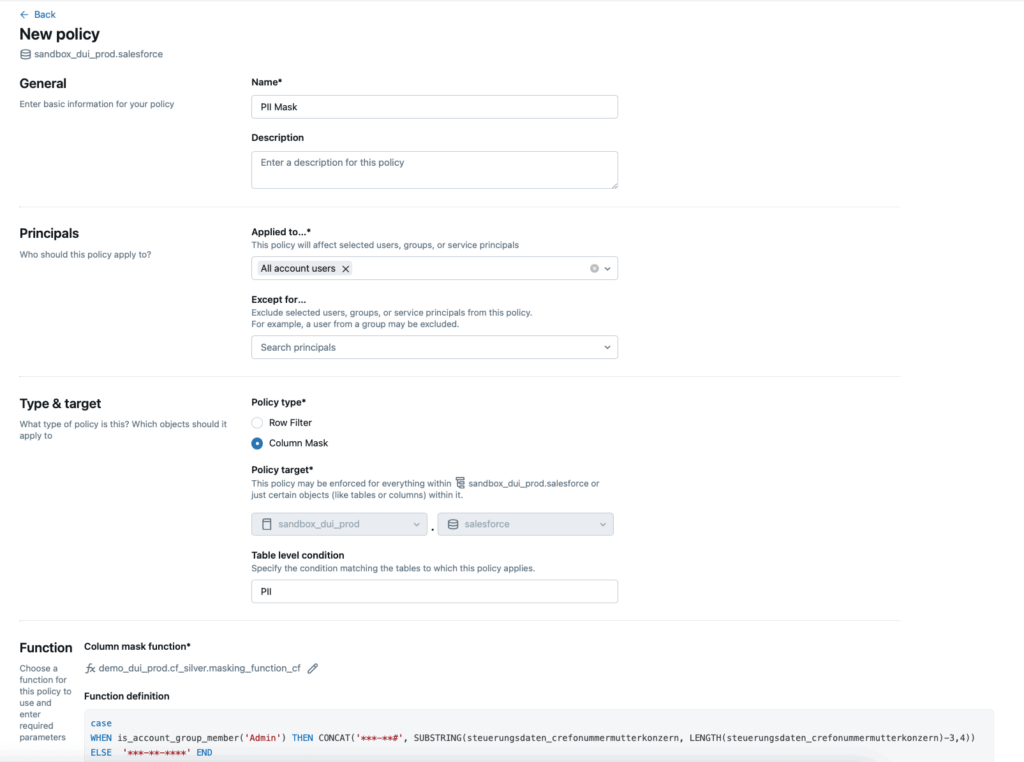
Man kann auch beide Berechtigungsarten kombinieren. Dieses Vorgehen empfehlen wir in der Regel in unseren Projekten. Damit wird die Balance zwischen wenig Pflegeaufwand (RBAC) und dem nötigen Detaillierungsgrad der Berechtigungen (ABAC) sichergestellt.
5. Anwendungsfälle – PoC vs. produktives Lakehouse
Die Wahl zwischen Federation und Connect hängt stark vom Einsatzzweck ab. In der folgenden Tabelle gehen wir kurz auf die Unterschiede der jeweiligen Lösung ein. Anschließend verdeutlichen wir in einer Auflistung typische bzw. geeignete Anwendungsfälle:
| Federation | Federation + MV | Ingestion (LF Connect) | |
|---|---|---|---|
| Ort der Verarbeitung | Quelle | Quelle + Databricks | Databricks |
| Performance | Schnell für kleine Datenmengen | Schnell auch für größere Datenmengen durch MV | Schnell auch für größere Daten |
| Aktualität | Immer aktuell | Letzter Refresh | Letzter Refresh oder kontinuierlich |
| Aktualisierungsstrategie | / | Full | Full oder inkrementell |
Vielleicht können Sie nun besser einschätzen, welches der beiden Tools zu Ihrem Szenario passt. Falls Sie noch unsicher sind, zeigen wir im Folgenden, welche Lösung sich für welchen Anwendungsfall empfiehlt.
Geeignete Anwendungsfälle nach Lösung:
Lakehouse Federation eignet sich für:
- Proof of Concepts und schnelle Pilotprojekte
- Ad-hoc-Abfragen ohne Pipeline-Aufwand
- Migration von Systemen (z.B. DWH): Zur Prüfung/Reconciliation, ob alles richtig übernommen wird
- Szenarien mit kleinen Datenmengen und unkritischen Quellsystemen
Lakehouse Federation + Materialized Views können Sie verwenden, um:
- Szenarien mit kleinen bis mittleren Datenmengen,
- und kleinere Projekte, bei denen die Quellsysteme kritisch sind, umzusetzen
Lakeflow Connect hingegen eignet sich vor allem für:
- mittlere bis große Datenmengen
- und alle Szenarien die Quellsystemdatenbanken stören könnten (z.B. hinsichtlich Performance), wie
- Dashboards mit vielen Nutzern
- Self-Service-Analytics und Data Science
- Machine-Learning-Anwendungen auf konsistenten Daten
- Change Data Capture-Szenarien (CDC)
Hinweis: Die Nutzung von CDC bedeutet Mehrkosten. So werden bspw. die anfallenden Compute-/Durchführungszeiten pro Vorgang in Rechnung gestellt. Weiterhin können weitere Kosten anfallen. Dazu zählen: Kosten für Orchestrierung, weitere Trigger oder potenzielle Netzwerkkosten.
Ihr Team kennt die Konzepte aber nicht den produktiven Alltag auf der Plattform?
Verstehen ist der erste Schritt – Anwenden der zweite.
Fazit – Was ist besser?
Grundsätzlich gibt es für jedes Szenario eine bevorzugte Anwendung. Über die unterstützten Datenquellen der verschiedenen Lösungen wird bereits eine Vorauswahl getroffen. Nicht alle Wege sind mit allen Datenquellen nutzbar.
Lakehouse Federation ist zwar für kleinere Proof of Concepts geeignet. Durch die direkte Nutzung der Quellsystemdatenbank können allerdings Kosten in die Höhe schießen. Und noch viel wichtiger: Die Performance kann stark durch viele Anfragen und Nutzer leiden.
Lakehouse Federation + Materialized Views eignen sich für kleinere und mittlere Projekte. Sie bilden eine Art Zwischenlösung hin zum Lakeflow Connect, indem sie die Quelldatenbanken nicht wie Federation live nutzen, aber auf die hohe Komplexität bei der Umsetzung/Einrichtung von Lakeflow Connect verzichten.
Lakeflow Connect bringt den „vermeintlichen Königsweg“. Es ist zukunftsfähig und eignet sich für Machine Learning und weitere Anwendungen mit großen Anforderungen an bspw. die Compute-Performance und die Skalierbarkeit.
Allerdings ist Lakeflow Connect auch sehr komplex (und damit aufwendig) in den Details der Umsetzung. Man kann z.B. viel Zeit aufwenden, um ein gutes Gleichgewicht für die Beladung der Daten – je nach eigenen Anforderungen – zu finden. Hier stehen sich vor allem zwei Ziele gegenüber. Aktualität der Daten auf der einen und eine möglichst geringe Belastung der Quelldatenbank auf der anderen Seite.
Zusammenfassend lässt sich sagen, dass Lakehouse Federation und Lakeflow Connect keine wirklichen Gegensätze, sondern ergänzende Ansätze sind. Lakehouse Federation bringt Geschwindigkeit und Live-Daten, Lakeflow Connect liefert Skalierung, Governance und Zukunftssicherheit.
Der einzelne Anwendungsfall ist also entscheidend! Kontaktieren Sie uns bei Fragen oder zur Unterstützung bei der Umsetzung!

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte
FAQ – Die wichtigsten Fragen schnell beantwortet
Lakehouse Federation ermöglicht es, Daten aus externen Quellen direkt in Databricks abzufragen – ohne sie zu kopieren. Im Unity Catalog wird nur ein Metadateneintrag gespeichert, der per JDBC auf die Quelldatenbank verweist.
Die Abfrage wird also auf dem Quellsystem ausgeführt, nicht auf Databricks.
Vorteil: Sehr schnelle Anbindung, ideal für Pilotprojekte und Ad-hoc-Abfragen.
Nachteil: Belastung des Quellsystems und potenziell geringere Performance bei großen Datenmengen.
Aktuell werden u. a. folgende Systeme unterstützt:
Microsoft SQL Server, Databricks, MySQL, PostgreSQL, Teradata, Oracle, Amazon Redshift, Salesforce Data Cloud, Snowflake, Azure Synapse, Google BigQuery
Lakeflow Connect ist eine Ingestion-Lösung, die Daten aktiv aus den Quellsystemen ins Lakehouse lädt. Über Pipelines werden Daten inkrementell oder vollständig abgerufen, im Cloud Storage gespeichert und im Unity Catalog registriert.
Abfragen laufen danach vollständig in Databricks.
Vorteil: Hohe Performance, stabile Dashboards, Entlastung der Quellsysteme.
Nachteil: Etwas höherer Aufwand und zusätzliche Speicherkosten.
Lakeflow Connect bietet Connectoren u. a. für:
SQL Server, Google Analytics, Salesforce, Workday, ServiceNow, SharePoint