In Zeiten datengetriebener Entscheidungen sind personenbezogene Informationen (PII – Personally Identifiable Information) ein zentraler Bestandteil vieler Unternehmensprozesse. Gleichzeitig stellen sie ein erhebliches Risiko dar: Datenschutzverstöße führen nicht nur zu hohen Bußgeldern, sondern auch zu Reputationsverlust und Vertrauensverlust bei Kunden.
Der verantwortungsvolle Umgang mit dieser Art von Daten ist daher ein zentraler Bestandteil jeder modernen Datenstrategie und jedes Data-Governance-Konzepts. Im Folgenden stellen wir Ihnen 9 Best Practices vor, mit denen Unternehmen personenbezogene Daten effektiv schützen und gleichzeitig ihre Datennutzung optimieren können.
1. Vermeiden Sie personenbezogene Informationen, wo es möglich ist
Es ist immer besser, keine personenbezogenen Informationen zu verwenden. Begrenzen Sie den Zugang möglichst dahingehend, dass diese Daten für die Anwender nicht erreichbar sind.
In vielen Analysen sind personenbezogene Informationen sogar unnötig oder zu granular. Ein Beispiel: Das exakte Geburtsdatum einer Person (z. B. 01.01.1970) ist selten relevant.
Gruppieren Sie stattdessen in Altersklassen (z. B. 20–25, 55–60 Jahre). So erhöhen Sie den Datenschutz und verbessern gleichzeitig die Aussagekraft Ihrer Analysen.
2. Anonymisierung schlägt Pseudonymisierung. Pseudonymisierung schlägt Klartext
Es gibt einen klaren Entscheidungsprozess im Umgang mit personenbezogenen Informationen:
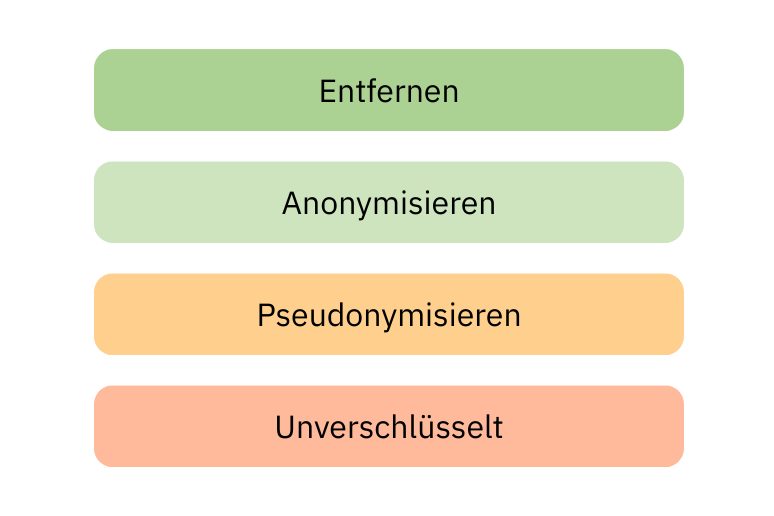
Entfernen
Wenn wir den Wert, den personenbezogenen Informationen zu nachgelagerten Anwendungsfällen beitragen kann, nicht klar erkennen, sollten wir sie einfach entfernen. Dies ist der sichere Weg, damit es nicht zu Verstößen oder Datenmissbrauch kommt.
Anonymisieren
Wenn wir den potenziellen Wert der personenbezogenen Daten klar verstehen und in einem Anwendungsfall nutzen möchten, sollte der nächste Schritt die Anonymisierung dieser Informationen sein.
Pseudonymisieren
Nur wenn die Anonymisierung der Daten den Nutzungswert zunichtemacht, sollten sie immer pseudonymisiert werden. Die Pseudonymisierung bietet zwar auch einen gewissen Schutz. Da diese Methoden aber „umkehrbar“ sind, zählen sie aus Sicht des Datenschutzes weiterhin als personenbezogene Informationen. Auch wenn diese besser geschützt sind.
Sie wollen mehr dazu erfahren, wie man Daten in Databricks richtig schützt? Dann haben wir hier den richtigen Artikel für Sie vorbereitet: Databricks Unity Catalog
Unverschlüsselt
Das Behalten von personenbezogenen Informationen im Klartext sollte die letzte Option sein, die in der Praxis nur sehr selten vorkommt. In solchen Fällen werden die Daten beim Eintritt pseudonymisiert, aber die Zuordnung zwischen pseudonymem Identifikator und den personenbezogenen Informationen nur in einer isolierten Umgebung vorbehalten. Der Zugriff auf diese isolierte Umgebung muss streng reguliert sein.
Umgebung vorbehalten. Der Zugriff auf diese isolierte Umgebung muss streng reguliert sein.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
3. Überprüfen Sie Schutzmaßnahmen regelmäßig und kritisch
Datenschutz ist kein statisches Konzept. Technologien, Angriffsvektoren und gesetzliche Anforderungen ändern sich fortlaufend.
Früher galt beispielsweise das regelmäßige Ändern von Passwörtern als sicherheitsrelevant. Heute empfehlen Experten, stattdessen Passkeys und Zwei-Faktor-Authentifizierung zu verwenden (siehe Bundesamt für Sicherheit in der Informationstechnik – BSI)
Dieses sehr einfache Beispiel zeigt, wie sich Schutzmaßnahmen im Laufe der Zeit ändern können. Bleiben Sie stets auf dem Laufenden!
4. Anwenden der „3-Fakten-Regel“
Die sogenannte 3-Fakten-Regel (Three-Fact Rule) besagt:
Wenn drei verschiedene Merkmale einer Person bekannt sind – z. B. Postleitzahl, Geburtsdatum und Geschlecht – ist eine eindeutige Identifizierung meist möglich.
Konsequenz:
Selbst unscheinbare Datenkombinationen können Rückschlüsse auf Individuen ermöglichen. Prüfen Sie daher bei jedem Datensatz:
- Wie viele Merkmale liegen vor?
- Könnten sie gemeinsam eine Re-Identifizierung ermöglichen?
5. Kombinationen von Datensätzen stets mitdenken
Auch wenn einzelne Datensätze anonym erscheinen, können sie in Kombination mit anderen Informationen personenbezogene Daten offenlegen.
Beispiel: Ein anonymisierter Kundendatensatz kann durch Verknüpfung mit einem externen Datensatz (z. B. Standortdaten oder CRM-System) Rückschlüsse auf den Kunden zulassen. Die Anonymisierung wird faktisch ausgehebelt.
6. Schulen Sie Mitarbeitende im Umgang mit sensiblen Daten
Technische Maßnahmen reichen allein nicht aus – Menschen sind der wichtigste Faktor im Datenschutz.
Führen Sie jährliche Datenschutzschulungen für alle Mitarbeitenden durch. Für Teams, die direkt mit personenbezogenen Informationen arbeiten, sollten weiterführende Trainings oder Zertifizierungen (z. B. nach ISO/IEC 27001) verpflichtend sein.
7. Nicht alle personenbezogenen Daten sind gleich sensibel
Einige Daten – wie ethnische Herkunft, religiöse Überzeugung oder genetische Informationen – sind besonders schützenswert und fallen unter Artikel 9 der Datenschutz-Grundverordnung (GDPR).
Generell empfiehlt sich eine Einstufung zur Bewertung dieser Daten. Hier ein Beispiel:
- Hochsensibel: Gesundheitsdaten, politische Meinung, biometrische Daten
- Mittel: Kontaktdaten, Gehaltsinformationen
- Gering: Aggregierte Nutzungsdaten ohne Personenbezug
8. Führen Sie regelmäßige Privacy Impact Assessments (PIA) durch
Ein Privacy Impact Assessment (PIA) hilft, Datenschutzrisiken systematisch zu identifizieren, zu bewerten und zu minimieren.
Idealerweise führen Sie ein PIA proaktiv vor der Einführung neuer Systeme, Services oder Datenprozesse durch.
Dies sind die Fünf Schritte eines effektiven PIA-Reviews:
- Beschreibung des Systems oder Service
- Identifikation der erhobenen personenbezogenen Daten (Quelle, Zweck, Verarbeitung)
- Prüfung auf Einhaltung gesetzlicher Vorgaben
- Bewertung der Datenschutzrisiken und deren Schweregrad
- Entwicklung eines Aktionsplans zur Risikominimierung
Wichtig: Ein PIA ist kein einmaliges Ereignis, sondern ein fortlaufender Prozess, da sich Systeme und Anforderungen ständig verändern.
Databricks Beratung mit Datasolut
Wir sind offizieller Databricks Champion mit dem deutschlandweit einzigem MVP.
9. Isolieren Sie stets Umgebungen, die PII verarbeiten.
Sobald personenbezogene Informationen in produktiven Umgebungen kursieren, lässt sich ihr Missbrauch kaum mehr verhindern.
Folgende Punkte sollten stets beachtet werden:
- Trennen Sie produktive von Test- und Analyseumgebungen.
- Beschränken Sie Zugriffsrechte konsequent nach dem Need-to-Know-Prinzip.
- Implementieren Sie Logging- und Monitoring-Prozesse, um jede Nutzung sensibler Daten nachvollziehbar zu machen.
So stellen Sie sicher, dass personenbezogene Daten nur dort genutzt werden können, wo es unbedingt erforderlich ist.
Fazit
Der Schutz personenbezogener Informationen ist für viele Unternehmen nicht gerade ein prestigeträchtiges und oftmals sogar nervenzehrendes Unterfangen. Es ist allerdings ein fundamental wichtiges Thema, welches zurecht gesetzlich in DSGVO & Co. verankert ist.
Die 9 Best Practices aus diesem Artikel sollten Ihnen in Kurzform aufzeigen, welche Dinge Sie besonders beachten müssen beim Umgang mit personenbezogenen Informationen. Sollten Sie Fragen haben oder sich Unterstützung bei der Umsetzung wünschen, kontaktieren Sie uns gerne für ein unverbindliches Gespräch.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte