


RFP Prozessautomatisierung mit GenAI in der Elektronikfertigung
Auf einen Blick:
- Branche: Elektronik
- Projektziel: Automatische Klassifizierung und Sortierung technischer Kundendokumente mittels GenAI
- Tools: Llama4, Python
Die Herausforderung des Kunden
Zum Projektstart lief die Dokumentensortierung bei einem mittelständischen Elektronikfertiger vollständig manuell ab, sodass Mitarbeitende jede angelieferte Datei einzeln öffnen und prüfen mussten. Anschließend ordneten sie die Dokumente einer Klasse zu und verschoben sie in die passenden Unterordner, wodurch viel Zeit gebunden wurde.
Mit steigender Projektanzahl nahm die Menge technischer Kundendokumente weiter zu, weshalb der Aufwand ebenfalls wuchs. Dadurch wurde der Prozess nicht nur zeitintensiv, sondern auch anfällig für Fehler, während qualifizierte Fachkräfte zunehmend einfache Routinetätigkeiten übernehmen mussten.
Gleichzeitig suchte das Unternehmen eine Lösung, die schneller arbeitet und verschiedene Dateiformate zuverlässig erkennt, damit der Projektstart effizienter wird. Zudem sollte die Lösung On Premise laufen, sensible Daten schützen und flexibel an neue Dokumentenklassen angepasst werden können, sodass sie langfristig nutzbar bleibt.
Vor diesen Herausforderungen stand unser Kunde
Hoher manueller Aufwand
Mitarbeitende mussten alle angelieferten Dokumente manuell prüfen, klassifizieren und in passende Ordner verschieben. Ein zeitintensiver und repetitiver Prozess.
Uneinheitliche Dokumentenstruktur
Es gibt unterschiedliche Dateiformate und uneinheitliche Benennungen, auch nach der Zuordnung. Eine Standardisierung kann auch weitere Prozesse beschleunigen.
Fehlende Skalierbarkeit
Mit der steigenden Anzahl von Projekten und Dokumenten wächst der Aufwand proportional. Ohne Automatisierung wäre eine zukunftsfähige Skalierung daher nicht möglich.
Wie gehen wir dabei vor?
1.
Zunächst wurde ein Klassifikationsmodell auf Basis von Llama 4 und DSPy aufgebaut und getestet. Ziel war es, unterschiedliche Dokumenttypen zuverlässig den definierten Klassen zuzuordnen.
2.
Anschließend wurde Apache Tika integriert, um Inhalte aus verschiedenen Dateiformaten zu extrahieren und dem Modell bereitzustellen. Zusätzlich flossen Dateipfade, Referenzdateien und eine zentrale YAML Konfiguration in die Entscheidungslogik ein.
3.
Zum Abschluss wurde ein Python Backend entwickelt, das ZIP Dateien entgegennimmt, automatisch verarbeitet und vorsortiert zurückgibt. Die gesamte Lösung wurde containerisiert mit Podman betrieben und läuft vollständig On Premise mit dedizierter GPU Kapazität.
Unsere Lösung
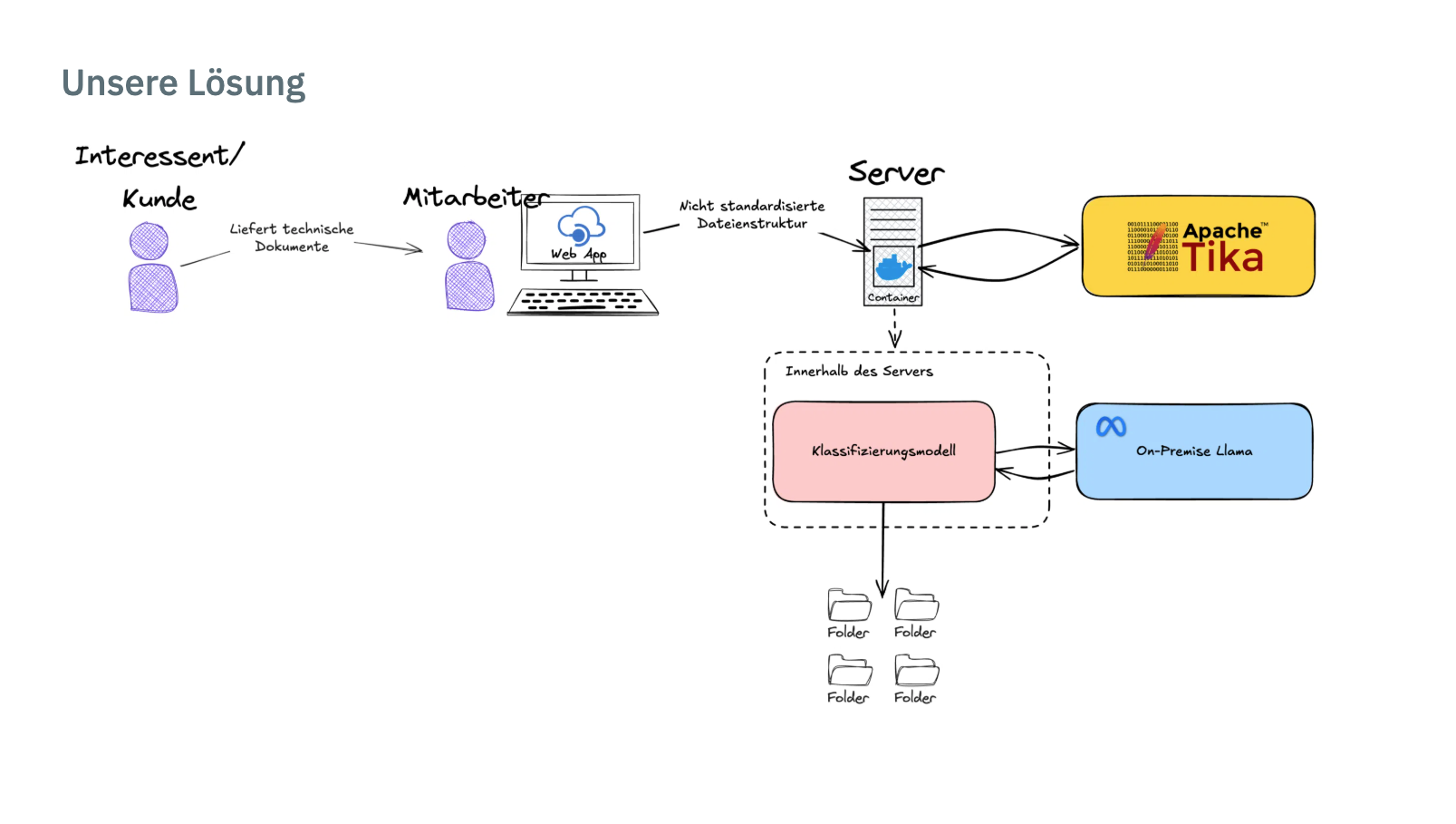
Die Architektur zeigt einen On-Premise Datenfluss zur automatisierten Klassifizierung technischer Dokumente. Eingehende Dokumente werden über eine Web App entgegengenommen, in einem Docker-Container verarbeitet und mit Apache Tika extrahiert. Das Klassifizierungsmodell arbeitet dabei vollständig server-intern zusammen mit einem lokal gehosteten Llama-Modell und legt die Ergebnisse strukturiert in kategorisierten Ordnern ab.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte