


Large Language Models (zu dt. Große Sprachmodelle) arbeiten auf Basis von Deep Learning Modellen mit menschlicher Sprache. Das Ziel des Large Language Models (LLM) ist es, einen Text auf menschenähnliche Weise zu erzeugen und zu verstehen.
In diesem Beitrag geben wir Ihnen einen Überblick über Themen wie,
- Was ist ein Large Language Model?
- Wie funktionieren LLMs?
- Was sind Beispiele für LLMs?
Lassen Sie uns einsteigen!
Large Language Model einfach erklärt
Large Language Models (LLMs) sind große Sprachmodelle, welche auf Basis von neuronalen Netzen auf massiven Datenmengen trainiert wurden, um natürliche Sprache in bisher unvergleichbarer Qualität zu verstehen und zu generieren.
Es verwendet Deep-Learning-Techniken und große Datensätze, um
- neue Inhalte zu verstehen,
- zusammenzufassen,
- zu generieren
- und vorherzusagen.
Die großen Sprachmodelle fallen in die Kategorie der generativen KI und werden insbesondere zur Generierung textbasierter Inhalte verwendet. Ein aktuelles Beispiel für ein solches Modell ist ChatGPT. Dazu später mehr.

KI-basierte Sprachmodelle wurden schon 1966 vom MIT vorgestellt in Form eines Chatbots mit dem Namen ELIZA. Allerdings gibt es hier eine wichtige Abgrenzung: Language Model vs. Large Language Model.
Ein Sprachmodell (Language Model) kann von unterschiedlicher Komplexität sein: von einfachen Modellen bis hin zu komplexeren neuronalen Netzwerken. Alle Sprachmodelle müssen wir zunächst anhand eines Datensatzes trainieren. Schließlich nutzen wir verschiedene Techniken, um Beziehungen abzuleiten und auf der Grundlage der trainierten Daten neue Inhalte zu generieren.
Der Begriff Large Language Modell bezieht sich jedoch in der Regel auf Modelle, die Deep-Learning-Techniken verwenden und eine große Anzahl von Parametern haben, die von Millionen bis zu Milliarden reichen können.
Large: LLMs beinhalten eine riesige Menge an Parametern. In OpenAIs GPT-3 sind dies beispielsweise 175 Milliarden. Um diese Modelle optimal zu trainieren, benötigt man deshalb auch massive Datenmengen, im Fall von GPT-3 waren dies 560 Gigabyte an Textdaten.
Language: LLMs werden nicht auf irgendwelchen Daten trainiert, sondern auf Textdaten in natürlicher Sprache. In einem mehrstufigen Trainingsverfahren wird unter Anwendung von Transformermodellen komplexe Zusammenhänge zwischen Wörtern und Sätzen vom Modell gelernt.
Model: LLMs besitzen damit die Fähigkeit sprachliche Informationen zu verallgemeinern und sind Foundation-Modelle. Durch die riesige Menge an Textdaten und die daran trainierten Parametern sind sie vielseitig für eine Reihe von verschiedenen Aufgaben und Fragestellen nutzbar.
Mit einer großen Anzahl von Parametern, basierend auf einem Transformermodell sind LLMs in der Lage, schnell zu verstehen und passende Antworten zu generieren, wodurch die KI-Technologie in vielen verschiedenen Bereichen einsetzbar ist (z.B. als Chatbot). Wie das funktioniert? Das klären wir im nächsten Abschnitt.
Wie funktionierten Large Language Models?
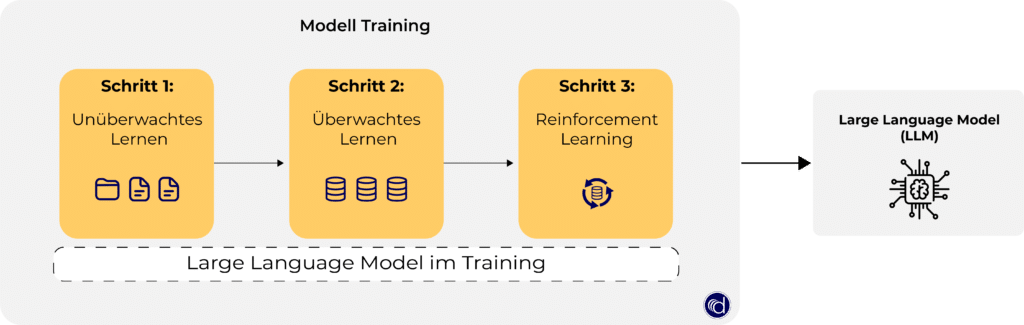
Entwickler trainieren große Sprachmodelle auf einem großen Datenvolumen (in der Regel Petabytes groß). Das Training selbst erfolgt in mehreren Schritten und beginnt meist mit dem Ansatz des unsupervised Learnings als Pre-Training.
Schritt 1: Unüberwachtes Lernen
In dem Ansatz des unüberwachten Lernens (unsupervised Learning) trainiert man ein Modell mit unstrukturierten Daten. Durch das Training mit unstrukturierten Daten stehen dem Sprachmodell größere Datensätze zur Verfügung. In diesem Schritt beginnt das LLM Beziehungen zwischen einzelnen Wörtern und Konzepten herzustellen.
Schritt 2: Überwachtes Lernen
Als nächstes folgt das Training mit Prompts und Fine-tuning mit einer Form des selbstüberwachten Lernens (self-supervised Learning). Die zuvor antrainierten, unstrukturierten Daten werden bereinigt und in eine einheitliche, für das Modell lesbare Form gebracht. Das LLM wird nun mit strukturierten Daten trainiert, damit dieses in der Lage ist, verschiedene Konzepte genauer zu identifizieren.
Schritt 3: Reinforcement Learning
Bei verschiedenen Modell-Tests werden die Datensätze identifiziert, die fehlerhaft sind. Damit das Modell später fehlerfreie Antworten generiert, werden Trainingsdatensätze eingepflegt (reinforcement Learning).
Schließlich durchläuft das Modell den Prozess des transformer neural network (basierend auf dem Deep Learning Konzept). Die Transformer-Architektur ermöglicht es dem LLM, die Beziehungen und Verbindungen zwischen Wörtern und Konzepten zu verstehen und zu erkennen, indem es einen Mechanismus der self-attention einsetzt. Dieser Mechanismus ist in der Lage, einem bestimmten Element (Token genannt) eine Punktzahl zuzuweisen, um die Wahrscheinlichkeit einer Beziehung zu bestimmen.
In der folgenden Grafik sind die einzelnen Prozessschritte nochmals abgebildet.
Sobald das Large Language Modell trainiert ist, können wir es für verschiedene Zwecke einsetzen (z.B. Texterstellung, Übersetzung, Inhaltszusammenfassung, Chatbots).
Auch an dieser Stelle haben wir uns mit ChatGPT unterhalten. Befragt man es nach dem eigenen Trainingsprozess, so antwortet es wie folgt:
| Prozessschritt | Erklärung |
| Datensammlung | Große Mengen an Daten wurden gesammelt, um das Modell zu trainieren |
| Datenbereinigung | Gesammelten Daten wurden bereinigt, um unnötige Informationen zu entfernen |
| Datenkodierung | Bereinigten Daten werden in verständliche Form gebracht |
| Modelltraining | Modell wurde mit kodierten Daten trainiert, um Muster und Zusammenhänge zu erkennen |
| Modellvalidierung | Trainiertes Modell wurde auf separaten Testdatensatz validiert |
| Modellverbesserung | Auf Basis der Validierungsergebnisse wurden Anpassungen am Modell vorgenommen |
| Bereitstellung | ChatGPT wurde in produktionsfähige Umgebung implementiert |
Was sind die verschiedenen Typen von LLMs?
Es gibt eine Reihe von Begriffen zur Beschreibung der verschiedenen Arten großer Sprachmodelle, die sich ständig weiterentwickeln. Zu den gebräuchlichen Typen gehören die folgenden:
| Large Language Model Typ | Beschreibung |
| Zero-shot Modell | Ein großes, verallgemeinertes Modell, das auf einem generischen Datenkorpus trainiert wurde und in der Lage ist, für allgemeine Anwendungsfälle ein ziemlich genaues Ergebnis zu liefern, ohne dass ein zusätzliches Training erforderlich ist (z.B. ChatGPT (GPT-3)). |
| Fine-tuned oder domain-specific Modell | Ist ein Zero-shot Modell, welches zusätzlich trainiert wurde. Ein Beispiel ist OpenAI Codex, ein domänenspezifisches LLM für die Programmierung auf der Grundlage von GPT-3. |
| Multimodales Modell | Ursprünglich wurden LLMs nur auf Text abgestimmt, aber mit dem multimodalen Ansatz ist es möglich, sowohl Text als auch Bilder zu verarbeiten (GPT-4). |
Was sind Beispiele und Einsatzmöglichkeiten für Large Language Models?
Wir können LLMs für eine Vielzahl von Aufgaben verwenden, wie z. B.
- Stimmungsanalyse,
- Beantwortung von Fragen,
- Erstellung von Code,
- automatische Zusammenfassungen,
- maschinelle Übersetzung,
- Dokumentenklassifizierung,
- Texterstellung
- und vieles mehr.

Wir können LLMs zum Beispiel auf Kundenrezensionen trainieren, um die Stimmung in Rezensionen zu erkennen oder Fragen zu angebotenen Produkten oder Dienstleistungen auf der Grundlage des Kundenfeedbacks zu beantworten. Bekannte Beispiele für Large Language Models sind ChatGPT, Dolly und Google Bard.
ChatGPT
ChatGPT ist ein Tool zur Verarbeitung natürlicher Sprache, das auf KI-Technologie basiert. Die Entwickler trainierten es auf einer großen Menge an Textdaten und verwendeten Machine Learning Techniken, damit es natürliche Sprache versteht und zu generiert. Bei einer Anfrage analysiert GPT den Text dieser, um die korrekte Bedeutung zu verstehen. Die Antwort basiert auf den Daten, mit denen ChatGPT im Trainingsprozess gelernt hat.
Das Sprachmodell kann Fragen beantworten und Sie bei Aufgaben wie dem Verfassen von E-Mails, Aufsätzen und Code unterstützen.
In diesem YouTube Video erklären wir Ihnen, wie Sie einen Chatbot mit der Hilfe von ChatGPT und LangChain programmieren (RAG).
Dolly von Databricks
Auch Dolly ist ein Tool zur Verarbeitung natürlicher Sprache. Benannt nach dem ersten geklonten Säugetier der Welt, einem Schaf, weist Dolly wesentliche Unterschiede zu ChatGPT auf: Der Code von Dolly ist frei verfügbar, wurde jedoch auf einem viel kleineren Sprachmodell mit nur sechs Milliarden Parametern trainiert (im Gegensatz zu 175 Milliarden für GPT-3).
Es basiert auf der Transformer-Architektur und wurde mit einer großen Menge an Textdaten trainiert, um natürliche Sprache zu verstehen und zu generieren. Dolly ist in der Lage, menschenähnliche Gespräche zu führen, Fragen zu beantworten, Texte zu generieren und vieles mehr.
Dolly wurde speziell für die Verwendung in Unternehmen entwickelt und kann in verschiedenen Anwendungen wie Chatbots, Spracherkennung und Textgenerierung eingesetzt werden.
Google Bard
Google BARD (Big-Ass-Robot-Dialog) ist ein von Google entwickeltes Large Language Model. Bard stellt eine Erweiterung zur herkömmlichen Google Suche dar. In einem Suchfeld kann man seine Fragen oder Aufträge formulieren. So kann man Bard beispielsweise bitten, ein Gedicht, einen Songtext oder einen Essay zu schreiben. Der Chatbot antwortet und nennt zusätzlich Quellenangaben. Im Gegensatz zu ChatGPT generiert Bard auch mehrere Vorschläge, so genannte „Entwürfe“, aus denen man auswählen kann.
Hier finden Sie weitere Fallbeispiele zum Einsatz von Large Language Models.
Um Large Language Models auf spezifische Anwendungsbereiche anzupassen und die Ergebnisse zu personalisieren, wird der Prozess des LLMOps empfohlen. Sehen wir uns nun die Vorteile von LLMs an.
Was sind Vorteile von Large Language Models?
Es gibt zahlreiche Vorteile, die Large Language Models für Organisationen und Nutzer bieten:
| Vorteil | Detail |
| Vielseitigkeit | LLMs können viele Aufgaben übernehmen, wie spezielle Texte produzieren, Gedichte schreiben, Texte zusammenfassen, Sprachen übersetzen, Mathematikaufgaben lösen, Codelösungen schreiben, uvm.. |
| Adaptivität | Die Funktionalitäten von LLMs können sehr einfach durch das Bereitstellen eigener Daten verbessert werden. Dafür reichen bereits wenige Beispiele, um das LLMs für eigene Bedürfnisse zu optimieren. |
| Sprachliche Korrekturen und Verbesserungen | LLMs können Texte analysieren und sprachliche Fehler oder stilistische Verbesserungen vorschlagen. Dies ist besonders hilfreich beim Verfassen von Texten oder beim Erlernen einer neuen Sprache. |
| Kontextuelles Verständnis | LLMs haben die Fähigkeit, den Kontext von Fragen und Texten zu verstehen, was ihnen ermöglicht, präzise und relevante Antworten zu geben. Sie können den Zusammenhang von Sätzen oder Absätzen erfassen und daraus Schlüsse ziehen. |
Neben den Vorteilen verbergen sich auch Herausforderungen bei den Large Language Modellen.
Was sind die Herausforderungen von Large Language Models?
Die Verwendung von LLMs bietet zwar viele Vorteile, doch gibt es auch einige Herausforderungen und Einschränkungen. Die größten Herausforderungen stellen wir Ihnen in der folgenden Tabelle vor:
| Herausforderung | Detail |
| Entwicklungskosten | Die riesigen Datensätze und Grafikprozessor-Hardware die LLMs benötigen sind teilweise sehr kostspielig. |
| Umwelt | LLMs können aufgrund ihrer Größe und ihres Rechenbedarfs negative Auswirkungen auf die Umwelt haben. Die Serverfarmen, die für das Training der Modelle benötigt werden, verbrauchen eine beträchtliche Menge an Strom, was zu einem erhöhten Kohlendioxidausstoß führt. |
| Verzerrung | Unstrukturierte Daten bergen die Gefahr von verzerrten Antworten. |
| Erklärbarkeit (Bias) | Es ist nicht immer nachvollziehbar, wie das LLM zu einem bestimmten Ergebnis kommt. |
| Komplexität | Die Fehlerbehebung der LLMs ist komplex, da das Model auf Milliarden von Parametern beruht. |
Technische Möglichkeiten zur Verwendung von Large Language Models
Large Language Models bieten also eine große Palette an nützlichen Features, um neuartige Software zu entwickeln. Die direkte Verwendung von GPT über OpenAIs Chat-GPT ist natürlich direkt und einfach, allerdings kein sinnvoller Weg, um die neuartigen Möglichkeiten von Large Language Models in eigenen Projekten einzubeziehen. Wenn ein Entwicklerteam also Large Language Models in eigener Software verwenden will, muss es auf andere Weise auf diese zugreifen. Dafür gibt es im Allgemeinen zwei Möglichkeiten.
Cloud-basierte APIs
In der modernen Softwareentwicklung bieten Cloud-basierte APIs eine leistungsfähige und flexible Möglichkeit, LLMs direkt in eigene Anwendungen zu integrieren, ohne dass ein Entwicklerteam eigene Modelle trainieren oder spezielle Infrastruktur dafür aufbauen müsste. Viele der führende Technologieunternehmen bieten Large Language Models bereits als Services an, was Entwicklern die Arbeit erheblich erleichtert.
Mit Cloud-basierten APIs erfolgt die Nutzung von LLMs denkbar einfach: Entwickler senden Anfragen, sogenannte Prompts, an die API, und das Modell generiert daraufhin eine Antwort. Diese Prompts können selbstverständlich von einfacher oder auch komplexerer Natur sein, je nachdem für welche Aufgabe das LLM innerhalb der Software verwendet werden soll. Ausgehend davon können auch viele verschiedene API-Calls miteinander verknüpft und verbunden werden, um eine umfassende Applikation zu entwickeln.
Dabei kümmert sich der Cloud-Anbieter um alle technischen Aspekte im Hintergrund, wie die Bereitstellung der Rechenleistung und das Hosting der Modelle. Dies ermöglicht es, auch komplexe und rechenintensive Sprachmodelle zu verwenden, ohne über eigene Server und Hardware nachzudenken.
Vorteile
Einer der größten Vorteile dieser Lösung ist ihre Einfachheit. Entwickler müssen sich nicht um das Training oder Hosting von Modellen kümmern, was die Einstiegshürden für die Nutzung von LLMs deutlich senkt. Die gesamte Infrastruktur wird vom API-Anbieter bereitgestellt.
Ein weiterer Vorteil ist die Skalierbarkeit. Da die LLMs in der Cloud laufen, kann bei Bedarf automatisch skaliert werden. Egal, ob nur eine geringe oder eine massive Anzahl von Anfragen verarbeiten werden müssen – der Cloud-Anbieter stellt die erforderliche Rechenleistung bereit.
Zudem bieten Cloud-Anbieter stets aktuelle und hochleistungsfähige Modelle an. Diese werden regelmäßig aktualisiert, sodass Entwickler Zugang zu den neuesten Fortschritten in der KI-Technologie haben, ohne die Modelle selbst überwachen oder aktualisieren zu müssen. Dies ist ein entscheidender Vorteil, da die Entwicklung im Bereich der Sprachmodelle rasant voranschreitet und der Zugriff auf die neuesten Modelle die Qualität der Ergebnisse erheblich verbessern kann.
Nachteile
Trotz der Vorteile gibt es auch einige Herausforderungen bei der Nutzung von Cloud-basierten LLM-APIs. Einer der größten Nachteile sind die Kosten, die vor allem bei hohen Nutzungsvolumina schnell steigen können. Während die Nutzung kleinerer Anfragen noch relativ erschwinglich bleibt, kann die Abhängigkeit von externen APIs bei großem Datenverkehr teuer werden.
Ein weiterer wichtiger Aspekt ist der Datenschutz. Da die Anfragen an externe Server gesendet werden, besteht immer das Risiko, dass sensible Daten in der Cloud verarbeitet werden. Für Anwendungen, die mit vertraulichen Informationen arbeiten, kann dies problematisch sein. Entwickler müssen in solchen Fällen sicherstellen, dass die API-Anbieter ausreichende Sicherheitsmaßnahmen und Datenschutzgarantien bieten.
Anbieter von Cloud-APIs
Es gibt mittlerweile zahlreiche Anbieter, die Cloud-basierte LLMs über APIs bereitstellen. Zu den bekanntesten gehören natürlich die großen Tech-Riesen, welche LLMs bereits in ihren Cloud-Services verankert haben.
- OpenAI GPT: OpenAI bietet über seine API direkten Zugriff auf die GPT-Modelle, die für Textgenerierung, Textverständnis und viele andere Anwendungen eingesetzt werden können.
- Google Cloud Vertex AI: Google bietet über seine Cloud-Plattform leistungsfähige LLM-Modelle, die sich nahtlos in bestehende Google-Dienste integrieren lassen.
- AWS Bedrock: Amazon ermöglicht über Bedrock den Zugriff auf eigene LLMs sowie auf Modelle von Drittanbietern, was eine flexible Auswahl an Lösungen bietet.
- Microsoft Azure OpenAI Service: Microsoft bietet ebenfalls die Möglichkeit, OpenAIs GPT-Modelle über die Azure-Cloud zu nutzen, und kombiniert dies mit den umfangreichen Diensten der Azure-Plattform.
- Databricks DBRX und Mosaic AI: Auch Databricks bietet einen Zugriff zu LLMs, unter anderen mit dem hauseigenen LLM DBRX. Darüber hinaus bietet Databricks mit Mosaic AI eine Plattform, um innerhalb des Databricks Ökosystems die Anpassung von LLMs zu vereinfachen.
Open-Source-Modelle auf eigener Infrastruktur
Eine Alternative zu Cloud-APIs bietet die Verwendung von Open-Source-Modellen auf eigener Infrastruktur. Open-Source-LLMs sind öffentlich zugängliche Modelle, die direkt verwendet werden können und im Gegensatz zu Cloud-basierten API-Lösungen stets die vollständige Kontrolle über das Modell, seine Anpassung und die Umgebung bereitstellen. Dies eröffnet viele Möglichkeiten, erfordert jedoch auch das entsprechende technische Fachwissen und geeignete Hardware.
Open-Source-LLMs können entweder direkt auf eigene Hardware oder aber in einer privaten Cloud-Infrastruktur (z.B. auf einer firmeneigenen AWS-, Azure- oder GCP-Infrastruktur) betrieben werden.
Vorteile
- Datenschutz: Einer der größten Vorteile bei der Verwendung von Open-Source-Modellen auf eigener Infrastruktur ist der Datenschutz. Da alle Daten auf eigenen Servern verarbeitet werden, ist die volle Kontrolle über sensible Informationen gewährleistet. Dies ist besonders wichtig für Unternehmen, die mit streng vertraulichen Daten arbeiten und keine externen Cloud-Dienste verwenden wollen.
- Flexibilität: Mit Open-Source-Modellen besteht die Möglichkeit, das Modell nach eigenen Wünschen anzupassen. Diese Flexibilität bietet einen enormen Vorteil gegenüber geschlossenen, Cloud-basierten Modellen, die in der Regel nicht modifiziert werden können.
- Kostenkontrolle: Während Cloud-basierte Lösungen oft laufende API-Kosten verursachen, können bei der Verwendung von Open-Source-Modellen langfristig Kosten gespart werden. Zwar fallen anfangs Kosten für die Anschaffung der notwendigen Hardware (insbesondere GPUs) an, aber danach besteht volle Kontrolle über die Kostenstruktur.
Nachteile
- Komplexität: Der Betrieb von LLMs auf eigener Hardware oder Infrastruktur erfordert technisches Fachwissen, um die Modelle zu installieren, zu konfigurieren und zu betreiben. Zudem müssen sich intensiv Gedanken zu den Themen Modelloptimierung, Speichermanagement und Rechenressourcen gemacht werden.
- Ressourcenbedarf: LLMs benötigen eine erhebliche Menge an Rechenleistung, insbesondere wenn es um Training oder Inferenz in Echtzeit geht. Leistungsstarke GPUs sind für die Arbeit mit diesen Modellen unerlässlich, und der Betrieb eines Modells in einer produktionsreifen Umgebung erfordert oft spezialisierte Hardware. Dies kann hohe Anschaffungskosten bedeuten, insbesondere wenn das Modell in großem Maßstab eingesetzt werden soll.
Anbieter von Open-Source-LLMs
- Hugging Face Transformers: Hugging Face bietet eine umfangreiche Bibliothek von vortrainierten Modellen, darunter bekannte LLMs wie GPT, BERT, T5 und viele mehr. Die Plattform verfügt über eine riesige Community und ist ideal für Entwicklerteams, die mit Open-Source-LLMs experimentieren oder sie in eigene Anwendungen integrieren wollen.
- Meta’s LLaMA: LLaMA ist ein effizientes und leistungsfähiges Modell, das von Meta entwickelt und Open-Source zur Verfügung gestellt wurde. Es ist besonders darauf ausgelegt, weniger Rechenressourcen zu verbrauchen als andere Modelle seiner Klasse, was es zu einer attraktiven Option für Teams macht, die leistungsfähige LLMs lokal betreiben möchten. LLaMA ist zudem auch über die Databricks Plattform als Open Source Modell integrierbar.
- Mistral AI: Das LLM des französischen Unternehmens Mistral AI bietet eine weitere leistungsfähige Open-Source-Alternative. Es ist darauf ausgelegt, Sprachmodelle mit hoher Performance auch auf weniger spezialisierten Hardwareumgebungen auszuführen. Auch Mistral ist als Open Source Modell in Databricks integriert.
Welche Option ist die Richtige?
Die Wahl zwischen Cloud-basierten APIs und Open-Source-LLMs hängt von den Anforderungen des Entwicklerteams ab. Cloud-Lösungen bieten schnelle, einfache Implementierung, Skalierbarkeit und kontinuierliche Updates, sind jedoch kostenintensiv und können Datenschutzprobleme aufwerfen. Open-Source-Modelle bieten maximale Kontrolle, Flexibilität und bessere Datenschutzoptionen, erfordern aber hohe Rechenressourcen und technisches Know-how. Beide Ansätze haben ihre Stärken: Cloud-Modelle für schnelle und unkomplizierte Anwendungen, Open-Source für maßgeschneiderte, datensichere Lösungen. Die richtige Wahl des Modells hängt also stark vom Use Case ab und sollte gründlich abgewägt werden.
Ansätze und Methoden von Verwendung von Large Language Models
Sobald sich das Entwicklerteam sicher ist, welche technische Umsetzung sie für eine gegebenen Use Case als sinnvoll betrachtet, kann mit der Implementierung von LLM-Funktionalitäten begonnen werden. Bei der Integration von LLMs in Software gibt es mehrere Ansätze, um ihre Leistung und Genauigkeit für spezifische Aufgaben zu optimieren. Die drei gängigsten Methoden sind Prompt Engineering, Retrieval-Augmented Generation (RAG) und Fine-Tuning. Jede dieser Techniken bietet unterschiedliche Stärken und eignet sich für spezifische Anwendungsfälle.

1. Prompt Engineering
Was ist das?
Prompt Engineering bezeichnet die Technik, präzise und gezielte Eingabebefehle (Prompts) zu entwickeln, um das Modell zu optimieren, ohne es zu verändern. Durch das richtige Formulieren von Fragen oder Anweisungen kann das Verhalten des Modells beeinflusst werden.
Anwendungsfälle
Prompt Engineering eignet sich besonders für schnelle Einsätze, bei denen das Modell ohne größere Anpassungen genutzt werden soll. Typische Anwendungsbeispiele sind automatisierte Zusammenfassungen, Sentimentanalyse oder Entity Extraction, also das Extrahieren von bestimmten Stellen aus einem Text wie beispielsweise das Datum.
Vorteile
- Keine Modellanpassung erforderlich
- Schnell umsetzbar und flexibel
- Geringe Kosten
Nachteile
- Begrenzte Kontrolle über die Ergebnisse
- Stark abhängig von der Qualität der Prompts
- Nicht immer geeignet für komplexe Aufgaben
2. Retrieval-Augmented Generation (RAG)
Was ist das?
RAG kombiniert LLMs mit einem Retrieval-Modul, das relevante Informationen aus externen Datenquellen (z.B. Datenbanken oder Dokumenten) abruft. Das Modell verwendet diese abgerufenen Informationen, um die Generierung zu verbessern und präzisere Antworten zu liefern.
Anwendungsfälle
RAG wird oft in Szenarien verwendet, bei denen das Modell auf aktuelles Wissen zugreifen muss, z.B. in Suchmaschinen, Wissensdatenbanken oder spezialisierten Assistenzsystemen. Dadurch ist auch die Erstellung eines Chat-Bots, welches mit bestimmtem internem Wissen ausgestattet ist, möglich.
Vorteile
- Kann auf externe, aktuelle Informationen zugreifen
- Liefert bessere Ergebnisse in wissensintensiven Aufgaben
- Flexibel und skalierbar
Nachteile
- Komplexere Implementierung als reine LLM-Nutzung
- Abhängigkeit von der Qualität und Relevanz der abgerufenen Daten (Optimaler Retrieval-Prozess mitunter schwer zu erreichen)
- Erhöhte Rechenressourcen erforderlich
3. Fine-Tuning
Was ist das?
Beim Fine-Tuning wird ein vortrainiertes Modell auf spezifischen Datensätzen nachtrainiert, um es an bestimmte Anwendungsfälle anzupassen. Dadurch kann das Modell z.B. branchenspezifisches Vokabular oder spezielle Aufgaben besser bewältigen.
Anwendungsfälle
Fine-Tuning wird häufig eingesetzt, wenn LLMs in spezialisierten Umgebungen verwendet werden sollen, wie etwa juristischen Texten, medizinischer Forschung oder Branchenlösungen.
Vorteile
- Maßgeschneiderte Anpassung des Modells an spezifische Aufgaben
- Bessere Leistung bei spezialisierten Anwendungsfällen
- Verbesserte Genauigkeit und Relevanz
Nachteile
- Hohe Rechenressourcen erforderlich
- Komplex und zeitintensiv
- Höhere initiale Kosten
Jeder dieser Ansätze hat seine eigenen Stärken und Herausforderungen. Prompt Engineering ist ideal für schnelle, kostengünstige Lösungen, während RAG nützlich ist, wenn aktuelle oder spezifische externe Daten benötigt werden. Fine-Tuning bietet maximale Anpassung, erfordert jedoch mehr Ressourcen und Expertise. Welcher Ansatz gewählt wird, hängt von den Anforderungen des Projekts, den verfügbaren Ressourcen und der Komplexität der Aufgaben ab. Für weitere Informationen können Sie gerne in unseren speziellen Blog-Artikel zu Prompt Engineering, RAG oder Fine-Tuning einen besseren Überblick gewinnen.

Implementierung- Vom PoC zur Production
Um erfolgreiche Projekte mit Large Language Models (LLMs) umzusetzen, hat sich ein zweistufiger Ansatz bewährt: Zunächst startet man mit einer Proof of Concept (PoC)-Phase, um schnell und unkompliziert zu prüfen, ob ein bestimmter Use Case realisierbar ist. Bei positivem Ausgang folgt die Überführung des PoCs in ein produktionsreifes System.

Phase 1: Proof of Concept (PoC)
In der PoC-Phase stehen die Umsetzbarkeit und die Machbarkeit im Vordergrund. Das Ziel ist es, möglichst rasch zu verwertbaren Ergebnissen zu kommen, ohne sich direkt in komplexe technische Strukturen zu verstricken. In dieser Phase werden Testsysteme meist ohne aufwendige Integrationen erstellt. Die Evaluation erfolgt explorativ und experimentell, häufig über rudimentäre Systeme, die einfach zu handhaben sind.
Der Fokus liegt hierbei oft auf grundlegenden Ansätzen wie einfachem Prompt Engineering oder dem Einsatz von Retrieval-Augmented Generation (RAG), da diese leicht implementierbar sind und schnelle Ergebnisse liefern. Für die technische Anbindung reicht zunächst eine direkte Nutzung der GPT-API aus, da die Kosten für API-Aufrufe in dieser Phase nicht kritisch sind – schließlich handelt es sich um einen Testbetrieb
Phase 2: Produktionsreifes System
Fällt der PoC positiv aus, beginnt der zweite Schritt: die Entwicklung eines Systems, das „Production Ready“ ist. Hierbei werden umfangreiche technische Infrastrukturen angebunden, z.B. Datenbanken und weitere Services, um das System leistungsfähiger und skalierbarer zu machen. Ein vollumfängliches Deployment, inklusive Frontend-Integration, wird notwendig, um den Anforderungen an Sicherheit, Performance und Kosten gerecht zu werden.
Ein weiterer wichtiger Aspekt dieser Phase ist die Einführung von automatisiertem Monitoring zur Überwachung von Modellperformance und Systemstabilität. Zusätzlich werden in diesem Schritt meist spezialisiertere LLMs oder erweiterte Techniken eingesetzt, um die Präzision und Qualität der Lösung weiter zu optimieren. Dies kann auch den Einsatz von Custom Models, Datenanreicherung oder die Integration von Fine-Tuning beinhalten, um das Modell noch besser auf spezifische Anforderungen abzustimmen.

Vorteile des 2-Stufen-Plans
Durch diesen zweistufigen Ansatz können Entwicklungsteams flexibel und effizient arbeiten. In der PoC-Phase wird rasch Klarheit über die Machbarkeit eines Use Cases gewonnen. Bei Erfolg ist der Übergang zu einer produktiven Lösung fließend, da die Grundlagen bereits geschaffen sind. Dieser Plan minimiert das Risiko und ermöglicht gleichzeitig eine gezielte Skalierung des Systems. So lassen sich innovative LLM-Projekte schrittweise von der Idee bis zur produktiven Anwendung führen – mit einem klaren Fokus auf Effizienz, Qualität und Kostenkontrolle.
Fazit
Large Language Modelle eröffnen eine bislang unerreichte Dimension im Verständnis und in der Generierung menschlicher Sprache. Basierend auf der Transformer-Architektur und fortschrittlichem Deep Learning, das auf Milliarden von Datensätzen trainiert wurde, zeichnen sich diese innovativen Modelle durch eine herausragende „Foundation-Qualität“ aus. Sie sind so gestaltet, dass sie für eine Vielzahl unterschiedlichster Aufgaben eingesetzt werden können, da sie in der Lage sind, Muster und Strukturen rasant zu verallgemeinern und zu abstrahieren.
Diese Vielseitigkeit bringt jedoch auch Herausforderungen mit sich: Es existiert keine universelle Lösung für spezifische Probleme. Daher muss ein Entwicklerteam sowohl hinsichtlich der technischen Voraussetzungen (Cloud vs. Open-Source) als auch in Bezug auf die zu verwendenden Methodiken auf umfangreiche Expertise und tiefgreifendes Fachwissen zurückgreifen.
Wenn Sie mehr zum Thema Large Language Models erfahren möchten, kontaktieren Sie uns gerne.
FAQ: Die wichtigsten Fragen schnell beantwortet
Large Language Modelle (zu dt. Große Sprachmodelle) arbeiten auf Basis von Deep Learning Modellen mit menschlicher Sprache, um z.B. Texte zu generieren oder Antworten auf Fragen zu geben. Entwickler müssen das Modell hierfür mit Milliarden von Daten trainieren. Ein bekanntes Beispiel für ein Large Language Modell ist ChatGPT.
Die LLMs werden im Durchschnitt in drei Schritten trainiert:
1. Das Modell wird mit unstrukturierten Daten antrainiert (Unsupervised Learning)
2. Es folgt ein Fine-Tuning mit strukturierten Daten (Self-Supervised Learning)
3. Fehlerhafte Datensätze werden identifiziert und mit geprüften Datensätzen neu trainiert (Reinforcement Learning)
Large Language Modelle basieren im Gegensatz zu Natural Language Processing-Modellen und Language Modellen auf Milliarden bis Billiarden von Daten. So erreicht LLM den Bereich des Deep Learnings und kann im Gegensatz zu den anderen beiden Konzepten komplexe Anfragen erfassen und verarbeiten.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte






