


Streaming-Daten sind Daten, die mit einem Streaming-Framework in „Echtzeit“ verarbeitet werden. Der Unterschied zur reinen Nachrichtenverarbeitung besteht darin, dass komplexe Operationen (Aggregationen, Joins, etc.) auf den Datenströmen durchgeführt werden können.
Im Big Data Umfeld ist Streaming ein interessantes Entwicklungsfeld, das sich schnell weiterentwickelt und in vielen Anwendungsfällen einen Mehrwert bietet.
In diesem Artikel gebe ich einen tiefen Einblick in die grundlegenden Aspekte, die für Streaming Data relevant sind und gehe auf die bekanntesten Streaming Data Frameworks ein.
Was sind Streaming Daten?
Streaming-Daten sind Daten, die kontinuierlich von Quellsystemen erzeugt und in kleinen Paketen gesendet werden. Ein Big Data Streaming Framework empfängt diesen Datenstrom und verarbeitet die Informationen im Arbeitsspeicher, bevor sie auf eine Festplatte geschrieben werden.
“A type of data processing engine that is designed with infinite data sets in mind. Nothing more.”
Tyler Akidau Software Engineer at Google
Streaming Daten können aus verschiedensten Systemen kommen: Log-Daten aus einem ERP-System, E-Commerce Events (Views, Orders, Baskets), Tracking-Events auf Mobile Apps, Geolocations aus Webanwendungen, Geschäftsvorfälle aus Kundencentern oder Nutzungsdaten von bestimmten Produkten.
All diese Informationen können wir mit Streaming-Daten schneller bereitstellen und verarbeiten.
Arten von Streaming Daten
Grundsätzlich können Streaming-Daten in zwei verschiedene Arten von Streaming unterteilt werden: Natives Streaming und Micro-Batching. Im Folgenden werden die Unterschiede zwischen diesen beiden Arten beschrieben.
Natives Streaming
Beim nativen Streaming wird jeder ankommende Datensatz sofort von der Streaming-Engine verarbeitet, ohne auf andere Datensätze zu warten (Einzelsatzverarbeitung). Natives Streaming reagiert schneller auf eingehende Datensätze, was zu einer geringeren Latenz und einem höheren Durchsatz führt.

Native Streaming Frameworks: Apache Storm, Apache Flink, Kafka Streams, Samza (und Spark Continuous Processing Experimental Release in Apache Spark 2.3.0)
Micro-Batching
Bedeutet, dass alle paar Millisekunden/Sekunden ein Batch ausgeführt wird. Dadurch entsteht ein kleiner Zeitverzug.
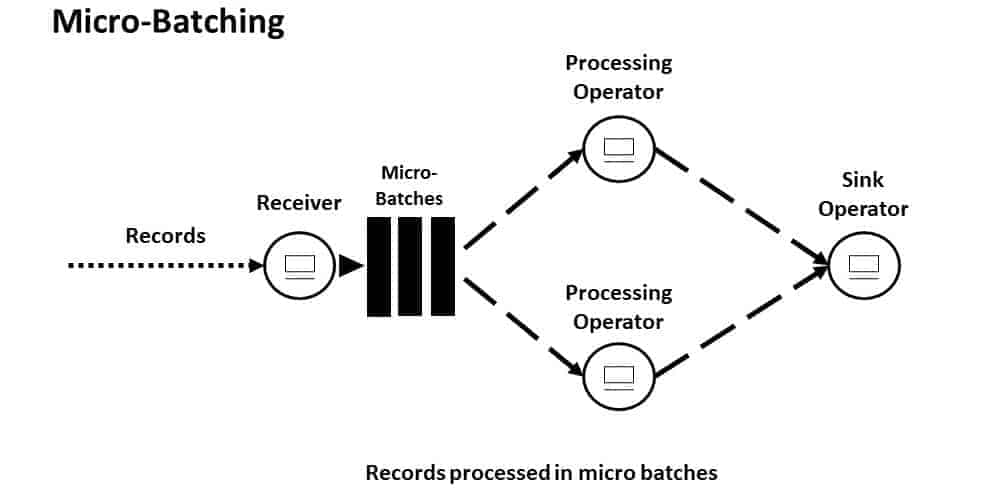
Frameworks: Apache Spark, Apache Storm Trident
Native Streaming vs. Micro Batching
Beide Arten haben Vor- und Nachteile. Natives Streaming hat den Vorteil, dass sehr niedrige Latenzen erreicht werden können. Gleichzeitig bedeutet dies, dass es schwierig ist, eine hohe Fehlertoleranz zu erreichen, ohne den Durchsatz zu verringern (Checkpoints müssen geschrieben werden usw.). Bei nativem Streaming ist das State-Management dagegen einfach.
Micro-Batching, verarbeitet die Daten in kleinen Batches und hat den Vorteil der Fehlertoleranz. Auch der Durchsatz ist an sich nicht schlecht. Effizientes Zustandsmanagement ist eine Herausforderung für Entwickler.
| Native Streaming | Micro-Batching |
| Datensätze werden bei Ankunft verarbeitet – geringerer Durchsatz + geringe Latenz – Fehlertoleranz ist ressourcenintensiv | Datensätze werden in kleinen Batches verarbeitet + höherer Durchsatz – höhere Latenz + einfachere Fehlertoleranz |
Wichtige Aspekte bei Streaming Data
Um die Big Data Streaming Frameworks mit ihren jeweiligen Stärken und Schwächen zu verstehen, ist es wichtig, die verschiedenen Aspekte von Streaming-Daten und die Probleme, die bei der Verarbeitung von Streams auftreten, kurz zu besprechen.
Fehlertoleranz:
Im Falle eines Fehlers, wie z.B. Knotenfehler oder Netzwerkprobleme, sollte das Framework in der Lage sein, den Prozess an der Stelle wieder zu starten, an der er gestoppt wurde. Dies kann durch sogenannte Checkpoints erreicht werden, indem Metadaten zu den verarbeiteten Daten geschrieben werden. Dadurch wird der Offset vom Checkpoint neu geladen.
State Management:
Bei der Zustandsverwaltung wird ein Zustand gespeichert (z.B. Zählerstände über verschiedene Schlüssel in einem bestimmten Zeitraum), hier sollte das Framework in der Lage sein, den Zustand zu halten und ein Update durchzuführen.
Garantierte Verarbeitung:
Es gibt grundsätzlich 3 unterschiedliche Arten von Stream Verarbeitung:
- Bei Atleast-once wird der Datensatz auf jeden Fall einmal verarbeitet – auch bei Cluster-Fehlern.
- Atmost-once kann die Verarbeitung nicht garantieren.
- Bei Exactly-once wird die einmalige Verarbeitung garantiert und ist somit die präferierte Variante. Oft leidet die Performance unter diesem Ziel.
Geschwindigkeit:
Beschreibt die Latenz, mit der ein Datensatz verarbeitet wird (Zeilen pro Sekunde) und die Möglichkeit der Skalierung bei mehr Last. Die Latenz sollte so gering wie möglich und der Durchsatz so hoch wie möglich sein. Beide zu erreichen ist oft schwer, daher geht es um eine gute Balance.
Entwicklungsstand-/Marktreife:
Im Streamingmarkt gibt es viele „neue“ Player, die verschiedene Ansätze verfolgen. Wichtig ist es bei der Auswahl, auf ein Framework zu setzten, welches bei großen Unternehmen erfolgreich in die Produktion implementiert wurde. Auch eine große Community hilft dabei, das Framework weiterzuentwickeln und ggf. Hilfe aus der Community zu bekommen.
Weitere Features:
Um komplexe Logik auf Streams abzubilden, brauchst du bestimmte Funktionen:
Event Time Processing bezeichnet die Verarbeitung basierend auf der Eventerzeugungszeit. Manche Streaming Frameworks bieten diese Funktion nicht an und verarbeiten nach Ankunftszeitpunkt.
Zeitfenster Funktionen (Windowing) sind Aggregationen über ein bestimmtes Zeitfenster (bspw. sum(revenue) in last 4h)
Anwendung von analytischen Modellen im Stream. Natürlich bieten einige Streaming Frameworks auch die Möglichkeit der Anwendung eines Machine Learning Modells im Stream.
Herausforderungen von Streaming Daten
Streaming Data bringt eine Menge Herausforderungen in der Anwendung mit sich. Unter anderem sind Punkte wie
- das Datenvolumen,
- die Komplexität der Architektur,
- die Dynamik von Datenströmen und
- die Abfrageverarbeitung
Herausforderungen, die wir uns nun genauer ansehen.
1. Datenvolumen und unbegrenzte Speicheranforderungen
Die größte Herausforderung bei der Verarbeitung von Datenströmen liegt in der Menge und Geschwindigkeit der Daten, die in Echtzeit verarbeitet werden müssen. Frameworks und Architekturen für die Verarbeitung von Datenströmen müssen einen kontinuierlichen Datenstrom verarbeiten, der sehr groß sein und aus verschiedenen Quellen stammen kann.
Datenverarbeitungsinfrastrukturen müssen auch mit unbegrenzten Speicheranforderungen zurechtkommen. Dies liegt daran, dass Datenströme kontinuierlich sind und kein definiertes Ende haben. Daher muss das System in der Lage sein, Daten unbegrenzt oder zumindest so lange wie nötig zu speichern.
2. Komplexität der Architektur und Überwachung der Infrastruktur
Eine weitere Herausforderung bei der Verarbeitung von Datenströmen ist die Komplexität der erforderlichen Architektur und Infrastruktur. Systeme zur Verarbeitung von Datenströmen sind häufig verteilt und müssen in der Lage sein, eine große Anzahl gleichzeitiger Verbindungen und Datenquellen zu verarbeiten, was die Verwaltung und Überwachung auftretender Probleme erschweren kann, insbesondere in großem Maßstab.
Datenströme basieren auf einer bestimmten Art komplexer Architektur, so dass der Aufbau einer eigenen Architektur eine schwierige Aufgabe sein kann:
- Zunächst ist ein Stream-Prozessor erforderlich, um die Streaming-Daten aus der Eingabequelle aufzunehmen;
- dann brauchen Sie ein Tool, um sie zu analysieren oder abzufragen, eine Datentransformation durchzuführen und die Ergebnisse auszugeben, damit der Benutzer entsprechend auf die Informationen reagieren kann.
- Schließlich müssen die gestreamten Daten irgendwo gespeichert werden.
3. Die dynamischen Natur von Datenströmen
Da Datenströme von Natur aus dynamisch sind, müssen Systeme zur Verarbeitung von Datenströmen anpassungsfähig sein, um mit Konzeptabweichungen umgehen zu können – was einige Datenverarbeitungsmethoden ungeeignet macht – und mit begrenzter Zeit und begrenztem Speicher arbeiten.
Darüber hinaus hat Big Data Streaming inhärente dynamische Eigenschaften, was bedeutet, dass es schwierig ist, im Voraus zu wissen, wie groß die notwendige oder wünschenswerte Anzahl von Clustern sein wird. In diesem Fall müssen Datenströme dynamisch mit skalierbarer Verarbeitung analysiert werden, um Entscheidungen in einem begrenzten zeitlichen und räumlichen Fenster zu ermöglichen.
4. Abfrageverarbeitung über Datenströme
Ein Stream-Query-Prozessor muss in der Lage sein, mehrere Anfragen über eine Gruppe von Eingabedatenströmen zu verarbeiten, um ein breites Spektrum von Benutzern und Anwendungen zu unterstützen. Es gibt zwei Schlüsselparameter, die die Effizienz der Verarbeitung einer Sammlung von Abfragen über eingehende Datenströme bestimmen: die Menge an Speicher, die dem Stream-Verarbeitungsalgorithmus zur Verfügung steht, und die Verarbeitungszeit, die der Abfrageprozessor pro Element benötigt.
Der erste Punkt stellt eine besondere Herausforderung bei der Entwicklung eines Systems zur Verarbeitung von Datenströmen dar, da in einer typischen Streaming-Umgebung nur eine begrenzte Menge an Speicherressourcen für jede anstehende Anfrage zur Verfügung steht. Daher muss der Algorithmus zur Verarbeitung des Datenstroms speichereffizient und in der Lage sein, die Daten schnell genug zu verarbeiten, um mit der Geschwindigkeit, mit der neue Daten eintreffen, Schritt zu halten.
Wie lassen sich diese Herausforderungen lösen? Unter anderem können Dienste wie der Auto Loader von Databricks Abhilfe verschafften.
Streaming Daten Frameworks im Vergleich
| Framework | Vorteile | Nachteile |
| Apache Storm (Native Streaming) | – Natives Streaming – geringe Latenz – hoher Durchsatz – gut für nicht komplexe Streaming Use Cases | – Keinen impliziten Support für Zustandsmanagment – keine Feature für Aggregationen, Windows etc. – Verarbeitung nur Atleast-once |
| Apache Spark Structured Streaming (Micro-batching) | – Unterstützt Lambda-Architektur – hoher Durchsatz – hohe Fehlertoleranz – einfaches API – große Community – Verarbeitung Exactly Once | – Kein nativer Stream – viele Parameter zum Tunen von Streams – Stateless – ist hinter Flink in Bezug auf Advanced Features |
| Apache Spark Continuous Processing (Native Streaming) | – Unterstützt Lambda-Architektur – hoher Durchsatz – hohe Fehlertoleranz – einfaches API – große Community – Verarbeitung Exactly Once | – Weniger Funktionen verfügbar (groupBy etc.) – stark in den Anfängen |
| Apache Flink (Native Streaming) | – Unterstützt Lambda – Führer in Streaming Umfeld – geringe Latenz und hoher Durchsatz – nicht zu viele Parameter (Auto-adjusting) – Verarbeitung Exactly Once | – Späte Entwicklung daher Nachteil im Markt – kleinere Community als Spark – keine Adaption für Batch Modus |
| Kafka Streams (Native Streaming) | – Kleine einfache API daher gut für Microservices – gute für IoT – Exactly Once – braucht kein dediziertes Cluster | – Sehr nah an Kafka (ohne geht’s nicht) – muss sich noch beweisen – keine riesen Prozesse möglich = eher einfache Logik |
| Samza (Native Streaming) | – Einfaches API – Gut darin große Zustände von Streams zu speichern (gut für Joins von Streams) – hohe Fehlertoleranz – hoch performant | – Starke Verbundenheit zu Kafka und Yarn – Atleast-once processing – wenig erweiterte Streaming Funktionen(Watermarks, Triggers, Sessions) |
Streaming Daten Use Cases im Marketing
Streaming Daten sind noch ein sehr neues Thema, welches sich zurzeit stark weiterentwickelt. Für viele Unternehmen sind Use Cases mit Streaming Daten noch Ideen oder Uses Cases, die in kleinen Proof of Concept Projekten erprobt werden. Zunehmender Einsatz von Big Data Plattformen, fördert das Thema allerdings stark und viele Unternehmen zeigen Interesse.
Besonders im Marketing sind die Use Cases nicht so offensichtlich wie im IoT Bereich, aber auch im Marketing gibt es interessante Use Cases:
- Personalisierung E-Commerce Checkout: Um die richtige Empfehlung im Checkout Prozess anbieten zu können, braucht man die neusten Daten in Real Time. Dazu zählt die Klickhistorie aus der aktuellen Session, der aktuelle Warenkorb und gespeicherte Interaktionen aus einer längeren Historie. Um hier die richtige Empfehlung abzugeben braucht das Machine Learning Modell die Daten im Moment des Checkouts, so können die wichtigen Sessioninformationen einen UpLift bringen.
- Streaming ETL: Oft ist die Nacht zu kurz für die bestehenden ETL-Strecken. Auch hier können interessante Use Cases mit Streaming Daten umgesetzt werden. Wir können die Daten sofort mit Big Data Streaming Frameworks verarbeiten, wertvolle Zeit sparen und Entscheidungen schneller treffen. Hier ist ein interessantes Video zu Streaming-ETL.
- Trigger Marketing Kampagnen: Die Informationen schnell zu verarbeiten ist ein Wettbewerbsvorteil. Mit Data Streaming können wir bestimmte Kundenevents in Echtzeit bearbeiten, um somit den Kunden anlassbezogen über ein Event, anstatt in einer Massenkampagne, anzusprechen.
Streaming Analytics
Streaming Analytics stellt Machine Learning Modelle im Stream bereit, sodass ein Modell Scoring auf die gerade eintreffenden Streaming Daten durchgeführt wird.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten auf Ihrem Weg zur Data Driven Company.
Für komplexe Architekturen und Use Cases werden anschließend oft Machine Learning Features für jeden Kunden vorberechnet und in einem Feature Store gespeichert. Bei einem eintreffenden Datensatz können wir dann das Profil in Echtzeit abfragen und mit dem Stream joinen. Durch die weiteren Informationen, die man bspw. zu einem Kunden hat, können wir das Modell mit historischen Daten anreichern und anwenden.
Streaming Analytics wird im Marketing vor allem im Bereich der Personalisierung von Diensten und Online Shops eingesetzt. Jede neue Interaktion führt zu einem neuen Ergebnis im Recommender System und damit zu veränderten Empfehlungen.
Streaming Daten bringen in der Anwendungen ein paar Herausforderungen mit sich, die von dem Auto Loader von Databricks gelöst werden. Welche Herausforderungen das sind, und wie Auto Loader diese löst, erfahren Sie in unserem Wiki Eintrag: Auto Loader von Databricks
Sie wollen mehr zum Thema Streaming Data erfahren? Kontaktieren Sie uns!
Wir bieten außerdem eine umfangreiche Data Science an, in welcher wir mit Ihnen zusammen Schritt für Schritt KI Projekte umsetzen und das maximale aus Ihren Daten holen.
Weitere interessante Artikel:
- Databricks Lakebase einfach erklärt: Architektur, Funktionen und Einsatz im Mittelstand
- Conversational BI im Vergleich: Databricks Genie vs. Microsoft Fabric Data Agent
- Databricks Summit 2026: Diese neuen Features sollten Sie jetzt auf Ihre Roadmap setzen
- Databricks Genie Space: Einschätzung und Best-Practices
- Databricks Genie Code: So automatisiert der KI-Agent deine Data-Arbeit

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte






