Was ist der Unterschied zwischen den Data-Plattformen Databricks und Snowflake? Wann lohnt sich für Sie welche Plattform?
Dieser Frage stellen wir uns und geben einen ausführlichen Vergleich.
Kaum ein Unternehmen kommt heute ohne Datenanalyse ans Ziel. Der Wettbewerb auf dem Markt ist zu schnelllebig und zu dynamisch, um Strategien mit dem Bauchgefühl zu lenken: Wir brauchen Zahlen und Fakten. Allerdings ist die Datenaufbereitung von BigData keine Aufgabe, die mal eben nebenbei erledigt ist. Sie verlangt nach Zeit und Expertise. Die beiden Cloud-Giganten Databricks und Snowflake haben sich auf die Lösung dieser Herausforderung spezialisiert und konkurrieren um den Platz der besten Datenspeicher-Architektur.
In diesem Beitrag möchten wir untersuchen, worin sich die beiden Spitzenreiter unterscheiden und welche Plattform besser zu Ihren Bedürfnissen passt.
Für Sie auch interessant:
Lassen Sie uns starten!
Vorstellung der Unternehmen
Databricks und Snowflake sind führende Anbieter in der Branche der Datenverarbeitung. Ihre Produkte helfen Unternehmen ihre wachsenden Mengen an strukturierten und unstrukturierten Daten zu verarbeiten und aus ihnen Nutzen zu generieren. Normalerweise erledigen Data-Warehouses die Aufgabe der Datenspeicherung, um anschließend Analysen mit BI-Dashboards durchzuführen. Dieser Prozess ist zeitaufwendig und ignoriert unstrukturierte Daten wie Text, Video oder Foto.
Durch Cloud-Tools wie Databricks und Snowflake ist es allerdings möglich geworden, die wachsenden Datenpools der Unternehmen nahezu in Echtzeit zu speichern, unabhängig vom Datenformat.
Snowflake positioniert sich selbst als die „Data Cloud“ für Unternehmen, während Databricks sich als „Data Lakehouse“ präsentiert. Sehen wir uns das genauer an.

Warum Lakehouses die Daten-Architektur der Zukunft sind
In unserem Whitepaper erfahren Sie:
- Wie sich ein Data Lakehouse von anderen Architekturen unterscheidet.
- Wie Sie durch ein Lakehouse KI-Anwendungen schneller umsetzen.
- Wie Sie ihr internes Team befähigen selbstständig KI Projekte zu implementieren.
Der Hintergrund von Snowflake
Im Jahr 2012 taten sich drei Data-Warehousing-Experten – Benoit Dageville, Thierry Cruanes und Marcin Zukowski (frühere Orcale Mitarbeiter) – zusammen und gründeten das Unternehmen, das heute als „Snowflake“ bekannt ist. Die so genannte „Data Cloud“ sollte Big Data auf Basis eines Data Warehouse in der Cloud verarbeiten können.
Auf diese Weise konnten die drei Gründer proaktiv die Probleme lösen, die in On-Premises-Lösungen eingebettet waren. Zum einen speichert Snowflake Daten unabhängig davon, wo die Berechnungen durchgeführt werden. Dabei besteht eine große Diskrepanz zwischen den Speicherkosten und den Kosten für die Rechenleistung. Diese Trennung bedeutet nicht nur, dass sie unabhängig voneinander skaliert werden können, sondern auch, dass die Kunden nur für das bezahlen, was sie tatsächlich nutzen. Zum anderen können Kunden virtuelle Data Warehouses schnell und in Echtzeit einrichten und in diesen interaktiv arbeiten.
Wir haben Snowflake einen eigenen Blogbeitrag gewidmet, wo wir die Plattform im Detail erklären: Was ist Snowflake?
Der Hintergrund von Databricks
Databricks hat seinen Ursprung in der Wissenschaft und der Open-Source-Community und wurde 2013 von den ursprünglichen Entwicklern von Apache Spark, Delta Lake und MLflow gegründet: Ali Ghodsi, Matei Zaharia, Reynold Xin und Ion Stoica. Als weltweit erste und einzige Lakehouse-Plattform in der Cloud, kombiniert Databricks das Beste aus Data Warehouses und Data Lakes und bietet eine offene und einheitliche Plattform für Daten und KI.
Das Databricks-Projekt wurde ins Leben gerufen, um die Nutzung von Spark zu vereinfachen. Databricks übernimmt
- die Erstellung und Konfiguration von Server-Clustern,
- das Herstellen von Verbindungen zu verschiedenen Dateisystemen,
- die Erstellung von Programmierschnittstellen für Python, Scala und SQL,
- das automatisches Herunterfahren nach Nichtnutzung (um Geld zu sparen)
und viele andere Annehmlichkeiten.
Auch über Databricks haben wir einen ausführlichen Blogbeitrag veröffentlicht: Was ist Databricks?
Schauen wir uns die Fakten über die Plattformen gegenübergestellt an.
Die folgende Tabelle dient als Übersicht für den Vergleich der beiden Unternehmen.
| Databricks | Snowflake | |
| Gründungsjahr | 2013 | 2012 |
| Leistungsmodell (Service) | Platform as a Service (PaaS) | Software as a Service (SaaS) |
| Hauptkundschaft | Analysten, Data Scientists, Data Engineers | Data Analysten, Data Engineers |
| Fokus | Apache Spark; Vereinfachung der Verwaltung der Infrastruktur | Nutzt SGL-Engine, um in Datenbanken gespeicherte Informationen zu verwalten |
| Unternehmensgröße Mitarbeiteranzahl | 5.000 | 2.000 |
| Jahresumsatz | 800 Mio. US-Dollar (2021) | 592 Mio. US-Dollar (2021) |
Nachdem wir einen Blick in die Vergangenheit geworfen haben, gehen wir zu dem Vergleich der aktuellen Datenarchitektur beider Unternehmen über.
Die Positionierung im Datenverwaltungsprozess
Beide Unternehmen verfolgen die gleiche Vision: die einzige „Big Data“-Plattform für moderne Unternehmen zu werden und die Datenanalyse zu vereinfachen. Dabei positionieren sich Snowflake und Databricks an verschiedenen Stellen in dem Datenverwaltungsprozess.
Snowflake fokussiert sich auf die Speicherung und Verarbeitung von Daten, primär mit SQL (Data Engineering). Sie kümmern sich aber auch um die unten Aufgeführten Punkte, wie die Datensicherheit. Data Science ist bei Snowflake ein recht frisches Thema und wird gerade ausgebaut wie mit Snowflake Cortex AI für generative KI.
Databricks setzt bei der Datenaufbereitung an und deckt das gesamte Spektrum der Datenverarbeitung ab. Von Data Engineering über die Datenmodellierung bis hin zur Operationalisierung von Machine Learning Modellen, Data Science und Machine Learning. Auch die Aspekte der Datensicherheit und Data Governance sind durch den Unity Catalog von Databricks garantiert.
Um einen guten Vergleich zwischen dem Data Lakehouse und der Data Cloud ziehen zu können, sehen wir uns zunächst die Architektur und das Vendor Lock-In an.
Wie unterscheidet sich die Architektur von Snowflake und Databricks?
Der größte Unterschied der beiden Architekturen liegt im Ursprung. Während Databricks seinen Ursprung im Machine Learning, Data Lakehouse und Spark findet, baut die Data Cloud von Snowflake auf dem Konzept der Data Warehouses auf.
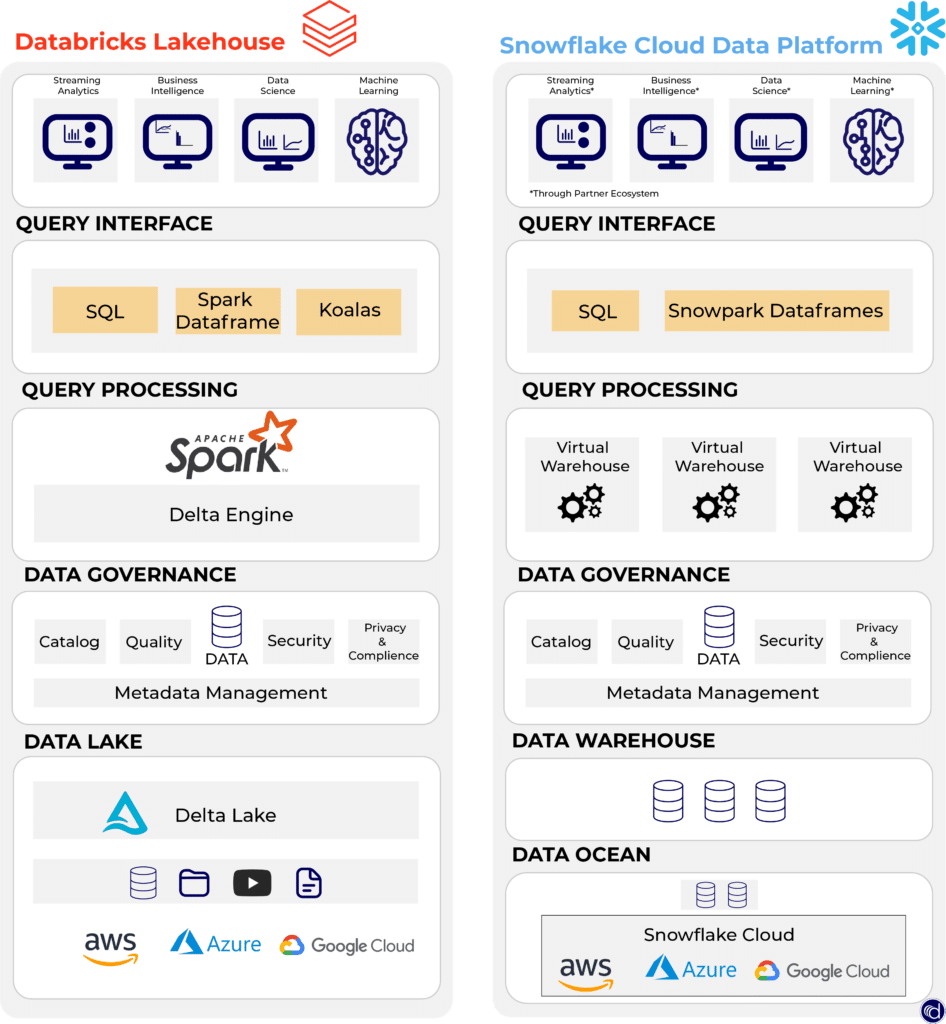
Sehen wir uns das genauer an.
Data Cloud Architektur (Snowflake)
Snowflake ist eine Daten-Cloud-Plattform, die im Jahr 2014 vorgestellt wurde. Kunden können neue virtuelle Cluster (private virtuelle Cluster) einrichten, die alle durch die vom Kunden benötigte Anzahl von Knoten betrieben werden. Größere Unternehmen können mehrere Instanzen oder Multi-Cluster einrichten.
Wenn Kunden ein neues virtuelles Cluster einrichten, können sie den Cloud-Anbieter und die Region angeben, und eine Größe (von XS bis 4XL) für den Computer-Cluster auswählen. Snowflake verwaltet und skaliert die Infrastruktur der eigenen Plattform bei Cloud-Anbietern wie AWS und Azure, hilft aber auch bei der Skalierung von Kundeninstanzen, die innerhalb von Snowflake laufen.
Die Data Cloud besteht aus drei voneinander unabhängig skalierbaren Komponenten:
- Speicher,
- Rechenleistung
- und Cloud-Services.
Die ursprüngliche Stärke von Snowflake war die Trennung von Rechen- und Speicherleistung. Dieser Wettbewerbsvorteil wurde jedoch ausgehöhlt, da die meisten modernen Datenplattformen ähnliche Funktionen in ihrer Infrastruktur anbieten.
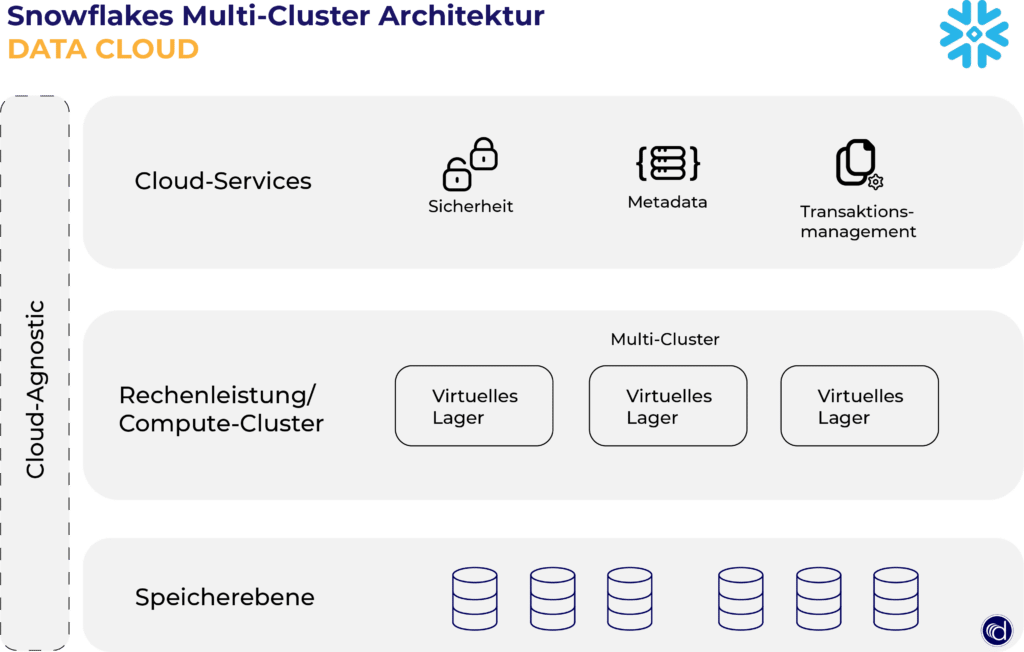
Wir stellen Ihnen die einzelnen Ebenen der Architektur vor.
Speicherebene:
Die Speicherebene von Snowflake nimmt riesige Mengen und Varianten von strukturierten, halbstrukturierten und unstrukturierten Daten auf, um einen einheitlichen Datensatz zu erstellen. Physisch ist die Speicherebene von der Rechenleistung getrennt. Das ermöglicht eine von der Rechenleistung unabhängige Skalierbarkeit für das Data Warehousing. Die Speicherebene von Snowflake basiert auf AWS S3, Azure Blob und Google Cloud Storage (GCS). Der Kunde kann dank Cloud-Agnostic den Cloud-Anbieter wählen, den er nutzen möchte.
Rechenleistung/ Compute-Cluster:
Snowflake-Kunden können einen dedizierten Compute-Cluster, ein so genanntes „virtuelles Lager“, für Analysen einrichten. Die Architektur, die dahinter steht, wird als massive parallele Verarbeitung (MPP) bezeichnet, bei der der Compute-Cluster Abfragen in separate Unterabfragen auf den einzelnen Compute-Knoten aufteilt, von denen jeder einen Teil der verteilten Daten bearbeitet.
Snowflake speichert Daten in kleinen Datenblöcken, so genannten Mikropartitionen. Dies ermöglicht die schnelle Verarbeitung riesiger Datenmengen und eine Skalierung auf unglaublich große Datensätze mit mehreren Petabytes.
Cloud-Services:
Zu den angebotenen Diensten gehören eine API für die Verwaltung der Daten, Sicherheitsrollen, die gemeinsame Nutzung von Daten, ein Datenmarktplatz, Datentransaktionen und die Partitionierung von Metadaten (z. B. wie Datenfelder aufgeteilt werden).
Data Lakehouse Architektur von Databricks
Databricks bietet eine Plattform für Datenwissenschaft und -analyse. Das Kernprodukt ist eine Apache Spark Engine, die für die Ausführung fortgeschrittener Datenabfragen verwendet wird. Das Data Lakehouse kombiniert Elemente eines Data Warehouse mit einem Data Lake in einer zentralen Plattform. Es ist in der Lage, die Vorteile von Streaming Analytics, BI und maschinellem Lernen auf einer einzigen Plattform bereitzustellen.
Das Data Lakehouse basiert auf dem Open-Source-Framework Apache Spark, welches analytische Abfragen von semi-strukturierten Daten ohne traditionelles Datenbankschema ermöglicht.
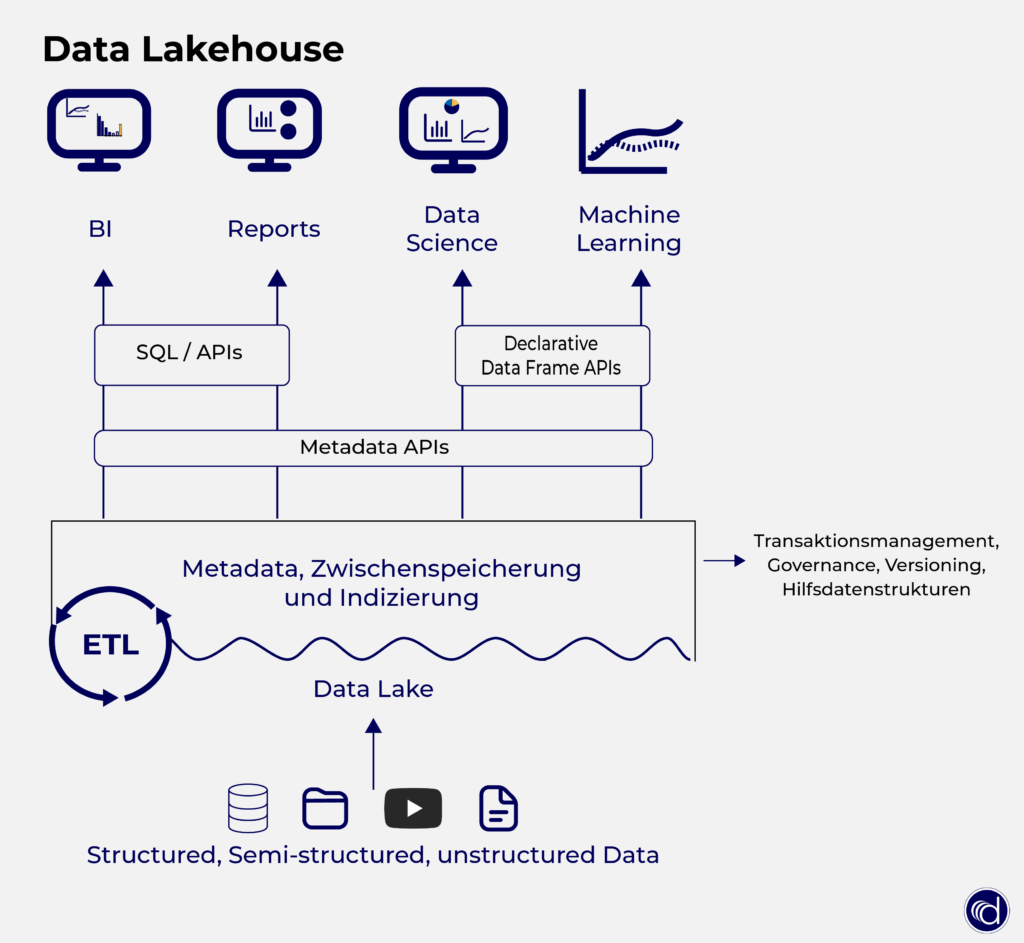
Der Vorteil, welcher sich aus der Kombination von Data Lake und Warehouse in einer Plattform ergibt: Datenteams können schneller mit den Daten arbeiten, ohne auf mehrere Systeme zugreifen zu müssen.
Das hilft den Teams wiederum, Probleme mit Datenduplizierung, zusätzlichen Betriebskosten und mehreren ETL-Prozessen, zu vermeiden.
Wir haben dem Thema Data Lakehouse einen kompletten Blogbeitrag gewidmet: Das Data Lakehouse.
Da wir uns die Architekturen der Cloud-Giganten angesehen haben, können wir nun in den Vergleich gehen.
Snowflake vs. Databricks: Die wichtigsten Unterschiede im Vergleich
Neben der Architektur der Datenmanagement-Systeme gibt es noch weitere Unterschiede zu berücksichtigen.
In der folgenden Tabelle sind die wichtigsten Unterschiede übersichtlich aufgelistet.
| Databricks „Data Lakehouse“ | Snowflake „Data-Cloud“ | |
| Service Model | PaaS | SaaS |
| Unterstützung wichtigster Cloud-Plattformen | Azure, AWS, Google | In Snowflake Cloud: Azure, AWS, Google |
| Migration auf Plattform | Komplex, da Data Lakehouse | Einfach, Design basiert auf Data Warehouse |
| Skalierbarkeit | Automatisch | Automatisch |
| Vendor Lock-In? | Nein | Ja |
| Benutzerfreundlichkeit | Lernkurve | Intuitiv |
| Kosten | Je nach Gebrauch | Je nach Gebrauch |
| Data Strukturen | Alle Datentypen | Semi-strukturiert, strukturiert |
| Dateiformate | Delta | Apache Iceberg |
| Support für ML-Anwendungen | Stark | Begrenzt |
| Streaming Fähigkeit | Stark | Schwach |
| Unterstützte Programmiersprachen | Scala, Python, R, SQL | Java, Scala, SQL, Python (Snowpark Dataframes) |
Gehen wir in den Tiefenvergleich.
Welches System ist offener?
Databricks ist mit seinem Open-Source Ansatz basierend auf dem Delta Lake deutlich offener als Snowflake mit Tenant. Die Plattform basiert auf drei zentralen Open-Source-Systemen (Apache Spark, Delta Lake und MLflow) und unterstützt verschiedene Programmiersprachen, wie SQL, Python, Java und R. Da es sich um eine Betriebssystemtechnologie handelt, steht die Plattform jedem Unternehmen zur Verfügung.
Wir sind offizieller Databricks Partner und beraten Sie gerne.
Snowflake hingegen folgt dem traditionellen Enterprise Data Warehouse (ähnlich wie früher Oracle). Daten können in Snowflake nur durch die Snowflake-Abfrage-Engine abgerufen werden. Snowflake ist somit ein eher geschlossenes System, was diverse Nachteile im Datenimport und -export mit sich bringt.
Offen bedeutet aber je nach Use Case nicht unbedingt besser:
Offene Systeme bieten Transparenz und sind konfigurierbar, da der Quellcode verfügbar ist und manipuliert werden kann. Ein geschlossenes System hingegen verbirgt die innere Funktionsweise des Systems. Auch wenn es an Transparenz mangelt, ist das Produkt in der Regel so vorkonfiguriert, dass die Betreiber es sofort nutzen können, ohne sich um die Verwaltung der Infrastruktur oder die Auswahl der Konfiguration kümmern zu müssen.
Außerdem sind die Entwickler eines geschlossenen Systems oft flexibler, wenn es darum geht, Änderungen an der internen Funktionsweise des Systems vorzunehmen, da sie sich nicht mit der Kompatibilität zu offenen Schnittstellen oder dem Community-Management auseinandersetzen müssen.
Datengröße
Stellen Sie sich zunächst die Frage, wie groß Ihre Daten eigentlich sind. Sowohl Databricks als auch Snowflake sind in der Lage, Big Data zu handhaben. Jedoch gibt es eher wenige Use Cases, die belegen, dass Snowflake Big Data problemlos verarbeitet.
Support und Benutzerfreundlichkeit
Die Snowflake Data Cloud gilt als benutzerfreundlich und verfügt über eine intuitive SQL-Schnittstelle, die die Einrichtung und den Betrieb erleichtert. Außerdem verfügt es über zahlreiche Automatisierungsfunktionen, die die Nutzung erleichtern. Auto-Scaling und Auto-Suspend helfen zum Beispiel beim Stoppen und Starten von Clustern während Leerlauf- oder Spitzenzeiten. Die Größe von Clustern kann einfach geändert werden.
Allerdings bietet die Data Cloud weniger Support für Machine Learning Workloads. Snowflakes Data Cloud bietet zunächst nur die Möglichkeit mit SQL zu arbeiten, ermöglicht aber heute durch Snowpark Dataframes auch die Zusammenarbeit mit Python. Die Supportmöglichkeit von Streaming ist mit einer Latenz >1 ebenfalls eher schwach.
Auch Databricks verfügt über eine automatische Skalierung von Clustern, ist aber nicht so benutzerfreundlich. Die Benutzeroberfläche ist komplexer, da sie sich an ein technisches Publikum richtet. Sie erfordert mehr manuelle Eingaben, wenn es um Dinge wie die Größenänderung von Clustern, die Aktualisierung von Konfigurationen oder das Umschalten von Optionen geht. Dafür ist das Data Lakehouse bestens geeignet für den Support von Machine Learning Workloads.
Streaming Fähigkeit
Databricks hat die Nase vorn, wenn es um Real-Time Streaming Anwendungen geht und verfügt mit Auto-Loader und Delta Live Tables Funktionalitäten um Streaming Anwendungen für Entwickler zu vereinfachen.
Sicherheit
Snowflake und Databricks bieten beide rollenbasierte Zugriffskontrolle (RBAC) und automatische Verschlüsselung. Snowflake fügt Netzwerkisolierung und andere robuste Sicherheitsfunktionen in mehreren Stufen hinzu, wobei jede höhere Stufe mehr kostet. Der Vorteil ist jedoch, dass Sie nicht für Sicherheitsfunktionen bezahlen müssen, die Sie nicht brauchen oder wollen.
Mit dem Unity Catalog von Databricks gibt es die derzeit beste Data Governance Lösung auf Enterprise Niveau. Snowflake hat aktuell keine vergleichbar gute Lösung.
Auch Databricks verfügt über viele wertvolle Sicherheitsfunktionen. Beide erfüllen die Anforderungen von SOC 2 Typ II, ISO 27001, HIPAA, GDPR und mehr.
Integration
Snowflake findet sich auf dem AWS-Marktplace wieder, ist aber nicht tief in das AWS-Ökosystem eingebettet. Die Integration der Data-Cloud kann zu Herausforderungen führen, funktioniert aber problemlos mit beispielsweise Apache Spark, IBM Cognos, Tableau und Qlik. Databricks Data Lakehouse ist jedoch vielseitiger in Bezug auf die Unterstützung beliebiger Datenformate (einschließlich unstrukturierter Daten).
Kosten
Da es sich bei Databricks und Snowflake um Cloud-Dienste handelt, hängen die Kosten von der Nutzungsintensität ab. Bei Databricks ergeben sich die Kosten aus dem Server und den so genannten Databricks Units (DBUs). Die Anzahl der DBUs ist dabei abhängig von der Server- und Clustergröße sowie der genutzten Laufzeit.
Kosten Databricks= (Anzahl Server*DBU)*h/Nutzung + (Anzahl Server*Instanzenpreise)*h/Nutzung
Sie möchten Ihre Ausgaben bei Databricks kontrollieren? Dann sind Sie bei unserem Blogbeitrag „Databricks Kostenoptimierung“ richtig!
Das Preismodell von Snowflake umfasst die beiden Hauptteile Direktspeicher und Rechenressourcen. Für virtuelle Warehouses zahlen Kunden mit den so genannten Snowflake Credits. Gerade für ETL Prozesse ist Databricks deutlich günstiger und in diversen Benchmarks bis zu 50-70% günstiger im Vergleich zu Snowflake.
Snowflake wurde eher als klassisches Data Warehouse in der Cloud konzipiert und ist mit der Zeit und Anforderungen gewachsen.
Generative KI: Wer kann es besser?
Beide Plattformen haben in den vergangenen Monaten erhebliche Fortschritte im Bereich Künstliche Intelligenz (KI) gemacht und erweitern kontinuierlich ihre Funktionen für Generative AI (GenAI). Dabei unterscheiden sich Snowflake und Databricks vor allem in ihrem technologischen Ansatz und der Zielgruppe, für die sie optimiert sind. Sehen wir uns das im Einzelnen an:
Databricks
Databricks verfolgt einen klaren Fokus auf den gesamten Machine-Learning-Lebenszyklus – von der Datenaufbereitung über Modelltraining bis zur Bereitstellung von Large Language Models (LLMs). Als Unified Analytics Platform kombiniert Databricks Data Engineering, Data Science und MLOps in einer Cloud-nativen Umgebung.
Durch die Integration von MLflow wird der komplette ML-Lifecycle – inklusive Experiment-Tracking, Reproduzierbarkeit und Modell-Governance – zentral abgebildet. Damit ist Databricks besonders stark auf die produktive Nutzung und Anpassung von Foundation Models ausgerichtet. Unternehmen können LLMs gezielt feinabstimmen, um domänenspezifische Use Cases zu realisieren, ohne die Kontrolle über ihre Daten oder Sicherheitsrichtlinien zu verlieren.
Als Databricks Technologiepartner unterstützen wir Sie bei Ihren Databricks Projekten: Kontaktieren Sie uns jetzt.
Ergänzend dazu ermöglicht die Funktion AI/BI Genie interaktive Chat-Erlebnisse auf Unternehmensebene: Anwender können über eine Chat-Oberfläche oder API natürliche Sprache nutzen, um Daten zu explorieren, Analysen zu starten oder Prognosen zu generieren.
Mit dem AI Playground und den Agentic-Fähigkeiten eröffnet Databricks zudem neue Wege für die Entwicklung intelligenter, automatisierter Workflows. Damit ist Databricks die derzeit umfassendste Plattform, wenn es um den praktischen Einsatz von Generativer KI in Verbindung mit Unternehmensdaten geht.
Snowflake
Snowflake verfolgt einen anderen Ansatz: Die Plattform dient in erster Linie als skalierbare, sichere und Multi-Cloud-fähige Datenbasis für KI-Anwendungen. Mit der Einführung von Snowflake Cortex hat Snowflake ebenfalls generative KI-Funktionen integriert – unter anderem für Natural Language to SQL, Dokumentensuche (Cortex Search) und Agentensteuerung (Cortex Agents).
Diese Bausteine lassen sich flexibel kombinieren, um KI-Funktionalitäten in Anwendungen einzubetten oder einfache Chat-Interfaces mit Streamlit zu entwickeln. Snowflake legt den Schwerpunkt dabei stärker auf die Integration und Orchestrierung bestehender KI-Funktionen als auf das Training oder Fine-Tuning eigener Modelle.
Die Plattform fungiert somit als robuste Datengrundlage für KI- und Analytics-Workloads, nicht primär als Entwicklungsumgebung für generative Modelle.
Kurz und knapp:
Während Snowflake vor allem als zuverlässige und sichere Datenbasis für KI-getriebene Analysen überzeugt, bietet Databricks eine End-to-End-Plattform für die Entwicklung, Anpassung und Operationalisierung von Generativer KI. Wer also auf LLM-Feinabstimmung, Agentic Workflows und integrierte MLOps-Prozesse setzt, findet in Databricks die umfassendere Lösung. Snowflake hingegen bleibt stark für Unternehmen, die generative Funktionen in bestehende BI- und Analyseprozesse einbetten möchten, ohne selbst tief in das ML- oder Modelltraining einzusteigen.
Herausforderungen von Snowflake
Wir sprechen mit vielen Kunden, die gerade bei steigenden Datenmengen über exponentielles Kostenwachstum der ETL-Workloads in Snowflake sprechen. Dies liegt primär daran, dass Snowflake nicht als ETL Tool entwickelt wurde, sondern seine Stärken als Serving-Layer von BI-Tools hat. Wir haben einmal die gängigen Herausforderungen von Snowflake zusammengefasst, die wir in der Praxis sehen:
Hohe ETL-Kosten
- Hohe Kosten für die Verarbeitung schwererer ETL-Workloads
- Geringe Transparenz bei der Kostenaufteilung – ETL, Ingress/Egress, BI, andere
Daten-Lock-in
- Geschlossene statt offene Architektur schränkt die Wahlmöglichkeiten ein
- Innovation außerhalb des Data Warehouses (z.B. Spark) ausgeschlossen
- Kostenpflichtiges Auslagern von Daten aus Snowflake zur Nutzung in anderen Systemen
Doppelte Speicherung
- Aufblähende Cloud-Speicherkosten
- Kein „Single Source of Truth“
- Hohe Ingress/Egress-Computekosten
Fehlende Tools für Data Science
- Data Scientists extrahieren Daten, um Modelle woanders zu entwickeln
- Ineffizienzen durch 2 Plattformen kostet Data Scientisten viel Zeit und mindert deren Produktivität
- Hohe Kosten um Data Science Feature einzukaufen durch weitere Tools
Fazit: Wer gewinnt das Rennen um das Top Datenmanagement-System?
Snowflake und Databricks sind beide ausgezeichnete Datenplattformen für Analysezwecke. Sowohl das Data Lakehouse als auch die Data Cloud haben ihre jeweiligen Vor- und Nachteile. Die Wahl der besten Plattform für Ihr Unternehmen hängt von den deswegen vor allem von den Nutzungsmustern, Datenmengen, Arbeitslasten und Datenstrategien ab.
Wir empfehlen Snowflakes Data-Cloud für die Standard-Datentransformationen und -analysen. Es eignet sich außerdem für Benutzer, die mit SQL vertraut sind. Databricks Data Lakehouse eignet besonders für Streaming, Machine Learning und für erfahrene Data Analysten. Snowflake hat bei den Sprachen aufgeholt und kürzlich Unterstützung für Python, Java und Scala hinzugefügt.
Wir denken, dass Databricks bei einem technischen Publikum mit Spark-Erfahrung, und Unternehmen mit großen Datenmengen sowie Machine Learning-Fokus, das Rennen macht. Snowflake ist für technische und weniger technische Benutzer leicht zugänglich. Databricks bietet so ziemlich alle von Snowflake angebotenen Datenverwaltungsfunktionen und noch mehr. Dafür ist die Plattform des Data Lakehouse nicht einfach zu bedienen, hat eine steile Lernkurve, erfordert mehr technisches Know-How und ein größeres Team für den Betrieb.
Sie finden das Thema interessant und möchten gerne mehr erfahren? Kontaktieren Sie uns!

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte