


Dass dem maschinellen Lernen die Zukunft gehört, dürfte mittlerweile unbestritten sein. Mit der wachsenden Komplexität der anfallenden Aufgaben und den sich ständig weiterentwickelnden Lösungsansätzen sind im Laufe der Zeit eine Reihe von Lernmethoden entstanden, die im Umfeld des Machine Learning (ML) zur Anwendung kommen. Reinforcement Learning (RL) ist dabei einer der interessantesten und aussichtsreichsten Ansätze.
Steigen wir direkt ein.
Was ist Reinforcement Learning?
Reinforcement Learning (deutsch bestärkendes Lernen oder verstärkendes Lernen) steht für eine Methode des maschinellen Lernens, wo ein Agent eigenständig eine Strategie erlernt, um die erhaltene Belohnung anhand einer Belohnungs-Funktion zu maximieren. Der Agent hat eigenständig erlernt, in welcher Situation, welche Aktion die beste ist. Natürlich kann die Belohnung auch negativ sein, wenn der Agent eine Aktion wählt, die nicht der Belohnungs-Funktion entspricht. Die Belohnungs-Funktion (oder auch Nutzenfunktion) beschreibt, welchen Wert ein bestimmter Zustand oder Aktion hat.
Anders als bei überwachtem Lernen (Supervised Learning) sind bei RL im Vorfeld keine Daten erforderlich. Stattdessen erfolgt die Bildung der Datenbasis durch ausführliche Trial-and-Error-Abläufe innerhalb eines eigens angelegten Simulations-Szenarios. Während der Trainingsdurchläufe werden alle erforderlichen Daten generiert und markiert.
Überraschenderweise sind die Anwendungsgebiete für diese fortgeschrittene KI-Technik erstaunlich praxisnah: So wird Reinforcement Learning bspw. genutzt, um Ampelschaltungen zu optimieren. Zudem findet es Anwendung in einem Bieterverfahren für Displaywerbung bei dem chinesischen Internet-Riesen Alibaba Group.
Wichtige Begriffe im Reinforcement Learning
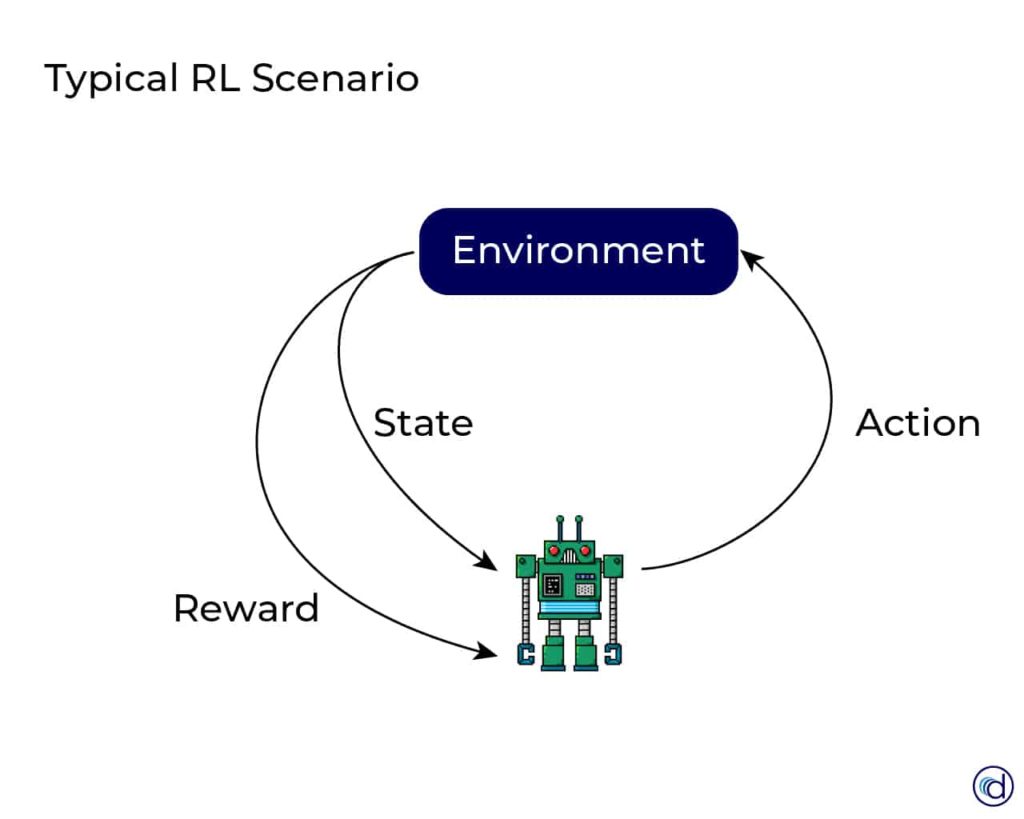
Hier sind die wichtigsten Begriffe für bestärkendes Lernen:
- Agent: Der Agent muss die Aktionen in einem Szenario / Umfeld ausführen und bekommt dafür eine Belohnung (Reward).
- Environment (e): Das Simulations-Szenarios, dass der Agent erkunden muss.
- Reward (R): Ein unmittelbares Feedback zu einer ausgeführten Aktion oder Aufgabe..
- State (s): Aktuelle Situation in der sich die Umgebung befindet.
- Policy (π): Die Strategie, die der Agent ausführt und über die nächste Aktion entscheidet.
- Value (V): Ist der langfristige Mehrwert (Value) im Vergleich zum kurzfristigen Mehrwert.
- Value Function: Die Belohnungs-Funktion oder Nutzenfunktion (reward function) legt den Wert für eine Belohnung fest. Eine Belohnung für bestärkendes Lernen kann positiv als auch negativ sein.
- Model based methods: Ist eine Methode des bestärkenden Lernen, die auf einem modellbasierten Ansatz basiert.
- Q value: Q-Wert nimmt zusätzlich noch die aktuelle Situation mit in die Entscheidungsfindung.
Wie funktioniert Reinforcement Learning?
Lasst uns ein kurzes, einfaches Beispiel zu Reinforcement Learning ansehen.
Wir nehmen an, dass wir einer Katze einen neuen Trick beibringen wollen:
- Da die Katze weder Englisch noch eine andere menschliche Sprache versteht, können wir ihr nicht direkt sagen, was sie tun soll. Stattdessen verfolgen wir eine andere Strategie.
- Wir simulieren eine Situation und die Katze versucht, auf viele verschiedene Arten (Aktion) zu reagieren. Wenn die Reaktion der Katze der gewünschte Weg ist, werden wir ihr einen Fisch (Belohnung oder Reward) geben.
- Wenn die Katze öfter der gleichen Situation ausgesetzt ist, führt Sie eine ähnliche Aktion mit der Erwartung durch, mehr Belohnung (Futter) zu erhalten. Das Beschreibt unsere Belohnungsfunktion.
- Das ist Lernen aus positiven Erfahrungen: bestärkendes Lernen
- Gleichzeitig werden falsche Entscheidungen (Aktionen) bestraft und durch negative Erfahrungen belegt (kein Futter).
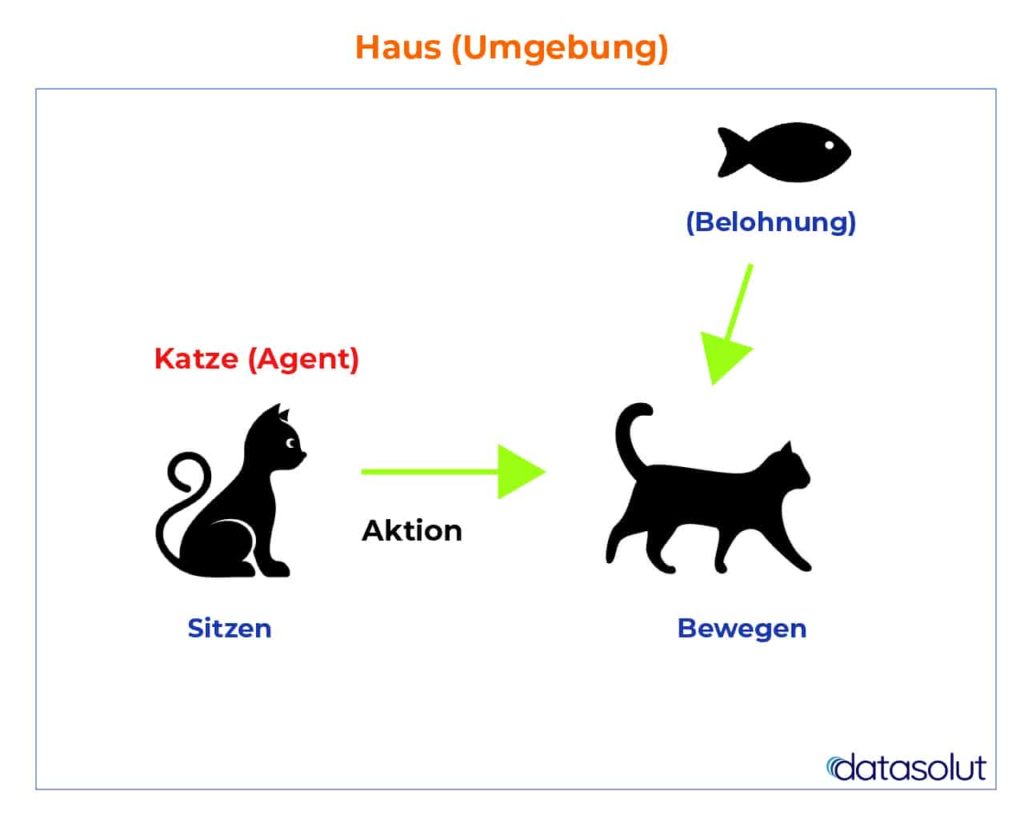
In unserem Beispiel,
- ist die Katze in der Umgebung (Simulations-Szenario) ausgesetzt. Zustände können z.B. sitzen oder bewegen sein.
- Unser Agent reagiert, indem er einen Aktionsübergang von einem „Zustand“ in einen anderen „Zustand“ durchführt.
- Zum Beispiel, wenn die Katze von Zustand „sitzen“ in Zustand „bewegen“ übergeht.
- Die Reaktion eines Agenten ist eine Aktion und die Richtlinie oder Strategie ist eine Methode zur Auswahl einer Aktion, die einem Zustand in Erwartung besserer Ergebnisse gegeben ist.
- Nach dem Übergang erhält die Katze im Gegenzug eine Belohnung oder Strafe.
Dieses recht einfache Beispiel verdeutlicht grundlegend wie Reinforcement Learning funktioniert.
Auf dem Weg zur Allgemeinen Künstlichen Intelligenz
Reinforcement Learning ist einer der aussichtsreichsten Wege hin zum heiligen Gral der KI-Forschung, der Allgemeinen Künstlichen Intelligenz (AKI). Während herkömmliche KI-Systeme auf die Bewältigung bestimmter Probleme oder Themenkreise ausgelegt sind, ist AKI in der Lage, für die unterschiedlichsten Aufgabenstellungen eigenständig Lösungsansätze zu finden und in Anwendung zu bringen.
RL bringt auf dem Gebiet der Steuerungstechnik bereits einige Voraussetzungen für AKI mit. Im Gegensatz zu üblichen Verfahren lassen sich mit den Mitteln des bestärkenden Lernens erheblich schnellere und effektivere Methoden entwickeln, die darüber hinaus auch zu besseren Ergebnissen führen können.
Die Erwartungen der KI-Experten an das Reinforcement Learning auf dem Weg zur Allgemeinen Künstlichen Intelligenz sind daher sehr hoch.
Allgemeine Künstliche Intelligenz – und damit auch Reinforcement Learning – bilden also die ursprünglich menschliche Befähigung ab, auf beliebige intellektuelle Aufgabenstellungen verschiedene Lösungsansätze zu erarbeiten. RL muss sich daher selbst ermächtigen, unterschiedliche Zusammenhänge zwischen Ursache und Wirkung eigenständig auszumachen und daraus Lösungsansätze zu entwickeln. Auf diese Weise wird es für die Maschine möglich, Probleme zu lösen, die in ihrem Wahrnehmungsbereich bisher noch nicht aufgetaucht sind.
RL als darwinistischer Prozess
Das Basisverfahren des bestärkenden Lernens ist – wie erwähnt – die Trial-and-Error-Methode, und das so, wie sie in der Natur vorkommt, beispielsweise bei evolutionären Prozessen, die zur Entwicklung der Arten nach Darwin geführt haben. Damit schlägt RL die Brücke zur Biologie und den Neurowissenschaften. Andere Elemente des Reinforcement Learnings bilden Verknüpfungen zu Verfahren der Psychologie.
Im Detail setzt sich RL aus einer Reihe einzelner Methoden zusammen. Mit ihrer Hilfe erlernt ein so genannter Software-Agent eigenständig Strategien, die zur Problemlösung führen. Das gesamte Verfahren setzt auf einem Belohnungssystem auf, das innerhalb der Testumgebung erfolgreiche Versuche honoriert.
Vorallem DeepMind von Google befasst sich damit.

Der Agent erhält nach jeder seiner Aktionen ein Feedback und kann daraus seinen Erfolg oder seine Erfolglosigkeit ableiten. Da die Belohnung nur nach einem erfolgreichen Durchlauf gewährt wird und der Agent versucht, ein Maximum an Belohnungen zu erhalten, gewinnen auf längere Frist die erfolgreichen Testdurchläufe die Oberhand.
Die Besonderheit beim Reinforcement Learning: Der Agent erhält zuvor kein Briefing. Das System wird also nicht mit geeigneten Verfahren zur Problemlösung versorgt. Alle Verfahren und Methoden, die zum erfolgreichen Abschluss führen, muss der Agent selbst entwickeln. Dies wird alleine durch das Belohnungssystem gesteuert, das ihm zeigt, ob er auf dem richtigen Weg ist. Auf diese Weise entstehen langfristige Strategien, um Steuerungsprozesse zu optimieren.
Die bestmögliche Policy als strategisches Ziel
Das erlernte Verhalten des Agenten – die Policy – stellt das Ergebnis des Lernprozesses dar. Die Policy beschreibt, welche Aktion bei einer beliebigen Verhaltensvariante innerhalb der Lernumgebung zur höchstmöglichen Belohnung führt – und damit zur bestmöglichen Problemlösung.
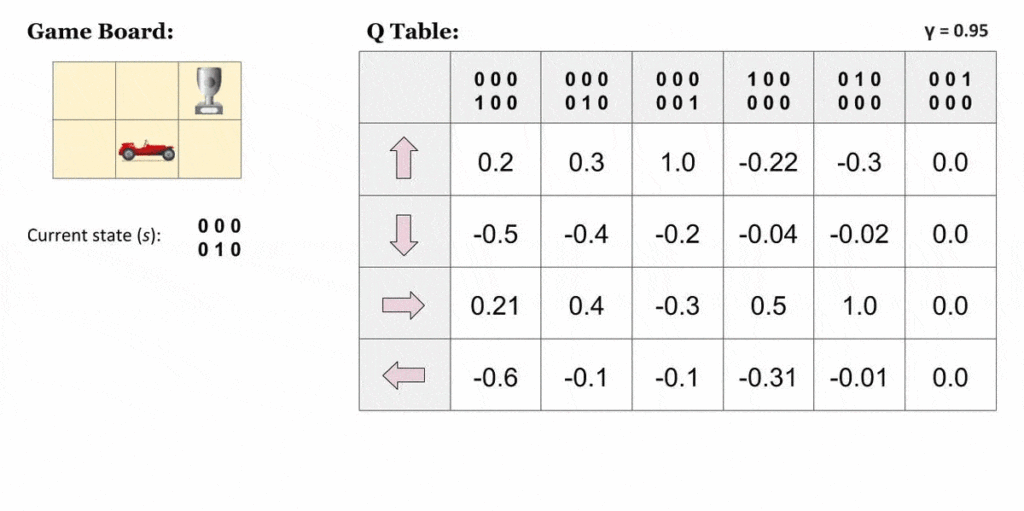
Ein Weg, derartige Policies abzubilden, ist die Q-Table. Die Tabelle visualisiert die Beobachtungen als Zeilen und die Aktionen als Spalten. Während des Trainings erhalten die Zellen der Tabelle die jeweiligen Belohnungswerte, die in der entsprechenden Situation zu erwarten sind.
Allerdings sind Q-Tables nur in begrenztem Umfang einsetzbar, nämlich dann, wenn die Zahl der Beobachtungen und Aktionen im überschaubaren Rahmen bleibt. Bei hohen Datenmengen, beispielsweise bei kontinuierlich zufließenden Werten, ist zur Abbildung der Werte ein neuronales Netz erforderlich. Das Verfahren, das hier in der Regel zur Anwendung kommt, ist Deep Q-Learning.
Innerhalb eines neuronalen Netzes fungieren die Beobachtungen als Input und die Aktionen als Output, jeweils als Schichten oder Layer abgebildet. Während des Lernprozesses werden die ermittelten Werte in die einzelnen Neuronen des Netzes eingelagert.
Reinforcement Learning vs. Supervised Learning
| Faktoren | Reinforcement Learning (Bestärkendes Lernen) | Supervised Learning (Überwachtes Lernen) |
| Entscheidungsstil | Reinforcement Learning hilft die Entscheidungen sequentiell zu treffen. | Supervised Learning trifft eine Entscheidung über die zu Beginn gegebene Eingabe getroffen. |
| Training | Wird in einer Umgebung trainiert und muss mit der Umgebung interagieren. | Wird auf Beispieldaten trainiert. |
| Abhängigkeiten | In RL-Methoden ist die Lernentscheidungen untereinander abhängig. Daher sollten alle abhängigen Entscheidungen mit entsprechenden Labels / Beispieldaten versehen sein. | Im Supervised learning sind die Entscheidungen unabhängig voneinander, daher werden die Labels für jede Enscheidung gegeben. |
| Beispiel | Schachspiel | Objekterkennung |
Per Reinforcement Learning zum besseren Verständnis von KI
Mittlerweile beschäftigen sich eine Reihe großer Unternehmen mit dem Thema Reinforcement Learning, darunter Global Player wie Tesla mit OpenAI, SpaceX und Google mit DeepMind. Sie alle haben ein gemeinsames Ziel: ein besseres Verständnis von künstlicher Intelligenz und – als herausragendes Ziel – die Entwicklung der Allgemeinen Künstlichen Intelligenz oder Artificial General Intelligence.
Was genau ist Artificial General Intelligence (AGI)?
AGI beschreibt die maschinelle Abbildung menschlicher Intelligenz mit dem Ziel, eine menschenähnliche Intelligenz innerhalb eines IT-Systems zu schaffen. Wie zu Beginn erwähnt, geht es darum, eine Maschinenintelligenz in die Lage zu versetzen, die unterschiedlichsten Aufgabenstellungen zu bewältigen, ohne dass der jeweilige Lösungsweg vorgegeben wird. Bisherige Systeme können nur scharf abgegrenzte, spezielle Aufgaben bewältigen.
Eine kurze Geschichte des Reinforcement Learning
Schon heute können KI-Systeme Aufgaben bewältigen, die über menschliche Fähigkeiten hinausgehen – das allerdings nur in spezialisierten Sparten. Erst die Betrachtung von Reinforcement Learning öffnete die Tür hin zur Allgemeinen Künstlichen Intelligenz. Diese Geschichte begann im Wesentlichen im Jahr 2013, als Google sein DeepMind-Projekt ins Leben rief.
Welche Bedeutung das Unternehmen dem Thema RL von Anfang an zumisst, lässt sich an der Größenordnung des Projekts bemessen. Über 360 Millionen Euro investierte Google in DeepMind. Dabei begann alles eher bescheiden, um nicht zu sagen lapidar: Zu Beginn beschäftigte sich das Projekt hauptsächlich mit der maschinellen Bewältigung von Atari-Spielen. Dabei ging es allerdings nicht nur darum, die erfolgreichsten Strategien ausfindig zu machen und das Spiel siegreich abzuschließen. Vielmehr musste das System auch die Spielregeln eigenständig erarbeiten – eine typische Reinforcement Learning-Anwendung.
Der endgültige Durchbruch gelang im Zusammenhang mit dem alten chinesischen Brettspiel Go. Aufgrund seiner Komplexität waren sich alle Computerexperten einig: Kein Computer kann beim Go gegen einen menschlichen Spieler gewinnen. Vor allem die unermessliche Anzahl an Spielvarianten – weit über die von Schach hinaus – sowie der starke intuitive Aspekt schien dem maschinellen Spielen einen unüberwindlichen Riegel vorzuschieben.
Dann kam AlphaGo, eine DeepMind-Entwicklung. Das System besiegte menschliche Spieler mit einer Leichtigkeit, die bisher unmöglich erschien. Und nicht nur das: Der Nachfolger, AlphaGo Zero, hat sich die Go-Regeln selbst beigebracht, ohne jedes menschliche Zutun.
AlphaGo Zero beruht auf Reinforcement Learning und demonstriert auf diese Weise, welches ungeheure Potenzial in diesem Verfahren des maschinellen Lernens steckt. Das System begann mit einer völlig zufälligen Spielweise, bei der nur die Anfangsposition der Steine vorgegeben war. Nach drei Tagen Training trat AlphaGo Zero gegen seinen Vorgänger AlphaGo an und schlug ihn vernichtend mit einem Ergebnis von 100 zu 0 gewonnenen Spielen.
Den nächsten Schritt stellt DeepMinds System AlphaStar dar, das sich mit Echtzeit-Strategiespielen beschäftigt. Im Januar 2019 war es soweit: AlphaStar schlug bei einem Starcraft 2-Turnier die E-Sport-Stars TLO und MaNa.

Der Sieg einer künstlichen Intelligenz bei Starcraft 2 geht nicht ausschließlich auf ein gut programmiertes System zurück. Hier hat eine Maschinenintelligenz zum ersten Mal in einer zeitkritischen Anwendung ohne Bedenkzeit Gegner intuitiv richtig eingeschätzt, ihre Spielweise analysiert und langfristige Strategien entwickelt. Fähigkeiten, über die viele Menschen nicht oder nur eingeschränkt verfügen.
Fazit
Reinforcement Learning ist auf dem Gebiet der künstlichen Intelligenz eine revolutionäre Entwicklung, die völlig neue Türen aufstößt. Überraschend ist vor allem die Geschwindigkeit, mit der sich mit Hilfe von RL Fortschritte erzielen lassen. Ob das Erreichen der Allgemeinen Künstlichen Intelligenz bereits kurz vor der Verwirklichung steht, ist allerdings umstritten. Unbestreitbar ist allerdings, dass bereits heute zahlreiche sinnvolle Anwendungen für Reinforcement Learning existieren, die gerade die Optimierung von Steuerungsprozessen radikal verbessern.







