


Künstliche Neuronale Netze (KNN) sind dem menschlichen Gehirn nachempfunden und werden für maschinelles Lernen und Künstliche Intelligenz eingesetzt. Computerbasiert lassen sich damit diverse Problemstellungen lösen, die für uns Menschen fast unmöglich wären. In diesem Artikel erkläre ich, wie künstliche neuronale Netze funktionieren, wie sie aufgebaut sind und wo sie eingesetzt werden.
Das Wichtigste auf einen Blick:
- Künstliche Neuronale Netze sind Algorithmen, die der Funktionsweise des menschlichen Gehirns nachempfunden sind.
- Mit Hilfe von Künstlichen Neuronalen Netzen können verschiedene komplexe Problemstellungen aus den Bereichen Statistik, Informatik und Wirtschaft gelöst werden.
- Der Aufbau eines Künstlichen Neuronalen Netzes besteht aus den Schichten: Eingabeschicht (Input Layer), verborgene Schicht (Hidden Layer) und Ausgabeschicht (Output Layer) zusammen.
- Künstliche Neuronale Netze spielen in vielen Bereichen eine wichtige Rolle. Dazu gehören autonomes Fahren, Frühwarnsysteme, Bilderkennung, Betrugserkennung, medizinische Analysen oder Wettervorhersagen.
- Es gibt verschiedene Arten von Künstlichen Neuronalen Netzen. Dazu gehören: Perceptron, Feed Forward Neural Networks, Convolutional Neural Networks, Recurrent Neural Networks.
Was ist ein Künstliches Neuronales Netzwerk?
Künstliche neuronale Netze sind Algorithmen, die dem menschlichen Gehirn nachempfunden sind. Dieses abstrahierte Modell miteinander verbundener künstlicher Neuronen ermöglicht es, komplexe Aufgaben aus den Bereichen Statistik, Informatik und Wirtschaft durch Computer zu lösen. Neuronale Netze sind ein sehr aktives Forschungsgebiet und gelten als Grundlage der künstlichen Intelligenz.
Neuronale Netze ermöglichen es, unterschiedliche Datenquellen wie Bilder, Töne, Texte, Tabellen oder Zeitreihen zu interpretieren und Informationen oder Muster zu extrahieren, um diese auf unbekannte Daten anzuwenden. Auf diese Weise können datenbasierte Vorhersagen für die Zukunft getroffen werden.
Künstliche neuronale Netze können unterschiedlich komplex aufgebaut sein, haben aber im Wesentlichen die Struktur gerichteter Graphen. Weist ein künstliches neuronales Netz besonders tiefe Netzstrukturen auf, spricht man von Deep Learning.
Zum Thema Künstliche Neuronale Netzwerke haben wir bereits ein Video:
Wie ist der Aufbau eines Künstlichen Neuronalen Netzwerks?
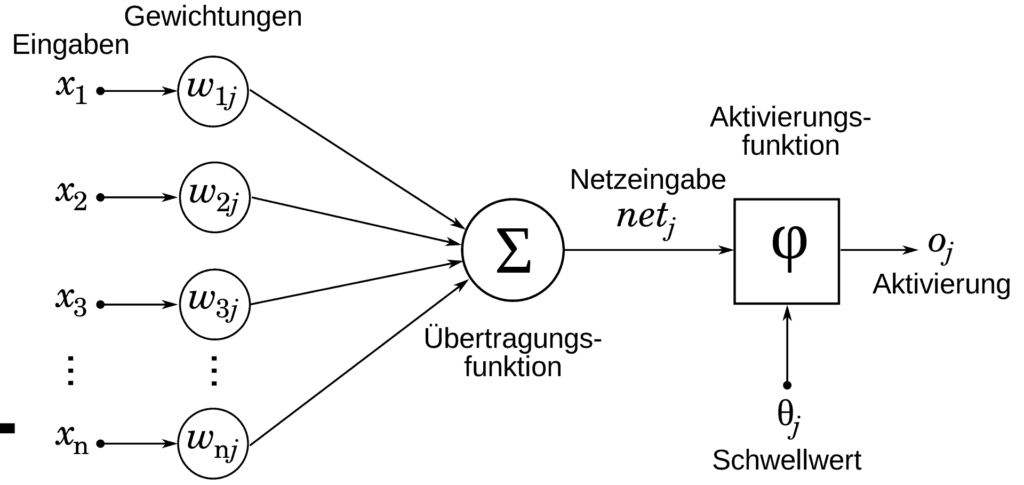
Vereinfacht kann man sich den Aufbau eines KNN wie folgt vorstellen: Das Modell des Neuronalen Netzes besteht aus Knoten, auch Neuronen genannt, die Informationen von anderen Neuronen oder von außen aufnehmen, modifizieren und als Ergebnis wieder ausgeben. Dies geschieht über drei verschiedene Schichten, denen jeweils ein Typ von Neuronen zugeordnet werden kann: solche für den Input (Eingabeschicht), solche für den Output (Ausgabeschicht) und so genannte Hidden Neuronen (verborgene Schichten).

Die Information wird durch die Input-Neuronen aufgenommen und durch die Output-Neuronen ausgegeben. Die Hidden-Neuronen liegen dazwischen und bilden innere Informationsmuster ab. Die Neuronen sind miteinander über sogenannte Kanten verbunden. Je stärker die Verbindung ist, desto größer die Einflussnahme auf das andere Neuron.
Schauen wir uns die Schichten einmal genauer an:
- Eingabeschicht: Die Eingangsschicht versorgt das neuronale Netz mit den notwendigen Informationen. Die Input-Neuronen verarbeiten die eingegebenen Daten und führen diese gewichtet an die nächste Schicht weiter.
- Verborgene Schicht: Die verborgene Schicht befindet sich zwischen der Eingabeschicht und der Ausgabeschicht. Während die Ein- und Ausgabeschicht lediglich aus einer Ebene bestehen, können beliebig viele Ebenen an Neuronen in der verborgenen Schicht vorhanden sein. Hier werden die empfangenen Informationen erneut gewichtet und von Neuron zu Neuron bis zur Ausgabeschicht weitergereicht. Die Gewichtung findet in jeder Ebene der verborgenen Schicht statt. Die genaue Prozessierung der Informationen ist jedoch nicht sichtbar. Daher stammt auch der Name, verborgene Schicht. Während in der Ein- und Ausgabeschicht die eingehenden und ausgehenden Daten sichtbar sind, ist der innere Bereich des Neuronalen Netzes im Prinzip eine Black Box.
- Ausgabeschicht: Die Ausgabeschicht ist die letzte Schicht und schließt unmittelbar an die letzte Ebene der verborgenen Schicht an. Die Output-Neuronen beinhalten die resultierende Entscheidung, die als Informationsfluss hervorgeht.
Wie funktioniert ein Künstliches Neuronales Netzwerk (KNN)?
Tiefes Lernen ist eine Hauptfunktion eines KNN und funktioniert wie folgt: Bei einer vorhandenen Netzstruktur bekommt jedes Neuron ein zufälliges Anfangsgewicht zugeteilt. Dann werden die Eingangsdaten in das Netz gegeben und von jedem Neuron mit seinem individuellen Gewicht gewichtet.
Das Ergebnis dieser Berechnung wird an die nächsten Neuronen der nächsten Schicht oder des nächsten Layers weitergegeben, man spricht auch von einer „Aktivierung der Neuronen“. Eine Berechnung des Gesamtergebnis geschieht am Outputlayer.
Natürlich sind, wie bei jedem maschinellen Lernverfahren, nicht alle Ergebnisse (Outputs) korrekt und es treten Fehler auf. Diese Fehler sind berechenbar, ebenso wie der Anteil eines einzelnen Neurons am Fehler. Im nächsten Lerndurchgang wird das Gewicht jedes Neurons so verändert, dass der Fehler minimiert wird.
Im nächsten Durchlauf wird der Fehler erneut gemessen und angepasst. Auf diese Weise „lernt“ das neuronale Netz von Mal zu Mal besser, von den Eingabedaten auf bekannte Ausgabedaten zu schließen.
Dieser Prozess ist dem menschlichen Entscheidungsprozess sehr ähnlich. Die Denkweise des Menschen ist ähnlich verschachtelt wie die eines neuronalen Netzes.
Welche Anwendungen gibt es?
Wo finden denn nun solche Netzwerke Anwendungen? Nun, da gibt es zahlreiche Möglichkeiten. Typischerweise sind sie prädestiniert für solche Bereiche, bei denen wenig systematisches Wissen vorliegt, aber eine große Menge unpräziser Eingabeinformationen (unstrukturierte Daten) verarbeitet werden müssen, um ein konkretes Ergebnis zu erhalten. Das kann zum Beispiel in der Spracherkennung, Mustererkennung, Gesichtserkennung oder Bilderkennung der Fall sein. Weitere Anwendungsfälle für neuronale Netze sind:
- Steuerung von komplexen Systemen
- autonomes Fahren
- Frühwarnsysteme (Raumfahrt, Luftfahrt, Verteidigung)
- Waffensysteme
- verstehen von natürlicher Sprache
- deuten von natürlicher Sprache
- Empfehlungssysteme im E-Commerce
- Betrugserkennung
- Bilderkennung
- Forecasting von Absatz- oder Umsatz
- Erzeugen von Stimmen
- Übersetzung von Sprache
- Wettervorhersagen
- Wirtschaftssysteme
- Zeitreihenprognosen
- Vorhersage von Kundenverhalten
- Medizinische Systeme (Krankheitsanalysen)
- Biometrische Systeme
- und viele weitere
Zahlreiche Produkte und Dienstleistungen, die auf künstlichen neuronalen Netzen basieren, haben bereits Einzug in unseren Alltag gehalten. Global agierende Konzerne wie Google, Facebook oder auch Amazon sind hier wichtige Vertreter und gelten mitunter als Vorreiter in der Entwicklung und Anwendung von Deep Learning und künstlicher Intelligenz.
Neuronale Netze bilden die Grundlage der Künstlichen Intelligenz und sind bereits heute in der Lage, durch gezieltes Training sehr spezifische Aufgaben zu übernehmen (schwache Künstliche Intelligenz).
Welche Arten von Künstlichen Neuronalen Netzen bestehen?
Es gibt unzählig viele Typen von neuronalen Netzwerk-Architekturen. Wir zeigen hier die wichtigsten Arten von neuronalen Netzen:
Perceptron
Das einfachste und älteste neuronale Netz. Es nimmt die Eingabeparameter, addiert diese, wendet die Aktivierungsfunktion an und schickt das Ergebnis an die Ausgabeschicht. Das Ergebnis ist binär, also entweder 0 oder 1 und damit vergleichbar mit einer Ja- oder Nein-Entscheidung. Die Entscheidung erfolgt, indem man den Wert der Aktivierungsfunktion mit einem Schwellwert vergleicht.
Bei Überschreitung des Schwellwertes, wird dem Ergebnis eine 1 zugeordnet, hingegen 0 wenn der Schwellwert unterschritten wird. Darauf aufbauend wurden weitere Neuronale Netzwerke und Aktivierungsfunktionen entwickelt, die es auch ermöglichen mehrere Ausgaben mit Werten zwischen 0 und 1 zu erhalten. Am bekanntesten ist die Sigmoid-Funktion, in dem Fall spricht man auch von Sigmoid-Neuronen.
Feed forward neural networks
Der Ursprung dieser neuronalen Netze liegt in den 1950 Jahren. Sie zeichnen sich dadurch aus, dass die Schichten lediglich mit der nächst höheren Schicht verbunden sind. Es gibt keine zurückgerichteten Kanten. Der Trainingsprozess eines Feed Forward Neural Network (FF) läuft dann in der Regel so ab:
- alle Knoten sind verbunden
- Aktivierung läuft von Eingangs- zu Ausgangsschicht
- mindestens eine Schicht (Layer) zwischen Eingangs- und Ausgangsschicht
Wenn besonders viele Schichten zwischen Eingangs- und Ausgangsschicht sind, spricht man von Deep Feed Forward Neural Networks„
Convolutional Neural Networks (CNN)
Faltende Neuronale Netze oder auch Convolutional Neural Networks (CNN), sind Künstliche Neuronale Netzwerke, die besonders effizient mit 2D- oder 3D-Eingabedaten arbeiten können. Für die Objektdetektion in Bildern verwendet man insbesondere CNNs.
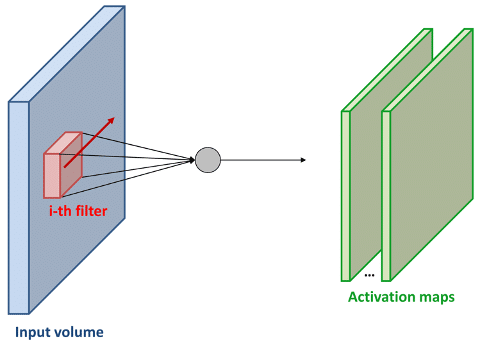
Der große Unterschied zu den klassischen neuronalen Netzen liegt in der Architektur der CNNs, die auch den Namen „Convolution“ oder „Faltung“ erklärt. Bei CNNs basiert die verborgene Schicht auf einer Abfolge von Faltungs- und Poolingoperationen. Bei der Faltung wird ein sogenannter Kernel über die Daten geschoben und währenddessen eine Faltung berechnet, was mit einer Multiplikation vergleichbar ist. Die Neuronen werden aktualisiert. Die anschließende Einführung einer Pooling-Schicht sorgt für eine Vereinfachung der Ergebnisse. Nur die wichtigen Informationen bleiben erhalten.
Dies sorgt auch dafür, dass die 2D- oder 3D-Eingangsdaten kleiner werden. Setzt man diesen Prozess fort, so erhält man am Ende in der Ausgabeschicht einen Vektor, den „fully connected layer“. Dieser hat vor allem in der Klassifikation eine besondere Bedeutung, da er ebenso viele Neuronen wie Klassen enthält und die entsprechende Zuordnung über eine Wahrscheinlichkeit bewertet.
Recurrent Neural Networks (RNN)
Recurrent Neural Networks (RNN) fügen den KNN wiederkehrende Zellen hinzu, wodurch neuronale Netze ein Gedächtnis erhalten. Das erste künstliche, neuronale Netzwerk dieser Art war das Jordan-Netzwerk, bei dem jede versteckte Zelle ihre eigene Ausgabe mit fester Verzögerung – eine oder mehrere Iterationen – erhielt. Ansonsten ist es vergleichbar mit den klassischen Feed Forward Netzen.
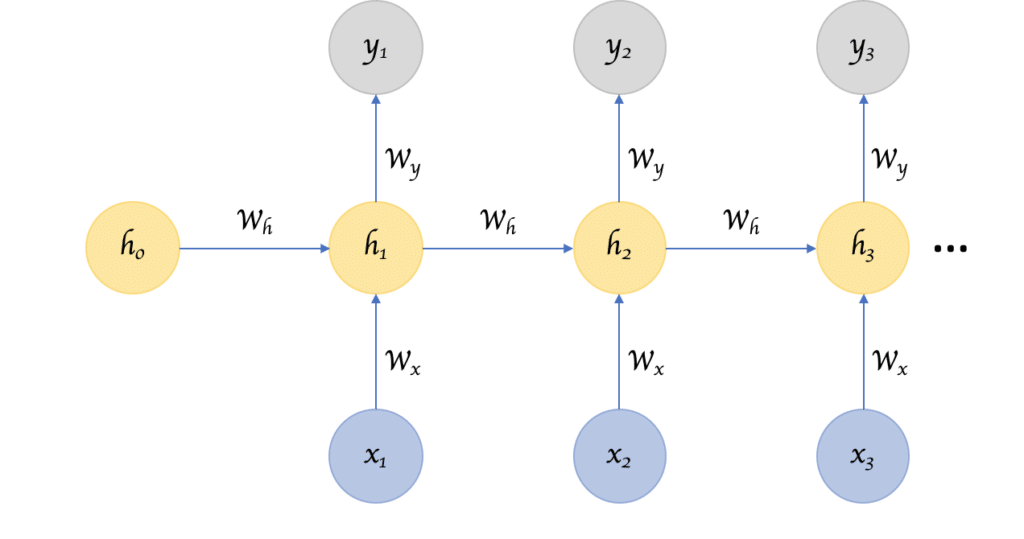
Natürlich gibt es viele Variationen, wie z.B. die Übergabe des Status an die Eingangsknoten, variable Verzögerungen usw., aber die Grundidee bleibt die gleiche. Diese Art von NN wird insbesondere dann verwendet, wenn der Kontext wichtig ist. In diesem Fall haben Entscheidungen aus früheren Iterationen oder Stichproben einen signifikanten Einfluss auf die aktuellen Iterationen. Da rekurrente Netze jedoch den entscheidenden Nachteil haben, dass sie mit der Zeit instabil werden, ist es mittlerweile üblich, sogenannte Long Short-Term Memory Units (kurz: LSTMs) zu verwenden. Diese stabilisieren das RNN auch für Abhängigkeiten, die über einen längeren Zeitraum bestehen.
Das häufigste Beispiel für solche Abhängigkeiten ist die Textverarbeitung – ein Wort kann nur im Zusammenhang mit vorhergehenden Wörtern oder Sätzen analysiert werden. Ein weiteres Beispiel ist die Verarbeitung von Videos, z.B. beim autonomen Fahren. Objekte in Bildsequenzen werden erkannt und über die Zeit verfolgt.
Weitere Quellen:
http://neuralnetworksanddeeplearning.com/
Fazit
Künstliche neuronale Netze ähneln der Funktionsweise des menschlichen Gehirns und eignen sich daher hervorragend für alle Bereiche des maschinellen Lernens und der künstlichen Intelligenz. Daraus ergibt sich für Unternehmen eine Vielzahl von Möglichkeiten, die Effizienz ihres Unternehmens zu steigern.
Aufgrund der vielen Vorteile von künstlichen neuronalen Netzen können viele komplexe Probleme in den Bereichen Statistik, Informatik und Wirtschaft von Computern gelöst werden. Profitieren auch Sie von diesen Vorteilen!
Möchten auch Sie die Vorteile Künstlicher Neuronaler Netze nutzen oder haben Sie weitere Fragen zu diesem Thema? Kontaktieren Sie mich gerne.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte




