


Natural Language Processing (NLP) ist eine Methode der künstlichen Intelligenz, die es Computern ermöglicht, die natürliche Sprache des Menschen zu verstehen. Anwendungsgebiete sind z.B. Chatbots, Text Mining und digitale Assistenten wie Alexa oder Siri.
Die Verarbeitung natürlicher Sprache ist keine einfache Aufgabe des maschinellen Lernens, da Sprachen und Zusammenhänge oft komplex und aufgrund ihrer Mehrdeutigkeit für Computer nicht leicht zu verstehen sind.
Dieser Artikel gibt eine Einführung in die Verarbeitung natürlicher Sprache und zeigt, wo sie eingesetzt werden kann.
Das Wichtigste auf einen Blick:
- Natural Language Processing ist ein Zweig der künstlichen Intelligenz und beschäftigt sich mit der Analyse, dem Verständnis und der Generierung von natürlicher Sprache
- Zu den Funktionen zählen unter anderem die Sentiment-Analyse, Part of Speech-Tagging, Named-entity recognition und Spracherkennung
- Neben Natural Language Processing existieren ebenfalls die Bereiche Natural Language Understanding (NLU) und Natural Language Generation (NLG)
- NLP hilft Krankheiten zu identifizieren, den Kundenservice zu verbessern oder Texte zu klassifizieren
- Zudem stellen Spam-Filter, Textverarbeitung, Text Mining, Anrufweiterleitung mittels IVR-Systeme und E-Mail-Routing weitere Aufgabengebiete von NLP dar
Was ist Natural Language Processing?
Natural Language Processing (NLP), im deutschen Sprachgebrauch auch als Computerlinguistik oder linguistische Datenverarbeitung benannt, ist ein Zweig der künstlichen Intelligenz und des maschinellen Lernens, der sich mit der Analyse, dem Verständnis und der Generierung von Wörtern und Sätzen (natürlicher Sprache) beschäftigt. Durch Natural Language Processing können wir Menschen mit den Computern auf natürliche Weise kommunizieren, sodass diese unsere menschliche Sprache verstehen.
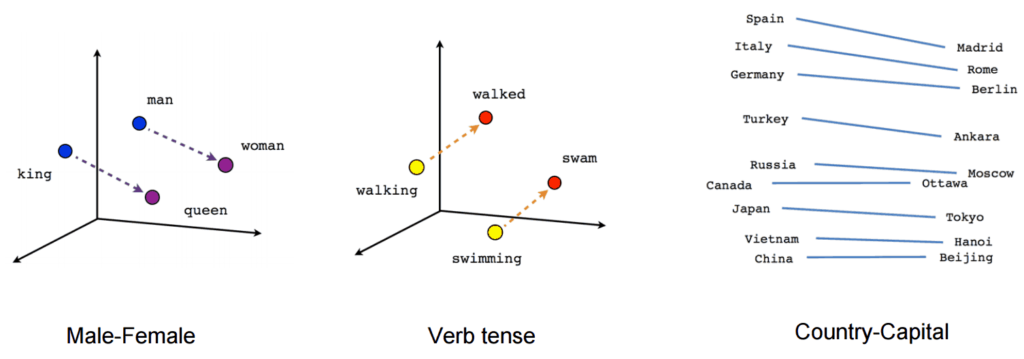
Natural Language Processing ist in der Lage, sowohl gesprochene als auch geschriebene Sprache zu erkennen, zu analysieren und den Sinn für die Weiterverarbeitung zu extrahieren. Dazu ist es notwendig, nicht nur einzelne Wörter, sondern ganze Textzusammenhänge und Sachverhalte zu verstehen. Um diese Textbedeutungen zu erkennen, werden im Vorfeld große Datenmengen erfasst und daraus mit Hilfe von Algorithmen Muster abgeleitet. Dazu tragen vor allem Machine Learning und andere Big-Data-Techniken als wichtige Treiber des Natural Language Processing bei.
Ursprünglich bezog sich der Begriff Natural Language Processing nur auf die Lesefähigkeit von Computersystemen. Mittlerweile werden auch andere Aspekte der Linguistik berücksichtigt. Unterkategorien von Natural Language Processing sind Natural Language Understanding und Natural Language Generation. Die Unterschiede und die Bedeutung dieser Begriffe werden im Folgenden erläutert.
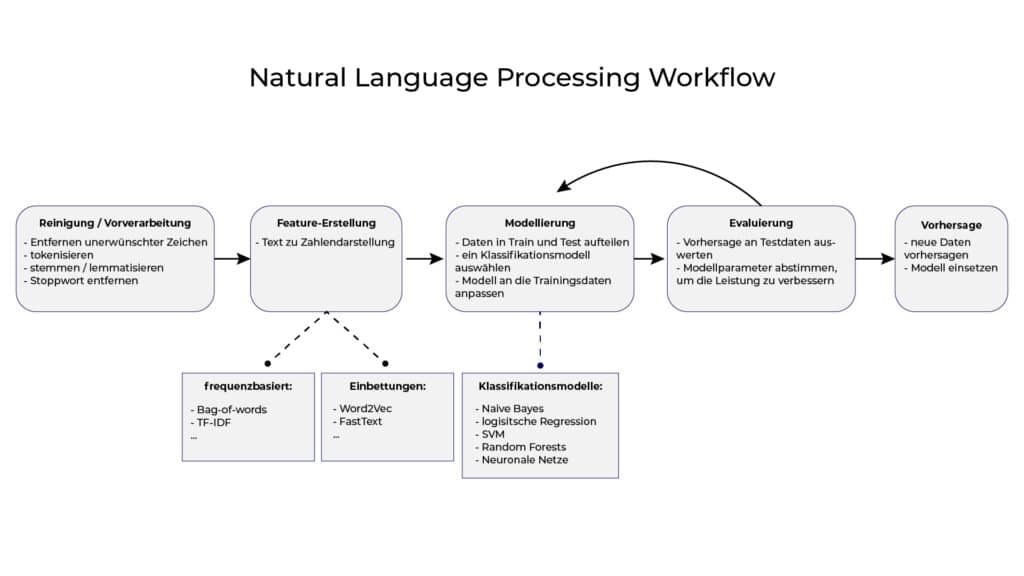
Prozess eines Natural Language Processing Workflows
Damit Natural Language Processing in der Praxis erfolgreich eingesetzt werden kann, müssen im Vorfeld einige wichtige Schritte beachtet werden. Neben der Vorverarbeitung der Daten spielen die Feature-Erstellung, die Modellierung und die Evaluierung eine entscheidende Rolle. Die folgende Grafik veranschaulicht den Ablauf eines Natural Language Processing Workflows:
Was sind die Unterschiede zwischen NLP, NLU und NLG?
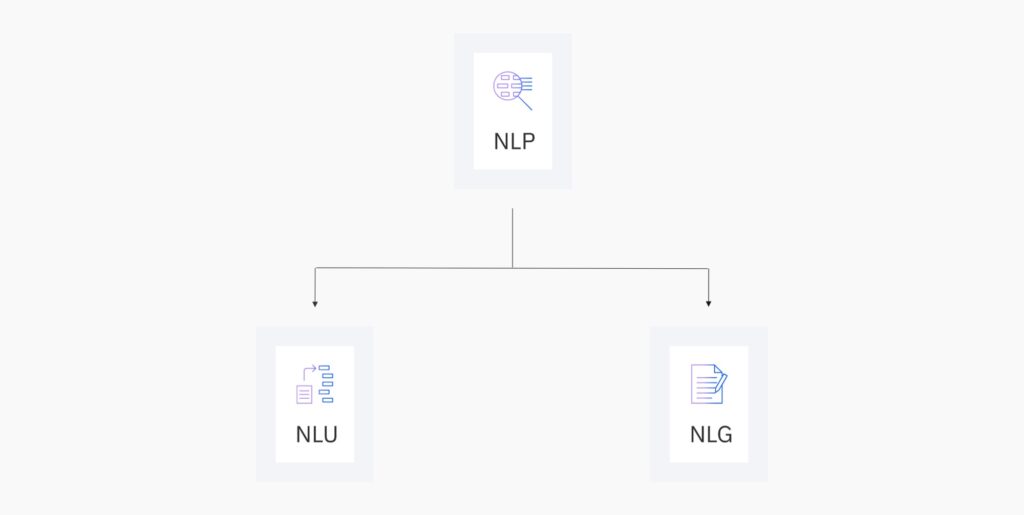
Im Rahmen von Natural Language Processing tauchen immer wieder Begriffe auf, die sich zwar ähneln, aber dennoch unterscheiden. Da sich diese Begriffe überschneiden, werden sie häufig innerhalb der Praxis verwechselt. Dennoch ist auf folgende Unterschiede bei den Begriffen zu achten:
- Natural Language Processing (NLP) = Verarbeitung natürlicher Sprache:
Im Rahmen von Natural Language Processing, der Verarbeitung von natürlicher Sprache, werden unstrukturierte Sprachdaten in ein strukturiertes Datenformat umgewandelt. Dies soll es Maschinen ermöglichen, Sprache sowie Text zu identifizieren und verstehen, um im Anschluss relevante Antworten zu generieren.
- Natural Language Unterstanding (NLU) = Verstehen natürlicher Sprache:
Natural Language Unterstanding befasst sich dem reinen Verständnis natürlicher Sprache. Dabei konzentriert sich NLU primär auf maschinelles Leseverständnis. Dazu werden vorwiegend Grammatik sowie Kontext analysiert, um den Sinn sowie die Bedeutsamkeit eines Satzes zu identifizieren. Mehr Informationen zu Natural Language Unterstanding finden Sie hier.
- Natural Language Generation (NLG) = Erzeugung natürlicher Sprache:
Im Rahmen von Natural Language Generation geht es um die konkrete Erzeugung von Textbausteinen. Dies bedeutet, dass NLG sich vorwiegend mit der Konstruktion von Texten befasst. Auf Grundlage eines vorliegenden Datensatzes kann eine Maschine dabei Texte in unterschiedlichen Sprachen konstruieren. Mehr Informationen zu Natural Language Generation finden Sie hier.
Welche Aufgaben hat Natural Language Processing?
Die Analyse menschlicher Sprache ist für Maschinen eine große Herausforderung. Texte und Sprachdaten sind voller Mehrdeutigkeiten und Unregelmäßigkeiten. Verschiedene Aufgaben des Natural Language Processing (NLP) zerlegen die menschliche Sprache in Elemente, die ein Computer verstehen kann. Zu den Aufgaben des Natural Language Processing gehören
- Spracherkennung: Spracherkennung, befasst sich mit der Möglichkeit, aus Sprachdaten zuverlässige Textdaten herzustellen. Spracherkennung ist für eine alle Anwendungen erforderlich, die sich mit der Analyse von Sprachbefehlen beschäftigen. Dadurch, dass Menschen auf unterschiedlichste Weise kommunizieren, stellt die Spracherkennung eine große Herausforderung dar. Dabei sind vor allem Unterschiede bezüglich der Sprechart, Geschwindigkeit, Deutlichkeit oder der unterschiedlichen Betonung und Intonation sowie Akzente und falsche Grammatik zu beachten.
- Part of Speech-Tagging: Diese Funktion von Natural Language Processing wird auch grammatikalisches Tagging genannt. Dabei geht es darum, je nach Verwendung oder Kontext, bestimmte Wörter oder Textstücke richtig zu bestimmen und verstehen. Beispielsweise ist es dank Part of Speech-Tagging möglich, das Wort “make” in folgenden Sätzen unterschiedlich zu identifizieren. Einerseits kann “make” als Verb wahrgenommen werden (I can make a smoothie) und andererseits als Substantiv (What make of watch do you own).
- Named Entity Recognition (NEM): NEM befasst sich mit der Aufgabe, Wörter oder Textbausteine in unterschiedlichen Kontexten zu erkennen. Beispielsweise ist es dank NEM möglich, dass der Begriff “Köln” als Ort identifiziert wird und “Jonas” als Name.
- Sentiment-Analyse: Durch die Sentiment-Analyse ermöglicht es, Einstellungen, Emotionen und Präferenzen innerhalb von Textpassagen zu identifizieren und zu deuten. Zudem können unterschiedliche Redeformen wie Sarkasmus oder Ironie extrahiert sowie erkannt werden.
- Maschinelle Übersetzung: Durch die Funktion der maschinellen Übersetzung, lassen sich Texte automatisch in eine andere Sprache übersetzen. Dank NLP-Algorithmen ist es möglich, umfangreiche Texte in verschiedenen Sprachen wiederzugeben. Zudem können moderne Übersetzungsprogramme erfassen in welcher Sprache die Texteingabe erfolgt, sodass daraufhin die gewünschte Übersetzung automatisch gelingt.
- Dokumentenzusammenfassung: Diese Funktion ermöglicht dem Nutzer, dass eine automatische Generierung von Zusammenfassungen großer Texte erfolgt. Vor allem in Bereichen, in denen riesige Textmengen vorliegen, ist es hilfreich, dass die Wesentlichen Erkenntnisse prägnant zusammengefasst werden.
- Speech-to-text und Text-to-Speech-Konvertierung: Im Rahmen dieser Funktion wird Natural Language Processing dazu genutzt, dass eine Umwandlung von Text in eine akustische Sprachausgabe erfolgt. Zudem kann dieser Prozess auch umgekehrt erfolgen, sodass gesprochene Sprache in einen geschriebenen Text transformiert wird.
Was sind die Anwendungsbereiche von Natural Language Processing?
Die Verarbeitung von natürlicher Sprache stellt eine treibende Kraft hinter künstlicher Intelligenz dar. Dadurch ergeben sich unzählige moderne Anwendungen innerhalb des Alltags. Im Folgenden finden Sie einige Beispiele, die dank Natural Language Processing möglich sind:
Virtuelle Assistenten
Zu den Vorreitern virtueller Assistenten gehören Siri (Apple) und Alexa (Amazon). Diese nutzen Spracherkennung, um aus gesprochener Sprache, Befehle und Wünsche herauszufiltern. Zudem spielt die Generierung natürlicher Sprache eine wesentliche Rolle im Hinblick auf entsprechende Antworten des Systems.
Identifikation von Krankheiten
Dank Natural Language Processing ist es möglich, dass Krankheiten in der Medizin frühzeitig erkannt werden. Auf Grundlage von elektronischen Gesundheitsdaten und der Identifizierung gesprochener Sprache eines Patienten, kann das System Mängel bei Krankheiten wie Herz-Kreislauf-Erkrankungen, Depressionen oder Schizophrenie erkennen.
Kundenmeinungen analysieren
Innerhalb sozialer Netzwerke kann Natural Language Processing dazu dienen, Stimmungen und Auffälligkeiten von Kunden zu erkennen. Dabei werden relevante Daten wie beispielsweise Kommentare zu einem Produkt oder Service extrahiert, um im Anschluss Informationen und Hintergründe zur Stimmung eines Kunden zu erlangen. Dadurch können Unternehmen frühzeitig agieren und Kundenabwanderungen minimieren.
Textzusammenfassung
Natural Language Processing wird ebenfalls dazu verwendet, riesige Datenbanken in Form von Texten zusammenzufassen. Dadurch große Textpassagen auf den wesentlichen Inhalt gekürzt werden, wodurch Zeit gespart werden kann. Dazu nutzt man semantische Schlussfolgerungen und die Generierung natürlicher Sprache (NLG), um vorliegenden Zusammenfassungen einen nützlichen Kontext zu verleihen.
Spam-Filter
Ein Spam-Filter arbeitet auf Basis von NLP-Verfahren, somit lassen Junk-Mails ausfindig machen. Schaut man sich die einzelnen Betreffzeilen derjenigen E-Mails an, welche im Spam-Ordner gelandet sind, so ist schnell eine Ähnlichkeit festzustellen.
Dabei werden natürlich generierte E-Mails mit typischen Wörtern aus Spam-E-Mails verglichen. So lernt das System nach und nach zwischen einer spam- und sinnvollen E-Mail zu differenzieren.
Speech-to-Text-Konvertierung
Zudem kann Speech-to-Test-Konvertierung im Alltag dienen, Mailbox-Aufzeichnungen durch verpasste Telefonanrufe so zu konvertieren, dass diese als Textnachricht an Ihr E-Mail-Postfach weitergeleitet werden. Dies hat vor allem den enormen Vorteil, dass Mitarbeiter nicht zeitabhängig agieren müssen und trotzdem wichtige Nachrichten erhalten, auch wenn sie telefonisch eingehen.
Aber auch wenn Sie die integrierte Suchleiste einer Website nutzen, werden verschiedene NLP-Methoden für Suche, Themenmodellierung oder Content-Kategorisierung genutzt.
Textverarbeitung im Kundenservice
Im Bereich einer Kundenanfrage kann ein Natural Language Processing System helfen, das Anliegen sowie die Stimmung (Sentiment Analyse) des Kunden zu erkennen. Daraus können je nach Bedarf verschiedene Entscheidungen abgeleitet werden, wie z.B:
Bei Standardanfragen mit einem schnell zu lösenden Problem kommuniziert der Kunde weiterhin mit der Maschine bzw. dem Computer. Dadurch erhält der Kunde schnell eine Antwort und das Unternehmen kann wertvolle Ressourcen wie Mitarbeiter anderweitig einsetzen.
Handelt es sich jedoch um ein komplexes Problem, leitet das System die Anfrage an einen Mitarbeiter weiter. Dieser garantiert dem Kunden im weiteren Verlauf eine persönliche und individuelle Bearbeitung des Problems.
Darüber hinaus können Telefongespräche für Verfahren des Natural Language Processing genutzt werden. Dabei transkribiert ein System die vorhandenen Audiodateien und generiert daraus einen Text. Anschließend analysiert ein Algorithmus diesen vorliegenden Text und klassifiziert die Telefonate nach Themen.
Diese Klassifikation ermöglicht es dem Unternehmen, dem Kunden unterschiedliche Lösungen für unterschiedliche Probleme anzubieten, wodurch eine starke Kundenzentrierung entsteht.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei der Umsetzung von NLP-Lösungen für Ihr Unternehmen.
Textklassifikation von E-Mails
Für viele Unternehmen stellt die Informationsflut im E-Mail-Verkehr ein Problem dar. Mit Natural Language Processing (NLP) sind Unternehmen jedoch in der Lage, E-Mails so zu klassifizieren, dass das Unternehmen einen besseren Überblick erhält.
NLP-Technologien sind in der Lage, verschiedene E-Mails zu scannen und anschließend deren Dringlichkeit zu bestimmen. So erhalten E-Mails mit hoher Dringlichkeit eine besondere Priorität und werden zügig an den Kundenservice weitergeleitet.
Das System scannt dabei vor allem Wörter wie “Antwort”, “Bestätigung”, “dringend” und lernt aus diesem Prozess, dringende E-Mails von weniger dringenden zu unterscheiden. Unterschiedliche Anliegen wie Kündigung, Adressänderung oder Reklamation können unterschieden werden.
Zum Thema Textklassifikation haben wir hier einen Beitrag geschrieben.
Anrufweiterleitung mit IVR-Systemen
Sicher haben Sie schon einmal einen Kundendienst angerufen und mussten ein bestimmtes Wort sagen, um an die entsprechende Abteilung weitergeleitet zu werden. Wahrscheinlich haben Sie dabei mit einem Interactive Voice Response-System gesprochen, das Ihre Anfrage bearbeitet hat. Diese IVR-Technologien erkennen gesprochene Sprache und wandeln diese Sätze in Textbausteine um.
Dadurch, dass der Kunde im Voraus eine bestimmte Auswahl seines Anliegens treffen kann, muss er sich nicht erst eine Reihe von Optionen anhören, aus denen er dann auswählen kann.
Denn IVR-Systeme arbeiten mit einem schnellen, lösungsorientierten Ansatz, der den Kunden direkt nach seinem konkreten Problem fragt.
Große Unternehmen wie American Airlines konnten dadurch enorme Potenziale im Kundenservice erschließen. So konnte durch die Überarbeitung des bestehenden IVR-Systems die Anzahl der eingehenden Kundenanrufe um 5% gesteigert und gleichzeitig Kosten in Höhe von mehreren Millionen Euro eingespart werden.
Es gibt einen neuen Ansatz, mit dem Sie mehrere smarte Automatisierungen gleichzeitig ansteuern und ausführen können: KI-Agenten. Wie diese funktionieren zeigen wir Ihnen in unserem Blog: KI-Agenten: Die Zukunft intelligenter Automatisierung.
E-Mail-Routing – am Beispiel Uber
Um seinen Kunden die bestmögliche End-to-End-Erfahrung zu bieten, hat sich Uber zum Ziel gesetzt, den Kundensupport einfacher und zugänglicher zu gestalten. Zu diesem Zweck nutzt Uber fünf verschiedene Kommunikationskanäle, um die große Anzahl an Kontaktanfragen zu bearbeiten. Bei täglich hunderttausenden Anfragen aus rund 400 Städten weltweit stellt dies eine große Herausforderung für das Unternehmen dar.
Um dieser Herausforderung gerecht zu werden, hat Uber ein eigenes System entwickelt: COTA. COTA ist ein Akronym für Customer Obsession Ticket Assistant. Es handelt sich dabei um ein Tool, das maschinelles Lernen und Techniken der natürlichen Sprachverarbeitung nutzt, um den Kundensupport zu verbessern.
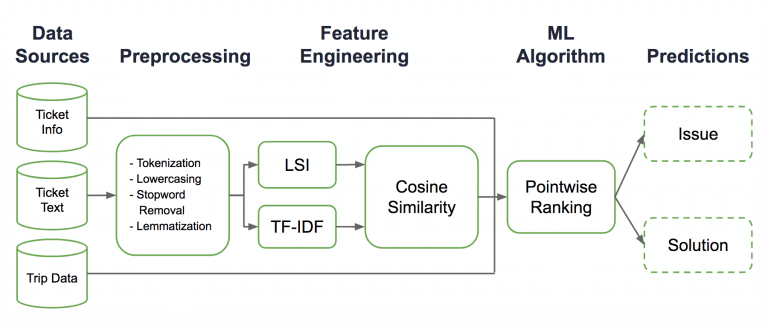
COTA ermöglicht dem Unternehmen eine schnelle und effiziente Problemlösung von Kundenanfragen, wodurch mehr als 90% der eingehenden Anfragen automatisch bearbeitet werden können. Dies hilft vor allem Kundendienstmitarbeitern, die Geschwindigkeit und Genauigkeit ihrer Arbeit zu verbessern. Letztlich profitiert dabei der Kunde durch eine verbesserte Kundenerfahrung.
Welche Tools gibt es für Natural Language Processing?
Für die Verarbeitung von Sprache gibt es einige Tools und Anwendungen, die dabei helfen. Im Folgenden erfahren Sie, welche gängigen Tools und Methoden es im Bereich Natural Language Processing gibt.
Python und Natural Language Toolkit (NLTK)
Die bekannte Programmiersprache Python bietet eine Vielzahl von Werkzeugen für NLP-spezifische Aufgaben. Einige davon finden sich im Natural Language Toolkit (NLTK). Dabei handelt es sich um eine Open-Source-Sammlung von Programmen, Bibliotheken und anderen Ressourcen zur Erstellung von NLP-Programmen.
Das Natural Language Processing Toolkit enthält einige Werkzeuge, um die oben genannten Aufgaben und Anwendungsgebiete zu bewältigen. Darüber hinaus gibt es Bibliotheken für Teilaufgaben wie Wortsegmentierung, Satzparsing oder Stemming und Lemantisierung für das Textverständnis.
Statistisches NLP, maschinelles Lernen und Deep Learning
Die ersten NLP-Anwendungen waren manuell kodierte, regelbasierte Systeme. Diese waren zwar in der Lage, bestimmte Aufgaben zu erfüllen, waren aber für ein breites Aufgabenspektrum nicht geeignet.
Statistisches NLP kombiniert Computeralgorithmen mit maschinellem Lernen und Deep-Learning-Modellen, um Text- und Sprachdaten automatisch zu extrahieren, zu klassifizieren und anschließend den Elementen mit einer statistischen Wahrscheinlichkeit eine mögliche Bedeutung zuzuweisen.
Mittlerweile bieten Deep Learning Modelle die Möglichkeit, NLP-Systeme zu erstellen, die während des Prozesses selbstständig lernen. Dadurch können diese Systeme im Laufe der Zeit immer präzisere Lösungen entwickeln.
Was sind die Herausforderungen der Sprachverarbeitung?
Natural Language Processing ist kein einfaches Problem der künstlichen Intelligenz, was vor allem an der Natur der menschlichen Sprache liegt, die sehr komplex ist.
Es gibt viele Regeln und Zusammenhänge, die es für Computer schwierig machen, sie zu verstehen und richtig zu interpretieren. Als Beispiel sei hier Sarkasmus genannt, der für den Computer extrem schwer zu verstehen ist.
Auf der anderen Seite gibt es natürlich auch viele sehr einfache Aufgaben, wie z.B. Wörter oder Pluralerkennung, die ein Computer erlernen kann.
Um natürliche Sprache zu verstehen, muss der Computer sowohl die Wörter als auch die Konzepte und Regeln dahinter verstehen. Für uns Menschen ist das oft sehr einfach, aber für Natural Language Processing ist das die große Herausforderung.
Die Herausforderungen liegen daher vor allem in folgenden Bereichen:
Modell
In der Praxis ist es oft schwierig, die Qualität der Modellergebnisse zu beurteilen. Beispielsweise ist die Interpretation der Klassifikation von Emotionen wesentlich einfacher als die Bewertung von Zusammenfassungen. Daher ist es gerade in der Anfangsphase eines Projektes wichtig, ein Gütemaß zu bestimmen. Dieses sollte einerseits praktikabel sein und andererseits das zu lösende Problem widerspiegeln.
Darüber hinaus sollten Fragen zur Leistungsfähigkeit des Modells geklärt werden. Beispielsweise hat ein Modell, das Ergebnisse in großen Zeitintervallen berechnet, andere Eigenschaften als ein Modell, das Anfragen innerhalb von Zehntelsekunden beantworten muss.
Daten
Vortrainierte Modelle (Transfer Learning) haben die Eigenschaft, dass sie oft in verschiedenen Aufgaben gut abschneiden. Dies führt häufig dazu, dass diese Modelle zwar gute, aber keine herausragenden Ergebnisse liefern. Je nach Business Case sollte daher eine konkrete Feinabstimmung des Modells erfolgen, um optimale Ergebnisse in Bezug auf die Problemstellung zu generieren.
Das Feintuning umfasst zwei Dimensionen. Zum einen muss das Modell an sprachliche Einheiten angepasst werden. Dabei spielen Wortschatz, Slang oder Dialekt eine entscheidende Rolle. Je nach Branche können diese Bereiche stark variieren.
Zum anderen muss das Modell neben der Feinabstimmung auch konkret auf die vorliegende betriebswirtschaftliche Problemstellung angepasst werden. Für die Klassifikation von Emotionen muss ein Modell anders funktionieren als für die Übersetzung von Texten.
Rechenleistung
Vor allem die stetige Verbesserung der Rechenleistung hat zum Vormarsch der künstlichen Intelligenz geführt. Dennoch bieten vortrainierte Modelle die Möglichkeit, nur einen Bruchteil der eigenen Rechenleistung aufbringen zu müssen.
Lediglich für die Datenverarbeitung wird Rechenleistung benötigt, die einen Bruchteil der Rechenleistung des gesamten Trainings ausmacht. Auch wenn der Aufwand durch vortrainierte Modelle minimiert werden kann, muss ein Computer über eine gewisse Rechenleistung verfügen. Daher wird in der Praxis meist auf Cloud Computing zurückgegriffen. Die Kosten für Cloud Computing werden in der Regel minutengenau abgerechnet, so dass sich ein Standardrechenzentrum aus Kostengründen meist nicht lohnt.
In Abgrenzung zum Natural Language Processing steht das Konzept des Large Language Models, welches im Bereich des Deep Learnings einzuordnen ist.
Fazit
Die Kommunikation zwischen Mensch und Maschine ist heute Realität. Mit zunehmender Rechenleistung und Datenmenge werden die Technologien des Natural Language Processing immer leistungsfähiger.
Wie die verschiedenen Beispiele zeigen, dient Natural Language Processing vor allem dazu, die Interaktion mit dem Kunden zu verbessern. Dabei zeichnen sich NLP-Systeme dadurch aus, dass sie jederzeit verfügbar und beliebig skalierbar sind.
Wenn Sie weitere Fragen zu der praktischen Anwendung von NLP haben, dann kontaktieren Sie mich gerne.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte








