


Spark als ETL Werkzeug nutzen und von Big Data Performance profitieren
Die In-Memory Big Data Plattform Apache Spark dominiert die Big Data Welt. Natürlich lässt sich Spark sehr gut für ETL-Prozesse einsetzen und somit lassen sich täglich enorme Datenmengen bewegen, filtern und transformieren. Große Firmen wie Facebook machen es vor und zeigen mit einem produktiven Spark ETL-Prozess von 60 TB, der im Vergleich bis zu x6 schneller ist als der Apache Hive Job, die extreme Stärke der Plattform auf.
Mit den unterschiedlichen Daten und Datentypen, die täglich in unsere Data Lakes geladen werden, müssen wir hinsichtlich der Aufbereitung der Daten extrem flexibel sein. Hier kann Spark helfen die Datenaufbereitung durch ETL (Extract, Transform, Load) effizient zu gestalten. Durch das Spark DataSource API ist man mit der Technologie in der Lage die verschiedensten Quellen zu lesen.
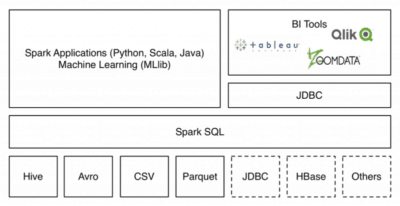
Diese Vielfalt im Big Data Umfeld kann kaum eine Plattform bieten und viele traditionelle Datenbanken sind sehr starr auf bestimmte Datenquellen ausgerichtet und adaptieren nur sehr langsam neue Quellen, wie bspw. das spaltenorientierte Format Parquet.
Spark als zentrale ETL Engine für Data Lakes
Folgend zeige ich euch eine mögliche Architektur, in der Apache Spark eine zentrale Rolle für die Datenverarbeitung spielt. Gezeigt wird hierbei ein hybrider Architekturansatz mit bestehender DWH Architektur und Data Lake. Apache Spark nimmt dabei die Position als zentrale ETL Engine ein. So können bspw. große Log Daten, wie Trackingdaten, von Spark über Spark ETL Prozesse in die gewünschte (gefiltert & aggregiert) Form gebracht werden und zurück ins DWH gespielt werden.
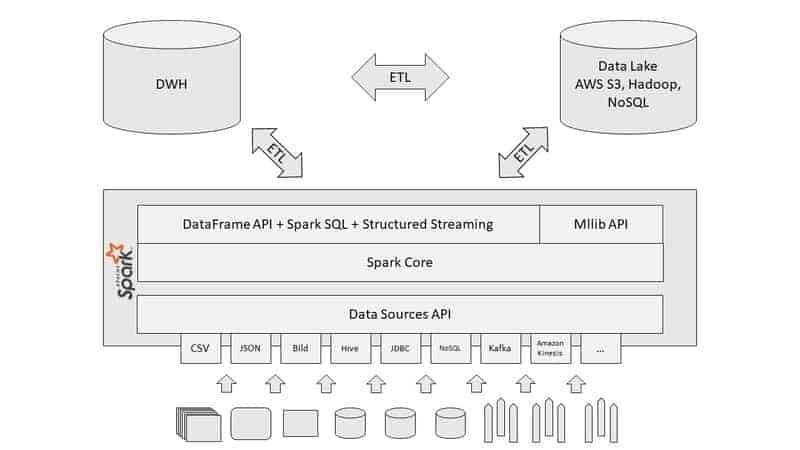
Die Grafik zeigt ebenfalls schön, wie das schon beschriebene Data Source API eingesetzt werden kann. Als Beispiel kann auch das HDFS Filesystem ohne Probleme mit Spark angesprochen werden, somit integriert sich Spark in viele Umgebungen aus der Big Data Landschaft. Neben den verschiedenen Dateitypen, ist Spark natürlich auch in der Lage, Streaming-Daten in Real-Time zu verarbeiten. Apache Kafka übergibt z.B. im Stream Dateien im JSON-Format, welche anschließend von Spark Streaming gelesen werden.
Vorteile von Spark als ETL Engine
In der Einführung habe ich kurz über die Vorteile von Apache Spark als ETL Engine berichtet. Besonders im Big Data Umfeld sind die Vorteile von Spark ETL Prozessen deutlich:
- In-Memory Verarbeitung beschleunigt ETL Prozesse mit Spark. Die grundlegende Technologie von Spark ermöglicht eine schnelle Verarbeitung von großen Datenmengen im Arbeitsspeicher. Somit kannst du viel Zeit sparen und Daten schneller bereitstellen.
- Das DataSource API stellt eine große Anzahl von Standard-Dateiformaten bereit und ist in der Lage alle gängigen Formate zu lesen und schreiben.
- Funktionale Schreibweise hilft dabei, den Code wiederverwendbar zu machen. So sind Prozesse schnell übertragen und ggf. angepasst auf neue Anforderungen.
- Streaming ETLs sind mit Spark möglich. Im Stream verarbeiten wir die Daten nicht mehr im Batch, sondern im kontinuierlichen Stream. Streaming ETLs stellen einen sehr interessanten Bereich dar und es wird derzeit viel in diese Richtung entwickelt, was etliche Beiträge auf dem Spark Summit belegen.
- Machine Learning Pipelines laufen in der gleichen Umgebung ab. Das hat den großen Vorteil, dass du keine störenden PMMLs exportieren und importieren musst, wenn du ein ML Scoring durchführen willst.
[elementor-template id=“5035″]
Wie baue ich einen ETL in Apache Spark? Spark ETL Beispiel
In diesem Spark Beispiel zeige ich auf, wie man aus einer Inputdatei mit Apache Spark einen ETL Prozess aufsetzt, der das File filtert, transformiert und in einem anderen Format abspeichert. Für den Beispiel ETL nutze ich die native Spark API, mit der ich einfach ETL Prozesse in Scala schreibe, was eine elegante ETL Logik ohne Erweiterungen erlaubt.
Extract
Wir gehen davon aus, dass wir in unserem Data Lake für jeden Tag neue CSV-Dateien mit Online-Shop Interaktionen und den dazugehörigen Produktmetadaten geliefert bekommen. Die Daten liegen auf einem Amazon S3 Bucket und wir wollen die geklickten Kategorieinformationen zukünftig in unseren Machine Learning Modellen nutzen, daher müssen wir die Daten aufbereiten und in einen ML Feature Store schreiben.
val dataLakeCSV = sqlContext.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("s3a://new-interactions/")
val filteredDF = dataLakeCSV.filter($"shop_id" === "s_1qs_de")
.filter($"interaction_type"==="view")
val shopMetadata = sqlContext.read.format("csv")
.option("delimiter", ";")
.option("header", "true")
.option("inferSchema", "true")
.load("/FileStore/tables/Shop_metadata.csv")
Transform
Nachdem wir die Views von unserem Shop herausgefiltert haben, wollen wir nun pro Kunde die Anzahl der Produktdetailansichten der letzten 5 Tage zu einem Feature berechnen.
Um das zu tun, können wir unser gefiltertes DataFrame filteredDF nehmen und eine Transformation darauf anwenden, das Ergebnis ist ein neues transformiertes DataFrame.
Durch die funktionale Schreibweise, wird der Code für verschiedene Transformationen nutzbar und lässt sich leicht innerhalb von anderen Prozessen wiederverwenden.
Die Transformation aggViews() aggregiert unserer E-Commerce Produktdetailansichten über die Kategoriemetadaten der letzten 5 Tage:
def aggViews(df: DataFrame): DataFrame = {
df.filter(((current_timestamp().cast("long") - $"timestamp".cast("long"))
/ (24D * 3600D)) <= 5.0 )
.groupBy($"user";, $"category")
.agg(count("*").alias("sum_views"))
}
def technicalTS()(df: DataFrame): DataFrame = {
df.withColumn("db_user", lit("mlguide_user"))
.withColumn("input_timestamp", current_timestamp())
}
Die zweite Transformation technicalTS() soll zudem ein paar technische Daten schreiben, so dass wir den Prozess nachvollziehen können.
Load
Um unseren ETL in Spark auszuführen und die Transformieren Daten zuschreiben, brauchen wir eine Funktion etlWriter(), die die Daten in unserem FileStore persistiert. In diesem Fall schreiben wir die Daten in Parquet auf das Dateisystem. Ein anderer Weg ist die Daten in ein Hive Warehouse zu schreiben.
def etlWriter()(df: DataFrame): DataFrame = {
val path = "/FileStore/output/shop_interactions"
df.write.mode(SaveMode.Overwrite).parquet(path)
return null
}
Um unser Beispiel ETL jetzt auszuführen, müssen wir die einzelnen Funktionen aneinanderhängen und diese ausführen. Dafür schreiben wir uns eine kleine Funktion ETL().
def ETL(views: DataFrame, meta: DataFrame): DataFrame = {
views.join(meta, Seq("item_id"), "left")
.transform(aggViews())
.transform(technicalTS())
.transform(etlWriter())
}
Die ETL Funktion führt alle unsere Schritte zusammen: ein Left-Join mit den Produktmetadaten, die Aggregation, technische Informationen und das Schreiben der Ergebnisse in einem Parquet File.
Als letztes müssen wir unsere ETL()Funktion nur noch mit den entsprechenden Parametern aufrufen. Die ETL() Funktion erwartet zwei DataFrames mit unseren Shopviews und Produktmetadaten. Das Ganze wird so aufgerufen:
ETL(filteredDF,shopMetadata)
Fazit Spark als ETL Engine
Wie wir gesehen haben ist Apache Spark als ETL Engine sehr unterschiedlich einzusetzen und bietet einige Vorteile. Nicht ohne Grund setzen sehr viele von den großen Tech-Unternehmen auf diese Technologie.







