


CRISP-DM ist ein einheitlicher Standard für die Entwicklung von Data Mining Prozessen und hilft Unternehmen dabei Data Mining Projekte gut zu strukturieren.
Haben Sie die Herausforderung ein Data Mining Projekt zu strukturieren? Oder wollen wissen was die „best practices“ für einen einheitlichen Prozess sind?
Für die Strukturierung von Data Mining oder Machine Learning Projekten nutze ich schon seit Jahren den CRISP-DM Standard. Dieser hilft vor allem dabei in Zusammenarbeit mit unseren Kunden den Data Mining Prozess genauer zu erklären und diesen in Ihre Unternehmensprozesse einzubinden.
In den folgenden Abschnitten gehe ich auf die Grundlagen des CRISP-DM ein und beschreibe die Phasen im Detail:
1. Was ist CRISP-DM?
Im Jahr 2000 verschaffte man mit dem CRISP-DM Modell einen einheitlichen Standard für Data Mining Prozesse. Die Entstehung des CRISP-DM-Modells geht auf drei Unternehmen zurück, die sich seit dem Jahr 1996 als führende Organisationen in der Industrie der Auswertung großer Datenbestände, speziell dem Bereich Data Mining, gewidmet haben. Auch die EU war mit Fördermitteln an der Entwicklung beteiligt.
Diese haben durch kontinuierliche Weiterentwicklungen im Bereich Data Mining einen einheitlichen Standard mit dem CRISP-DM-Modell entwickelt. Gemeint sind damit die Unternehmen NCR System Engineering, SPSS Inc., und die DaimlerChrysler AG.
Die grundsätzliche Zielsetzung des CRISP-DM-Modells ist es, einen branchen-, software- und anwendungsunabhängigen standardisierten Prozessablauf des Data Minings für Unternehmen bereitzustellen.
Ziele von CRISP-DM
Die Ziele von dem Data Mining Vorgehensmodell kurz zusammengefasst:
- Schaffung eines einheitlichen Prozess- und Vorgehensmodells für Data Mining Projekte
- Übergreifende Nutzung in verschiedenen Branchen
- Anleitung und Blaupause für Data Mining in 6 Schritten
6 Phasen eines Data Mining Projekts
Ergebnisse des Data Minings sollen durch das CRISP-DM-Modell schneller und präziser zur Verfügung stehen. Im Folgenden wird der CRISP-DM dargestellt, dieser ist in sechs Schritte unterteilt:
- Business Understanding (Aufgabendefinition)
- Data Understanding (Auswahl der relevanten Datenbestände)
- Data Preparation (Datenaufbereitung)
- Modeling (Auswahl und Anwendung von Data Mining Methoden)
- Evaluation (Bewertung und Interpretation der Ereignisse)
- Deployment (Anwendung der Ergebnisse)
Die einzelnen Phasen, sowie die Iterationen der einzelnen Phasen dieses Modells, lassen sich je nach Problemstellung unterschiedlich gewichten. Jede Phase dieses Modells spielt eine entscheidende Rolle für den Erfolg eines Data Mining-Projektes. In Abbildung 5 wird erkenntlich, dass das CRISP-DM-Modell einen Kreislauf darstellt und somit iterativ ist. Dies bedeutet, dass es keinen definierten Endpunkt in dem Data Mining-Prozess gibt. Der äußere Kreis stellt die Iteration des ganzen CRISP-DM-Modells dar, was bedeutet, dass jeder Durchlauf neue Fragen aufwerfen kann. Dabei trägt jede Wiederholung zu einer weiteren Optimierung des Prozesses bei.
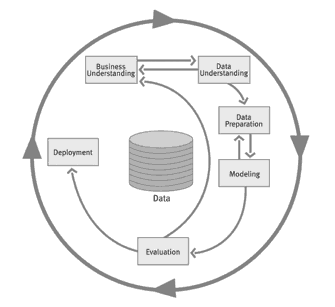
Die inneren Pfeile machen deutlich, dass es sich bei dem Ablauf des Prozesses nicht um eine starre Sequenz handelt, sondern, dass es durchaus Rückkopplungen innerhalb des Zykluses geben kann. Dies kann passieren, wenn unvorhergesehene Probleme auftreten oder man Zwischenziele nicht in der gewünschten Qualität erreicht.
Phase 1: Business Understanding
Die erste Phase konzentriert sich auf die präzise Beschreibung der betriebs-wirtschaftlichen Problemstellung. Im nächsten Schritt eines Data Mining-Projektes überführt man die betriebswirtschaftlichen Problemstellungen in konkrete Anforderungen an die Datenanalyse. Diese bilden die zentrale Grundlage für alle weiteren Schritte und Entscheidungen im Data Mining-Prozess, z.B. über die Auswahl der Methoden.
Anhand der konkreten betriebswirtschaftlichen und analytischen Zielsetzungen ist ein Projektplan für das Projekt zu entwickeln. In dem Projektplan sind die erforderlichen zeitlichen, personellen und sachlichen Ressourcen zu spezifizieren.
Hierbei ist es wichtig, den Anwender mit in den Data Mining-Prozess einzubeziehen, um ein Verständnis der betriebswirtschaftlichen Fragestellung des Projektes zu entwickeln:
- Bestimmung der betriebswirtschaftlichen Problemstellung: Hier wird an den Anwender die Anforderung gestellt, das Data Mining Projekt betriebswirtschaftlich auszurichten. Dabei werden die operationalen und betriebswirtschaftlichen Zielkriterien formuliert.
- Situationsbewertung: Durch die Situationsbewertung werden vorhandene Software- sowie Personalressourcen, die für das Data Mining-Projekt zur Verfügung stehen, bestimmt. Zudem sind mögliche Risiken, die während des Data Mining-Projektes auftreten können, aufzuführen.
- Bestimmung analytischer Ziele: Ausgehend von der zuvor bestimmten betriebswirtschaftlichen Problemdefinition (z.B. zielgerichtete Ansprache der Kunden) müssen dazu die erforderlichen Datenanalyseaufgaben (z.B. Kundensegmentierung, Scoring-Verfahren zur Kampagnenoptimierung etc.) ermittelt werden. Zudem müssen die Erfolgskriterien für das Data Mining-Projekt bestimmt werden (z.B. Steigerung der Responsequote von Kampagnen um 3% bei weniger Ressourceneinsatz, Ansprache des Kunden nach Verhaltensmustern etc.).
- Erstellung des Projektplans: Der Projektplan beschreibt die beabsichtigten Ziele des Data Mining-Projektes, dazu gehört:
- Auflistung der einzelnen Schritte mit Zeitspanne
- Beurteilung möglicher Risiken (Verzögerungen, Ursachen für ein Scheitern des Projektes etc.)
- Prüfung der zur Verfügung stehenden Ressourcen (wie Mitarbeiter ; Hardware; Software z.B. Data Warehouse, Data Mining-Werkzeuge; Datenbestand)
In Data Mining-Projekten wird in der Regel 50%-70% der Zeit für die Datenaufbereitung benötigt. Nur 20%-30% der veranschlagten Zeit entfallen dabei auf die Bestimmung der relevanten Datenbestände. Für die Modellierung, die Bestimmung der betriebswirtschaftlichen Fragestellung und Erfolgsmessung wird jeweils 10%-20% benötigt, lediglich 5%-10% der Zeit entfallen auf die Implementierung der erstellten Modelle.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
Phase 2: Data Understanding
Nach der Formulierung der analytischen Ziele für das Data Mining ist nun eine Auswahl der relevanten Datenbestände zu treffen. Diese Phase dient dem Analysten, bestehende Zusammenhänge aus den Daten zu erkennen, eventuelle Qualitätsmängel der Daten festzustellen oder interessante Teilmengen zu identifizieren, um eine Hypothese über die Daten aufzustellen. Die Phase besteht aus folgenden vier Schritten:
- Daten sammeln: Hier werden die benötigten Daten für die Analyse beschaffen und, wenn erforderlich, in bereits bestehende Datenmengen integriert. Der Analyst sollte Probleme, die bei der Datenbeschaffung auftreten, stets dokumentieren, um mögliche Diskrepanzen bei einem Folgeprojekt in der Zukunft zu vermeiden.
- Daten beschreiben: In diesem Schritt gilt es ein allgemeines Verständnis für die Daten zu erlangen. Zudem werden die Eigenschaften der Daten beschrieben, wie z.B. Quantität der Daten, Formateigenschaften, Anzahl der Einträge und Felder sowie Eigenschaften der Felder. Die entscheidende Frage die sich der Analyst stellen sollte ist, ob die vorliegenden Daten der Datenanalyse genügen um das Projekt erfolgreich abzuschließen.
- Untersuchung der Daten: Zur Untersuchung der Daten werden erste Analysen mit den Daten betrieben um z.B. bestimmte Produktgruppen zu identifizieren, die einen großen Teil des Umsatzes ausmachen. Hierzu werden Reports erstellt, um die ersten Erkenntnisse und Hypothesen zu visualisieren.
- Bewertung der Daten: An diesem Punkt wird die Qualität des Datenbestandes bewertet. Es sollte festgestellt werden, ob die Datenmenge für die Analyse ausreichend und verwendbar ist. Besonders ist auf fehlende Attributwerte zu achten.
Phase 3: Data Preparation
Die Datenvorbereitungsphase umfasst alle Aktivitäten zur Erstellung des endgültigen Datensatzes oder der endgültigen Datenauswahl, die in die Modellierungssoftware zur Analyse geladen wird. Der Schwerpunkt liegt dabei auf der Auswahl von Tabellen, Einträgen und Attributen und insbesondere auf der Transformation und Bereinigung der Daten. Im Folgenden werden die Schritte der Datenaufbereitung beschrieben:
- Auswahl der Daten: Die Auswahl der Daten für das Data Mining hängt stark von den Zielen ab, die man für das Data Mining-Projekt definiert. Hier spielen die Datenqualität und die technischen Gegebenheiten eine große Rolle. Es wird eine Selektion der Daten vorgenommen, wie z.B. eine Auswahl aller Kunden, die einen Umsatz von mehr als 100 Euro im Monat generieren. Am Ende dieses Prozesses sollte sich deutlich zeigen, welche Datenmengen(-Sets) in die Analyse aufgenommen werden oder ausgeschlossen werden.
- Bereinigung der Daten: Ohne eine Bereinigung der Daten ist ein erfolgreiches Data Mining-Projekt fraglich. Es gilt eine saubere Datenmenge auszuwählen oder die Datenmenge muss bereinigt sein, um das gewünschte Ergebnis in der Modellierung zu erreichen.
- Transformation und Integration der Daten: Um die Daten in eine brauchbare Darstellungsform zu bringen, transformiert man die Daten. Die Transformation kodiert Daten und verändert deren Granularität durch Aggregation oder Disaggregation. Wichtige Kennzahlen, die für eine Analyse zu erstellen sind, könnten z.B. Umsatz pro Kunde, Deckungsbeitrag pro Kunde oder Umsatzanteil in Produktgruppe pro Kunde etc. sein.
- Format Data: In einigen Fällen muss für die Modellierung eine einfache Anpassung des Datenformates erfolgen, z.B. Anpassung des Datentyps.
Phase 4: Modeling
Für eine betriebswirtschaftliche Problemstellung können in der Regel mehrere Modellierungstechniken des Data Mining eingesetzt werden. Einige Techniken stellen besondere Anforderungen an die Datenstruktur. Dies kann dazu führen, dass von der Modellierung ein Schritt zurück in die Phase der Datenaufbereitung gemacht werden muss. Dort kann eine Anpassung an das Format oder die Struktur der Daten erfolgen:
- Auswahl der Modellierungstechnik: Hier muss eine Modellierungstechnik ausgewählt werden, mit der das Modell erstellt wird.
- Testmodell erstellen: Nach der Auswahl des Modells wird ein Testmodell erstellt, um die Qualität und Genauigkeit des Modells zu überprüfen. Bei überwachten Verfahren wie der Klassifikation ist es üblich, Fehlerraten als Qualitätsmaß zu verwenden.
- Bewertung des Modells: Hier wird das Modell im Hinblick auf die zuvor definierten Data Mining Ziele bewertet. Darüber hinaus sind die Ergebnisse des Data Mining im Hinblick auf die betriebswirtschaftliche Fragestellung zu bewerten.
Phase 5: Evaluation
Vor der Anwendung des Modells ist es wichtig, das Modell zu evaluieren. Es ist zu hinterfragen, ob das Modell wirklich die Qualität bietet, um dem Ziel des Data Mining Projektes gerecht zu werden. Es ist zu evaluieren, ob das Modell wirklich den Zielen des Data-Mining-Projektes gerecht wird. Wenn die Ziele nicht erreicht werden können, muss die Phase ggf. erneut durchlaufen werden. Die folgenden Schritte sind Aufgaben der Evaluationsphase:
- Bewertung der Ergebnisse: In diesem Schritt wird bewertet, inwieweit das Modell die Projektziele erreicht. Falls die Ziele nicht erreicht wurden, sind die Gründe dafür anzugeben.
- Bewertung des Prozesses: Das Data-Mining-Projekt wird rückblickend bewertet. Es wird festgestellt, ob alle wichtigen Faktoren berücksichtigt wurden und inwieweit die Attribute für zukünftige Data-Mining-Projekte genutzt werden können.
- Nächste Schritte festlegen: In diesem Schritt entscheidet der Projektleiter, ob das Projekt abgeschlossen ist und umgesetzt wird.
Phase 6: Deployment
Die Deployment-Phase stellt in der Regel die letzte Phase eines Data-Mining-Projekts dar. Hier werden die gewonnenen Erkenntnisse so aufbereitet und präsentiert, dass der Auftraggeber sie nutzen kann. Dazu gehören eine mögliche Implementierungsstrategie, die Überprüfung der Gültigkeit der Modelle, ein zusammenfassender Bericht und eine Präsentation.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte








