


Kundenabwanderung (Churn) mit Machine Learning frühzeitig erkennen? In diesem Tutorial nutzen wir Python als Skriptsprache und einen frei verfügbaren Beispieldatensatz von einer Telko, um einen Churn-Score zu erstellen.
Hinweis: Erwarten Sie an dieser Stelle bitte kein perfektes Machine Learning Modell, denn wir mussten das Beispiel für diesen Zweck etwas vereinfachen. Dennoch können Sie dieses Beispiel Churn Score als Einstieg in die Churn Prediction nehmen.
Steigen wir ein.
Was ist Kundenabwanderung (Churn)?
Bevor wir anfangen zu programmieren, lassen Sie uns nochmal auf die Definition von Churn blicken: die Kundenabwanderungsrate quantifiziert die Anzahl der Kunden, die Ihren Dienst oder Vertrag gekündigt haben. Im E-Commerce würde man die Kundenabwanderung nach einer gewissen Zeit als inaktiver Kunde zählen, allerdings ist dies stark abhängig von den verkauften Produkten.
Grundsätzlich würde man das Problem Churn im Handel anders lösen und wir legen den Fokus in diesem Artikel auf die vertragsbasierten Geschäftsmodelle, wie Telekommunikation, Versicherung und Versorger.
Kundenabwanderung ist für viele Unternehmen ein großes Problem und kein Spaß.
Einen ausführlichen Artikel über Kundenabwanderung und Churn Prediction habe ich bereits geschrieben.
Tutorial: Kundenabwanderung mit Machine Learning vorhersagen
Die Grundlage für die Vorhersage von Kundenabwanderung sind historische Daten, wie Transaktionsdaten, Kundeninformationen, aktive Verträge und viele weitere Quellen.
Wer lieber das Python Tutorial im Video sieht, wir haben dazu ein YouTube Video erstellt:
Für das Modelltraining gucken wir uns die Eigenschaften (unabhängige Variable) der gekündigten Verträge (abhängige Variable) in dem Zeitraum vor der Kündigung an, um daraus ein Muster abzuleiten.

Mit einem Machine Learning Modell lernen wir die Beziehungen in den Daten und versuchen dann durch das trainierte Modell, die Reaktionen der aktuellen Bestandskunden richtig vorherzusagen. Diese Art von maschinellem Lernen gehört zu dem überwachten Lernen, um genau zu sein, ist es ein Klassifikationsmodell.
Machine Learning Prozess
In der Regel läuft ein solches Machine Learning Projekt in 5 Schritten ab:
- Problem: Wir müssen ein Problem definieren, was wir mit Daten und Machine Learning lösen wollen und können. Vor allem ist es wichtig zu verstehen, was das Ziel des Vorhabens ist, damit die Daten entsprechend dem Modellierungsziel aufbereitet werden können.
- Datenaufbereitung: Danach folgt die Aufbereitung der Daten. Dazu werden pro Objekt (Kunde oder Vertrag) Aggregationen gebildet und Machine Learning Features abgeleitet, die für das Modelltraining genutzt werden können. Auch die Erstellung der richtigen Beispieldaten (Zielvariablen), also in unserem Beispiel „gekündigt“ und „nicht gekündigt“ ist essentiell.
- Auswahl der Variablen: Wir müssen uns die zur Verfügung stehenden Variablen angucken und eine Auswahl für die Modellierung treffen. Für eine gute Churn Prediction werden in Unternehmen viele Variablen genutzt – nicht selten hunderte.
- Modellierung: Wir müssen uns einen Algorithmus auswählen und das Machine Learning Modell trainieren. Die gelernten Muster können wir dann aus unserem Testset anwenden und eine Prognose erstellen.
- Ergebnisse und Ableitung von Maßnahmen: Anhand der Testset-Ergebnisse können wir die Modellqualität ableiten. Wenn wir mit den Modellergebnissen zufrieden sind, dann fängt eigentlich der wichtigste Teil der Arbeit an: Was machen wir mit den gefährdeten Kunden? Welche Kunden schreiben wir an? Welche Kunden bekommen welches Angebot? Können wir aus den Modellergebnissen Gründe für den Churn ableiten und dann unsere Kommunikation differenzieren?
Die Daten
Daten sind der neue Treibstoff für viele Geschäftsmodelle. Aus diesem Grund werden besonders Kundendaten nur selten veröffentlicht. Ab und zu werden allerdings interessante Daten veröffentlicht. Wir nutzen einen schon aufbereiteten Datensatz den es bei IBM und bei Kaggle zu finden ist: Telcom Customer Churn. Ursprünglich von IBM im Zusammenhang mit IBM Waston Analytics veröffentlicht.
Also ein Datensatz von einem Telekommunikationsunternehmen mit rund 7000 Einträgen. Es gibt eine Vielzahl von Merkmalen in dem Datenset und natürlich schon die Zielvariable, ob der Kunde gekündigt hat oder nicht. Um die Daten besser zu verstehen schauen wir uns diese zunächst erstmal genau an.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("../input/Telco-Customer-Churn.csv")
df.head(5)
Datenexploration und Merkmalsauswahl
Zunächst werfen wir einen Blick auf die Daten und schauen uns vor allem an wie unsere Zielvariable nach den Klassen „gekündigt“ und „nicht gekündigt“ verteilt ist. Um einen tieferen Einblick in eine Datenexploration zu bekommen gibt es sicher bessere Tutorials, hier liegt der Fokus auf der Erstellung des Churn-Scores.
Da wir Python und Pandas nutzen, können wir uns die Daten mit dem Befehl data.head(5) angucken.
df.head(5)
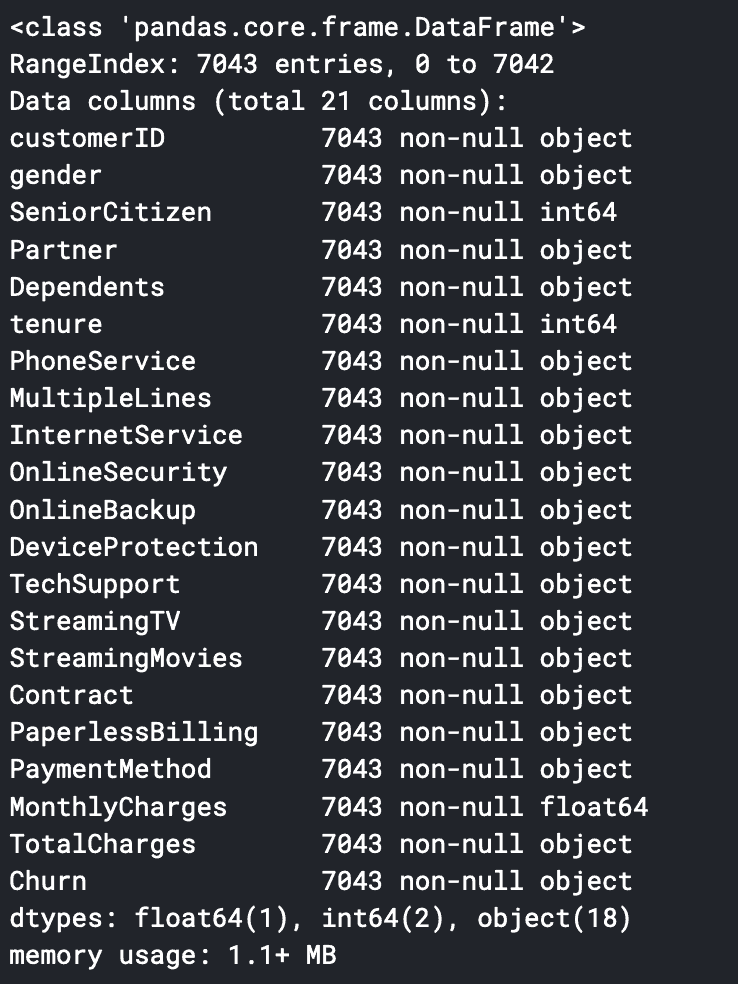
df.info()
Im Detail ist die Zielvariable, die tatsächliche Kundenabwanderung bei 26,5 %. Dies ist wichtig zu wissen, da wir die Daten für das Modelltraining anschließend neu verteilen müssen. Zumindest müssen diese Information für uns gespeichert und zu einem späteren Zeitpunkt bei der Modellbewertung betrachten werden.
Wichtig: Häufig ist die Churn Rate etwas geringer als 26,5 %. Wichtig ist, dass Sie den Churn richtig abgrenzen. Wann wollen Sie auf die Kunden aktiv zugehen? Wenn wir in deinem festen Vertragsverhältnis sind, dann müssen wir unsere Präventionsmaßnahmen deutlich vor Vertragsende starten. Daraus resultiert, dass wir möglicherweise bereits 6 Monate vor Vertragsende über die Neigung einer Abwanderung Bescheid wissen.
Churn Prediction durch Datasolut. So gehen wir dabei vor.
In der Praxis ist es oft nicht einfach den tatsächlichen Churn in der Vergangenheit festzustellen. Kunden kündigen ständig und Unternehmen machen dann ein gutes Angebot, welches die Kunden kaum ablehnen können. Hier muss sorgfältig geprüft werden, welche Daten zur Verfügung stehen und detailliert analysiert werden, wann eine Kündigung eine Kündigung ist. In diesem Tutorial wurde diese Aufgabe bereits für uns erledigt.
# Churn Verteilung plotten
total = len(df)
plt.figure(figsize=(16,6))
plt.subplot(121)
g = sns.countplot(x='Churn', data=df, )
g.set_title("Churn Distribution \n# 0: No Churn | 1: Churn #", fontsize=22)
# g.set_xlabel("Is Churn?", fontsize=18)
g.set_ylabel('Count', fontsize=18)
for p in g.patches:
height = p.get_height()
g.text(p.get_x()+p.get_width()/2.,
height + 3,
'{:1.2f}%'.format(height/total*100),
ha="center", fontsize=15)
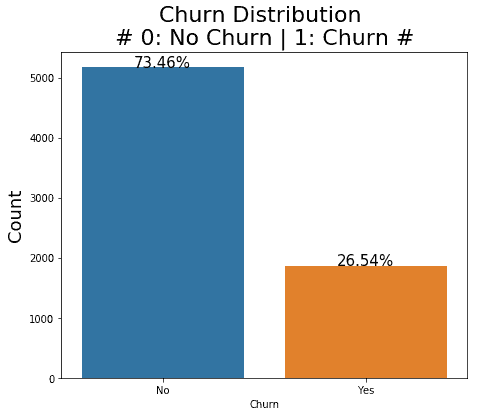
Datenaufbereitung und Machine Learning Feature Engineering
Die Datenaufbereitung. Mit Sicherheit eine der wichtigsten Aufgaben jedes Machine Learning Projekts. Ohne gute Trainingsdaten wird man einfach keinen Erfolg bei der Modellierung haben, auch wenn der Algorithmus noch so gut ist. Dies ist ein Grund, warum die Datenaufbereitung rund 80% der Projektzeit verschlingt. Wir haben bereits über Machine Learning Feature Stores berichtet, die diese Aufgaben standardisieren und somit für deutlich mehr Effizienz sorgen.
Folgend zeigen wir Ihnen wie Sie einige einfache Transformationen, die fast in jedem Projekt benötigt werden, anwenden:
Fehlende Werte
Die fehlenden Werte innerhalb der Daten gilt es zu behandeln. Dafür gibt es unterschiedliche Möglichkeiten (z.B. einsetzen von Mittelwerten). Wir machen es einfach und löschen jeden Datensatz der NULL-Werte hat. Dafür gibt es in Python Pandas eine Funktion „.isnull()“.
# ToralCharges hat Leerzeichen in der Variable, diese müssen wir löschen und mit NULL-Werten ersetzen.
df['TotalCharges'] = df["TotalCharges"].replace(" ",np.nan)
# Wir löschen die Daten mit fehlenden Werten
df = df[df["TotalCharges"].notnull()]
df = df.reset_index()[df.columns]
Kundennummer löschen
ID’s und Schlüsselwerte können wir in diesem Fall nicht gebrauchen und diese müssen daher gelöscht werden. Das geht in Pandas mit folgendem Aufruf:
data.drop(['customerID'], axis=1, inplace=True)
Datentypen ändern
In der Datenexploration haben wir schon gesehen, dass zwei Variablen: „MonthlyCharges“ und „TotalCharges“ als Objekt-Datentypen geladen wurden, wobei diese Nummern sind. Die Variablen vom Typ Object können wir in den Machine Learning Modellen nicht verwenden, daher müssen wir die zwei Variablen in Nummern umwandeln.
# umwandeln ins float
df["TotalCharges"] = df["TotalCharges"].astype(float)
Kategorische Variablen zu numerische Umwandeln
Alles was keine Zahlen sind, können die Algorithmen nicht verarbeiten, daher müssen wir auch die kategorischen Variablen behandeln und zu numerischen Werten transformieren. In dem Tutorial: Telekommunikationsanbieter sind einige Variablen drin, die geändert werden müssen: StreamingTV, StreamingMovies, Gender etc.
# Dummie-Variablen erstellen
telcom = pd.get_dummies(df, df.loc[:, df.dtypes == np.object].columns, drop_first = True )
Diese Funktion wenden wir jetzt auf das komplette Flatfile an und erstellen somit viele Variablen.
Praxis Tipp: „get_dummies()“ erstellt aus jeder Kategorie pro Spalte eine neue Zeile. Wenn Ihr euer Modell erstellt und übertragt es in die Produktion, stellt sicher, dass keine weiteren Spalten hinzukommen, durch Kategorien, die neu erstellt wurden. Dies führt zu Problemen bei der Modellanwendung.
Train- und Test-Daten bilden
Jetzt sind wir kurz davor das Modell zu trainieren. Es fehlt noch die Aufteilung in dem Trainingsdatensatz und dem Testdatensatz. Dazu nutzen wir Fiktionalitäten aus der Bibliothek „Sklearn“, die über Python abrufbar sind.
In diesem Fall teilen wir das Datenset in 80% Training- und 20% Testdatenset auf. In einem echten Projekt wäre da mindestens noch ein 3. Datenset „Validierung“, aber wir halten es hier etwas einfacher.
y = telcom["Churn_Yes"].values
X = telcom.drop(labels = ["Churn_Yes"],axis = 1)
# Create Train & Test Data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Logistische Regression, Modelltraining und Modellqualität
Eine Logistische Regression ist wohl der Algorithmus für den Einstieg in Machine Learning. Heute gibt es deutlich bessere Algorithmen, wie bspw. XGBoost, aber für den Anfang sollte das reichen. In der Praxis würde man vermutlich noch weitere Algorithmen ausprobieren, um zu sehen welcher am besten funktioniert.
Modelltraining
Die Logistische Regression kann für Klassifikationsprobleme, wie unser Churn Case (Churn 1 oder Churn 0), genutzt werden. Unsere abhängige Variable ist Churn (y_train) und die unabhängigen Variablen (X_train) sind alle zu numerischen Werten transformiert: wir können loslegen!
- Importieren des Modells
- Modell initialisieren
- Modell mit den Trainingdaten trainieren
from sklearn.linear_model import LogisticRegression
model_ = LogisticRegression(max_iter=100)
result = model_.fit(X_train, y_train)
Mit dem fertigen Modell können wir jetzt für unser Testset vorhersagen, ob ein Kunde kündigt oder nicht.
Hier nochmal der Hinweis: In einem Projekt würden hier einige Schritt hinzukommen, die ich bewusst für das Tutorial weggelassen habe.
Modellqualität
Die Ergebnisse speichern wir in dem Datenset „prediction_test“, wo wir unsere Modellmetriken messen können (wie gut ist unser Modell).
print (metrics.accuracy_score(y_test, prediction_test))

Diese Zahl zeigt uns, wie genau unser Modell die richtige Klasse vorhersagt. In diesem Fall haben wir eine Genauigkeit von 80,3%, wobei die Genauigkeit sich auf beide Klassen (0 & 1) bezieht. Allein aus der Kennzahl können wir noch nicht wirklich sagen, wie gut unser Modell ist, aber es gibt uns einen ersten Anhaltspunkt.
Praxis Tipp: Wenn der Datensatz in der Zielvariable extrem ungleich verteilt ist, bspw. 3% Churn zu 97% nicht Churn, dann sagt die „Accuracy“ (Genauigkeit) eigentlich nichts über unsere Modellqualität aus, denn das Modell kann auch alle „nicht Churn“ richtig vorhersagen und wir wissen nicht, wie gut es die eigentlichen Kündiger trifft. Hier sollten andere Metriken genutzt werden und zusätzlich fortgeschrittenere Sampling Methoden wie SMOTE.
Modellinterpretation
Mit dem Ziel die Abwanderung der Kunden zu reduzieren, müssen wir rechtzeitig Präventionsmaßnahmen ergreifen. Daher wollen wir etwas genauer wissen, welchen Einfluss die einzelnen Variablen auf unser prognostiziertes Ergebnis haben. Bei einer einfachen Regression können wir uns die Regressionskoeffizienten genauer anschauen.
# Modellgewichte auslesen
weights = pd.Series(model.coef_[0],
index=X.columns.values)
weights.sort_values(ascending = False)
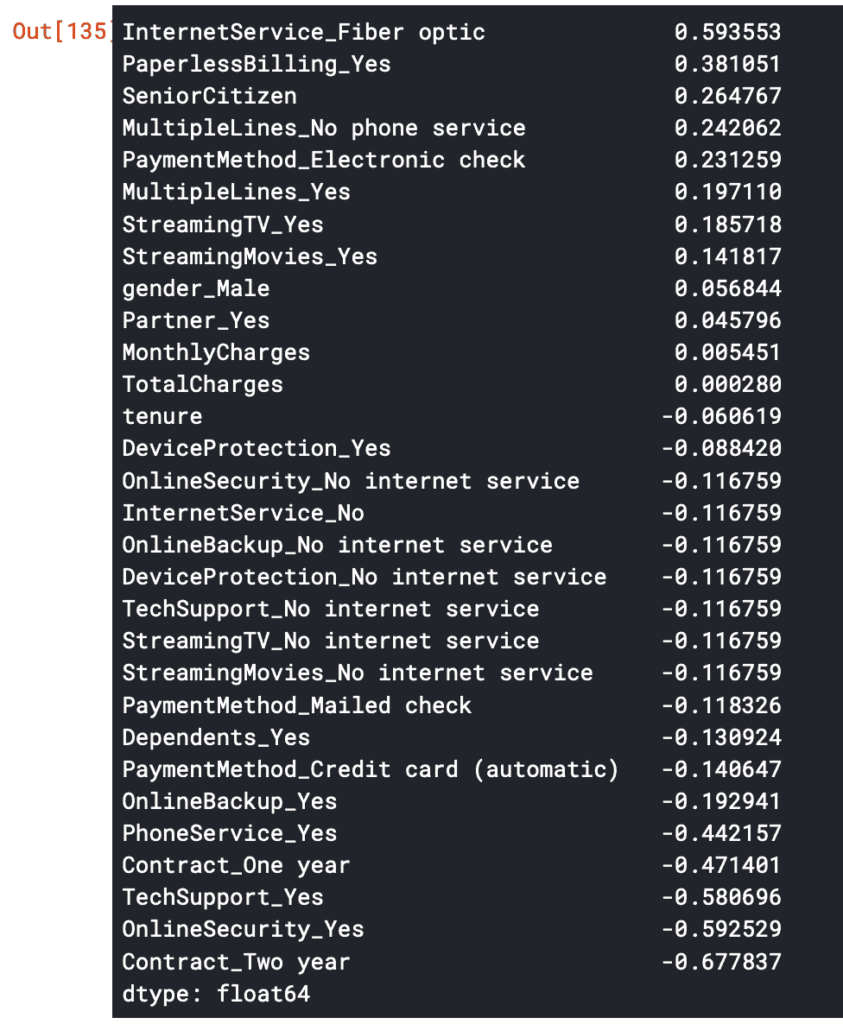
Es ist zu sehen, dass einige Variablen einen positiven Einfluss und andere einen negativen Einfluss auf die Zielvariable haben. Ein positiver Wert in den Koeffizienten hat einen positiven Einfluss auf unsere vorhergesagte Zielvariable.
Die Variable „Fiber_optic“ gibt einen positiven Einfluss an. Das bedeutet, wenn der Wert „Fiber_optic“ hoch ist, ein Vertrag oder Kunde eine höhere Wahrscheinlichkeit besitzt abzuwandern. Instinktiv würde man hier denken: Wieso sollte ein Kunde mit schnellerem Internetanschluss eher gehen? Da wir die Daten nicht selbst zusammengestellt haben, können wir diese Frage nicht beantworten. Hier sollte man in der Praxis tiefer in die Materie einsteigen.
Auf der anderen Seite scheint die Varibale „Contract_Two year“ einen stark negativen Einfluss auf die Churn-Wahrscheinlichkeit zu haben.
Den Churn-Score in der Praxis einsetzen
Wie bekommen wir die Modellergebnisse jetzt in Marketingmaßnahmen abgeleitet, die die Kundenanwanderung reduzieren? Ich würde diese drei Schritte empfehlen:
Teilen Sie die Ergebnisse mit den Fachbereichen
Wir haben mit dem Machine Learning Modell gezeigt, dass wir die Kundenabwanderung mit guten Ergebnissen vorhersagen können und sogar erste Insights über die eigentlichen Gründe bekommen.
- Teilen Sie diese Ergebnisse mit den Fachbereichen, die für die Kundenzufriedenheit zuständig sind: CRM, Online Marketing, Service und weitere.
- Verpacken Sie die Ergebnisse in einer Story, die Sie erzählen können.
- Leiten Sie erste Ideen für Maßnahmen ab.
Planen und testen von Marketingmaßnahmen
Gemeinsam mit den Fachbereichen können Sie jetzt erste Ideen für konkrete Kündiger Präventionsmaßnahmen entwickeln, planen und mit dem Churn-Score testen. Testkampagnen geben schnell Rückmeldung wie gut das Modell in der Praxis am echten Kunden funktioniert. Folgende Fragen, die dabei wichtig sind:
- Welche Kunden werden selektiert?
- Welchen Rabatt kann dem Kunden angeboten werden?
- Gibt es unterschiedliche Kündigungsgründe?
Churn-Score in die Präventionsmaßnahmen einbinden
Ich gehe davon aus, dass Sie eine erfolgreiche Präventionsmaßnahme entwickelt haben: Überführen Sie dies in einen Regelprozess. Hier scheitern Unternehmen häufig, denn das Modell bauen ist sehr einfach, aber die Ergebnisse anschließend auf die Straße zu bringen oft komplex. Fangen Sie einfach an und testen Sie kontinuierlich.
Fazit Churn-Score Beispiel in Python
Die Vorhersage von Kundenabwanderung kann durch ein gutes Machine Learning Modell vohergesagt werden und durch den richtigen Einsatz in Präventionsmaßnahmen, die Kundenabwanderung gesenkt werden. Das oben gezeigte Beispiel wäre in einem echten Kundenprojekt deutlich komplexer und nicht ganz so einfach wie es hier aussieht. Wenn Sie bei der Entwicklung eines Churn-Modells Hilfe brauchen, dann melden Sie sich bei uns!







