Streaming Daten: Einführung und Überblick wichtiger Frameworks

Streaming Daten sind Daten, die mit einem Streaming Framework in „Echtzeit“ verarbeitet werden. Der Unterschied zum reinen Message Processing ist, dass Sie komplexe Operationen (Aggregationen, Joins etc.) auf den Datenströmen anwenden können. Im Big Data Umfeld sind Streaming Daten ein interessantes Entwicklungsfeld, welches sich rapide weiterentwickelt und in vielen Use Cases einen Mehrwert bringt. In […]
Hadoop einfach erklärt!
Apache Hadoop ist eine verteilte Big Data Plattform, die von Google basierend auf dem Map-Reduce Algorithmus entwickelt wurde, um rechenintensive Prozesse bis zu mehreren Petabytes zu erledigen. Hadoop ist eines der ersten Open Source Big Data Systeme, welches entwickelt wurde und gilt als Initiator der Big Data Ära. Das verteilte Big Data Framework ist in […]
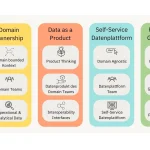
Was ist Big Data? Definition, 4 V’s und Technologie

Big Data ist ein großer Trend in der Unternehmenswelt und schafft für viele Firmen enorme Werte. Durch Big Data lassen sich enorme Datenmengen speichern, verarbeiten und analysieren. Spezielle Technologien ermöglichen die Verarbeitung von Datenmengen, die relationale Datenbanken nicht verarbeiten können. In diesem Artikel gehe ich auf die Grundlagen von Big Data ein. Was ist mit […]
Einführung in Apache Spark: Komponenten, Vorteile und Anwendungsbereiche
Apache Spark ist eine einheitliche In-Memory Analytics Plattform für Big Data Verarbeitung, Data Streaming, SQL, Machine Learning und Graph Verarbeitung. Apache Spark ist das spannendste und innovativste Big Data System was es zurzeit am Big Data Markt gibt. Das von der Apache Foundation seit 2014 als Top-Level-Projekt klassifizierte Open Source Projekt entstand an der University […]
Was ist Delta Lake?
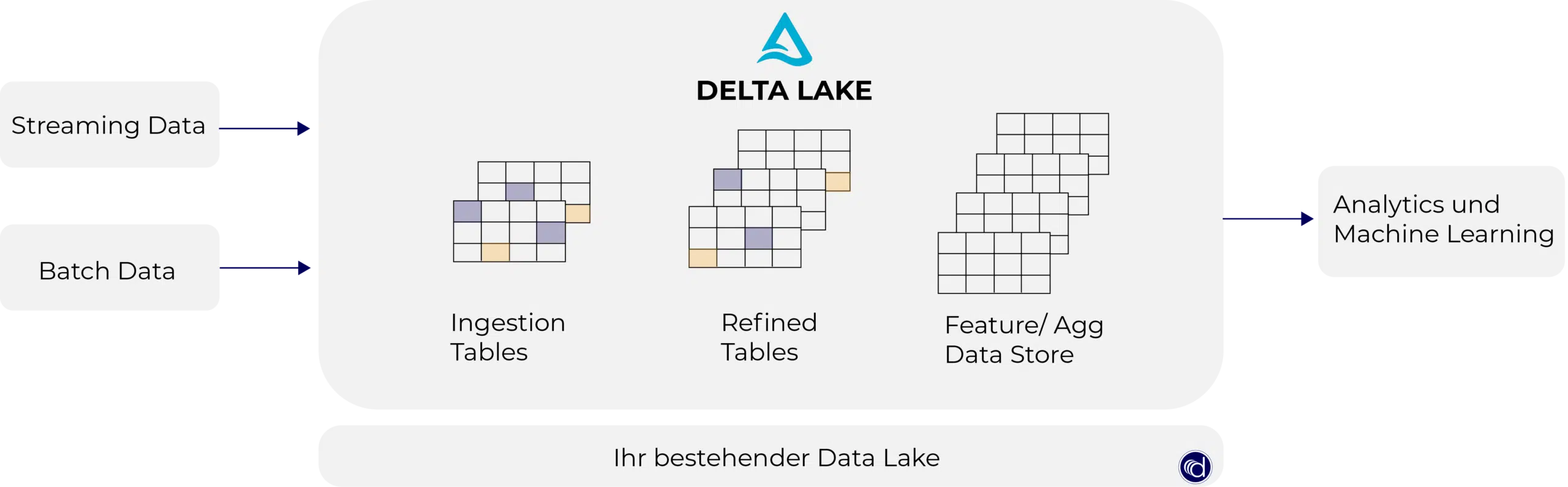
Der Delta Lake ist ein Open-Source-Speicherformat, welches das Parquet-Format um ACID-Funktionalität und weiteren Datenbankfeatures erweitert. Die Zuverlässigkeit, Sicherheit und Leistung des Data Lake wird durch das Delta Lake Format verbessert. Es unterstützt ACID-Transaktionen, skalierbare Metadaten, Zeitreise, Change Data Capture Funktionalitäten für Streaming und Batch-Datenverarbeitung. In diesem Beitrag beschäftigen wir uns damit, was das Delta Lake […]
Snowflake vs. Databricks: Was sind die Unterschiede?
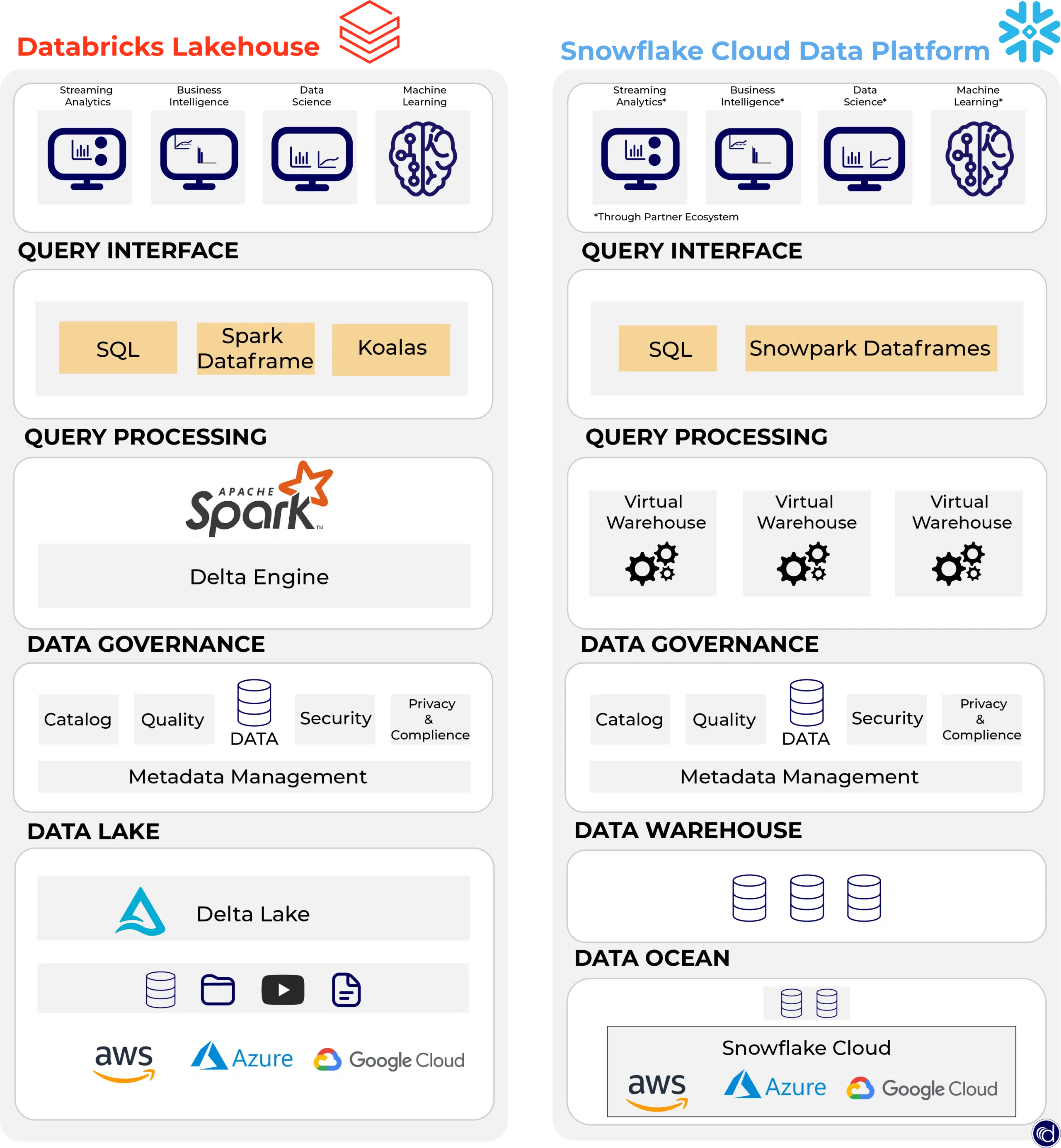
Unternehmen stehen vor der Herausforderung Daten in kürzester Zeit für Analysen wie Machine Learning, Dashboards und Auswertungen vorzubereiten. Data Warehouses und Data Lakes haben sich zwar weiterentwickelt, dennoch benötigt es in der Zukunft eine Lösung, die Daten in großen Massen speichern und verwalten kann. Sowohl Snowflake als auch Databricks bieten eine Lösung, um die Massen […]