


Databricks Auto Loader ist eine optimierte Dateischnittstelle, die automatisch inkrementelle Datenladungen aus Ihrem Cloud-Speicher durchführen kann, um die geladenen Daten dann in Delta Lake Tables abzuspeichern.
Wie genau der Databricks Auto Loader funktioniert erfahren Sie in diesem Artikel.
Was ist der Databricks Auto Loader?
Databricks Auto Loader ist eine Funktion, die es uns ermöglicht, schnell Daten von Azure Storage, AWS S3 oder GCP Storage zu importieren. Sie nutzt Structured Streaming und Checkpoints, um Dateien zu verarbeiten und den Status der Verarbeitung zu tracken, wenn diese in einem bestimmten Verzeichnis erscheinen.
Mit Auto Loader können Sie Milliarden von Dateien verarbeiten, um eine Tabelle zu migrieren oder anzureichern. Dabei ist er skalierbar und unterstützt die Aufnahme von Millionen von Dateien pro Stunde nahezu in Echtzeit. Der Dienst verarbeitet neue Data Files nacheinander und effizient sobald diese in dem Cloud-Speicher ankommen.
Unter anderem lädt Auto Loader folgende Formate:
- AWS S3 (s3://)
- Azure Data Lake Storage Gen2 (ADLS Gen2, abfss://)
- Google Cloud Storage (GCS, gs://)
- Azure Blob Storage (wasbs://)
- ADLS Gen2 (adl://)
- Databricks File System (DBFS, dbfs:/)
Außerdem kann Auto Loader sowohl JSON als auch CSV, PARQUET, AVRO, ORC, TEXT und BINARYFILE Dateiformate übernehmen.
Die Funktion von Databricks bietet eine strukturierte Streaming-Quelle namens CloudFiles. Anhand eines Eingabeverzeichnisses auf dem Cloud-Dateispeicher verarbeitet die CloudFiles-Quelle automatisch neue Dateien, sobald sie ankommen, mit der Option, auch vorhandene Dateien in diesem Verzeichnis zu verarbeiten. Auto Loader unterstützt sowohl Python als auch SQL in Delta Live Tables.
Wieso Auto Loader? Weil herkömmliches Streaming Data allmählich an sein Grenzen kommt. Wir zeigen Ihnen im folgenden Abschnitt wieso.
Was sind die Herausforderungen von Streaming Data?
Streaming Data bringt eine Menge Herausforderungen in der Anwendung mit sich. Die wichtigsten Punkte halten wir für Sie in folgender Tabelle fest:
| Herausforderung | Erklärung |
| Datenvolumen | Die Menge und Geschwindigkeit der Daten müssen bei kontinuierlicher Verarbeitung des Datenstroms berücksichtigt werden. |
| Die Komplexität der Architektur | Systeme zur Verarbeitung von Datenströmen sind häufig verteilt und müssen eine große Anzahl gleichzeitiger Verbindungen und Datenquellen verarbeiten können. |
| Die Dynamik von Datenströmen | Stream-Processing Systeme müssen aufgrund der dynamischen Natur von Datenströmen anpassungsfähig sein, um mit Konzeptabweichungen umzugehen. Nicht jede Datenverarbeitungsmethode ist hier geeignet. |
| Die Abfrageverarbeitung | Das Datenverarbeitungssystem muss in der Lage sein, mehrere stehende Abfragen über eine Gruppe von Eingabedatenströmen zu verarbeiten. Dabei stellen die Speichermenge und der Abfrageprozessor große Herausforderungen dar. |
Sie möchten sich intensiver mit dem Thema Streaming Daten und ihren Herausforderungen beschäftigen? Dann sind Sie bei unserem Artikel zu Streaming Daten genau richtig.
Wie funktioniert der Auto Loader?
Wenn neue Dateien aus den Quellen angeliefert werden, werden ihre Metadaten in einem skalierbaren Key-Value-Speicher (RocksDB) am Kontrollpunkt Ihrer Auto Loader-Pipeline gespeichert.
Dieser Schlüsselwertspeicher stellt sicher, dass die Daten genau einmal verarbeitet werden.
Im Falle von Fehlern kann Auto Loader anhand der im Prüfpunkt gespeicherten Informationen an der Stelle fortfahren, an der er unterbrochen wurde, und beim Schreiben von Daten in Delta Lake weiterhin die exakte einmalige Verarbeitung gewährleisten.
Um Fehlertoleranz oder Exact-once-Semantik zu erreichen, müssen Sie selbst keinen Zustand pflegen oder verwalten.
Wie Auto Loader das gewährleistet?
- Auto Loader speichert Metadaten über gelesene Daten.
- Es verwendet strukturiertes Streaming für eine sofortige Verarbeitung.
- Databricks Auto Loader nutzt Cloud-native Komponenten zur Optimierung der Erkennung ankommender Dateien.
Sehen wir uns nun an, wie Auto Loader aufgebaut ist.
Ihr Team kennt die Konzepte aber nicht den produktiven Alltag auf der Plattform?
Verstehen ist der erste Schritt – Anwenden der zweite.
Was sind die Komponenten des Auto Loaders?
Auto Loader bietet eine strukturierte Streaming-Quelle namens cloudFiles, von der aus Daten in den Delta Lake geladen werden (siehe folgende Grafik). Bei einem Eingabeverzeichnispfad im Cloud-Dateispeicher (Cloud Storage) verarbeitet die cloudFiles-Quelle automatisch neue Dateien, sobald sie ankommen. Zusätzlich bietet Auto Loader die Option auch vorhandene Dateien in diesem Verzeichnis zu verarbeiten. Für die Datenerkennung nutzt Auto Loader zwei Modi, die wir Ihnen im Folgenden vorstellen.

Auto Loader unterstützt zwei Modi der Dateierkennung:
- Den Directory Listing Mode
- Den File Notification Mode
Sehen wir uns nun die beiden Modi genauer an.
Directory Listing Mode (vier Fakten):
- Der Auto Loader findet neue Dateien im Directory Listing Mode (Verzeichnislistenmodus), indem er das Eingabeverzeichnis auflistet. Mit Ausnahme des Zugriffs auf Ihre Daten auf dem Cloud-Speicher ermöglicht Ihnen der Directory Listing Mode ein schnelles Starten von Auto Loader-Streams.
- Auto Loader kann in Databricks Runtime 9.1 und höher automatisch feststellen, ob Dateien in Ihrem Cloud-Speicher mit lexikalischer Ordnung ankommen. Dadurch wird die Anzahl der API-Aufrufe, die zum Auffinden neuer Dateien erforderlich sind, drastisch reduziert.
- Directory Lists ermöglichen es dem Web-Benutzer, die meisten (wenn nicht alle) Dateien in einem Verzeichnis zu sehen, ebenso wie alle untergeordneten Unterverzeichnisse, trotz kleiner Informationslecks.
- Verzeichnislisten bieten einen viel offeneren Zugang als das „geführte“ Durchsuchen einer Sammlung von vorbereiteten Seiten. Selbst ein unbedarfter Webbrowser könnte Zugang zu Dateien erhalten, die der Öffentlichkeit nicht zugänglich gemacht werden sollten. Das hängt von einer Reihe von Variablen ab, u. a. von den Rechten der Dateien und Verzeichnisse sowie von den Einstellungen des Servers für autorisierte Dateien.
File Notification Mode:
In Ihrem Cloud-Infrastrukturkonto werden Dateibenachrichtigungs- und Warteschlangendienste im File Notification Mode (Dateibenachrichtigungsmodus) verwendet. Ein Benachrichtigungsdienst und ein Warteschlangen-Dienst – welche Dateiereignisse aus dem Eingabeverzeichnis abonnieren – können von Auto Loader automatisch eingerichtet werden.
Für große Eingabeverzeichnisse oder ein hohes Dateivolumen ist der Dateibenachrichtigungsmodus (Directory Listing Mode) effizienter und skalierbarer, erfordert aber zusätzliche Cloud-Berechtigungen für die Einrichtung. Für eine bessere Skalierbarkeit und schnellere Leistung (wenn Ihr Verzeichnis wächst) sollten Sie den File Notification Mode nutzen.
Was sind die Vorteile von Auto Loader?
Auto Loader bringt im Vergleich zu Data Streaming viele Vorteile in der Anwendung. Wir sehen uns nun die Top 3 Vorteile von Auto Loader an.
- Keine eigene Buchhaltung: Neue Daten werden Inkrementell verarbeitet, sobald sie im Objektspeicher ankommen. Die Kunden müssen keine Statusinformationen darüber verwalten, welche Dateien angekommen sind.
- Skalierbar: Neu eingetroffene Daten werden vom Auto Loader effizient verfolgt. Das gewährleistet die Nutzung von Cloud-Benachrichtigungs- und Warteschlangendiensten, ohne alle Dateien in einem Verzeichnis auflisten zu müssen. Somit bietet Auto Loader Skalierbarkeit für die Verarbeitung von Millionen von Dateien in einem Verzeichnis.
- Einfach zu benutzen: Auto Loader richtet automatisch die erforderlichen Cloud-Benachrichtigungs- und Warteschlangen-Dienste ein.
Die verwendeten Delta Tabellen (siehe folgende Grafik) im Auto Loader bringen ebenfalls verschiedene Vorteile für die erfolgreiche Datenverarbeitung mit.
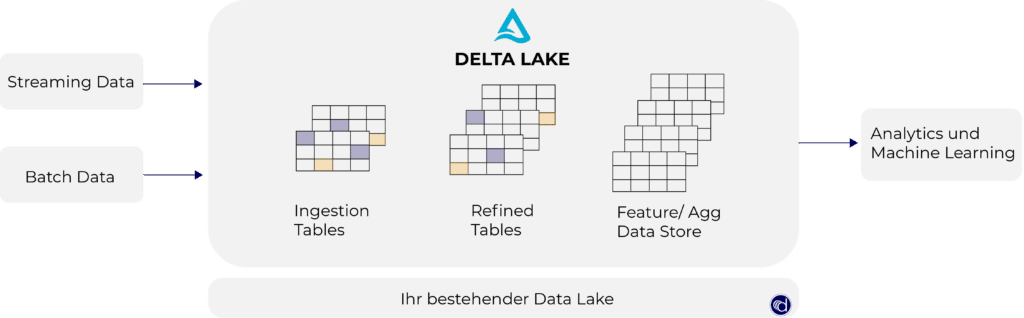
Unter anderem bietet Delta Lake folgende Vorteile:
- ACID-konform.
- Skalierbarer Speicher sowie skalierbare Metadaten.
- Vereinheitlichung von Batch- und Stream-Verarbeitung.
- Zeitreise basierend auf automatischer Versionierung und Zeitstempel.
- Upserts & Deltes mit Merge-Befehlen.
Benötigen Sie Unterstützung?
Wir sind offizieller Databricks Partner und helfen Ihnen bei Herausforderungen rund um das Thema Databricks.
Damit Sie sich die Verwendung von Auto Loader besser vorstellen können, folgt hier eine Auto Loader Beispiel-Syntax.
Wie sieht eine beispiel-Syntax für Auto Loader aus?
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint_path)
.load(file_path)
.select("*", input_file_name().alias("source_file"), current_timestamp().alias("processing_time"))
.writeStream
.option("checkpointLocation", checkpoint_path)
.trigger(availableNow=True)
.toTable(tabelle_name))
Unter dem folgenden Link finden Sie eine Demo zu dem Databricks Notebook: Databricks Notebook
Fazit
Es gibt einige Herausforderungen beim Data Streaming, die Sie beachten sollten. Diese lassen sich mit Auto Loader von Databricks lösen. Auto Loader ermöglicht Skalierbarkeit, ACID-Compliance, eine verbesserte Leistung, ist kosteneffizient und Benutzerfreundlich. Die Auto Loader Konfigurationen lassen sich problemlos konfigurieren und sind je nach Anwendungsfall individuell anpassbar . Es erkennt Änderungen in den Daten (z.B. das Hinzufügen neuer Spalten) und unterstützt Data Ingestion für verschiedene Dateiformate.
Wenn Sie mehr zum Thema Auto Loader erfahren möchten, beraten wir Sie als offizieller Databricks Partner gerne. Kontaktieren Sie uns.
FAQ: Die wichtigsten Fragen schnell beantwortet
Die größte Schwierigkeit bei der Verarbeitung von Data Streaming liegt in der schieren Menge und Geschwindigkeit der Daten, die in Echtzeit verarbeitet werden müssen. Rahmenwerke und Architekturen für die Verarbeitung von Datenströmen müssen einen kontinuierlichen Datenstrom verarbeiten, der sehr umfangreich sein und aus verschiedenen Quellen stammen kann.
Databricks Auto Loader ist eine optimierte Dateiquelle, die automatisch inkrementelle Datenladungen aus Ihrem Cloud-Speicher durchführen kann, sobald diese in den Delta Lake Tables ankommen. Der Auto Loader präsentiert eine neue strukturierte Streaming-Quelle namens cloudFiles.
Auto Loader von Databricks bietet unter anderem folgende Vorteile:
· Skalierbarkeit: Auto Loader verwendet native Cloud-APIs, um Listen der im Speicher vorhandenen Dateien abzurufen.
· Leistung: Auto Loader kann effizient Milliarden von Dateien erkennen.
· Unterstützung für Schema-Inferenz und -Entwicklung: Auto Loader kann Schemaabweichungen erkennen, Sie bei Schemaänderungen benachrichtigen und Daten retten, die sonst ignoriert worden wären oder verloren gegangen wären.
· Kosten: Die Kosten für die Erkennung von Dateien mit Auto Loader skalieren mit der Anzahl der Dateien, die aufgenommen werden.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte










