


Apache Hadoop ist eine verteilte Big Data Plattform, die von Google basierend auf dem Map-Reduce Algorithmus entwickelt wurde, um rechenintensive Prozesse bis zu mehreren Petabytes zu erledigen.
Hadoop ist eines der ersten Open Source Big Data Systeme, welches entwickelt wurde und gilt als Initiator der Big Data Ära. Das verteilte Big Data Framework ist in der Lage sehr große Datenmengen zu speichern und mit hoher Geschwindigkeit zu verarbeiten. Ursprünglich von Google Inc. designed, wurde Apache Hadoop bereits 2008 als Top Level Open Source Projekt der Apache Foundation eingestuft.
Mittlerweile ist Hadoop das bekannteste Big Data Ökosystem und jeder sollte die wichtigsten Eigenschaften kennen.
Was ist Apache Hadoop?
Durch die verteilte Architektur ist die Technologie in der Lage, extrem große Datenmengen in einem Cluster durch Parallelisierung sehr performant zu verarbeiten. Um besser zu verstehen, was ein Hadoop Cluster ist und wie er sich zusammensetzt, werde ich im Folgenden näher auf die Komponenten, das Dateisystem HDFS und die Erweiterungen eingehen.
Hadoop Komponenten
Hadoop besteht aus verschiedenen Komponenten: HDFS, YARN, MapReduce und einigen Erweiterungen, welche man ebenfalls dazuzählen sollte. Die folgende Grafik gibt einen grundsätzlichen Überblick des Systems.
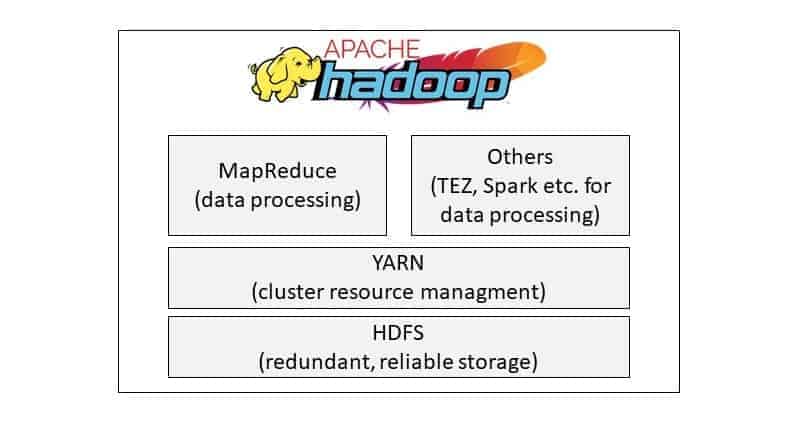
Nun zu den einzelnen Komponenten von Hadoop…
HDFS – Hadoop Distributed File System
Der Kern von Hadoop ist das verteilte Dateisystem Hadoop Distributed File System (HDFS). HDFS ist ein hochverfügbares, verteiltes Dateisystem zur Speicherung sehr großer Datenmengen, das in Server-Clustern organisiert ist. Dabei werden die Daten auf mehreren Rechnern (Knoten) innerhalb eines Clusters gespeichert. Dies geschieht, indem die Dateien in Datenblöcke fester Länge zerlegt und redundant auf die Knoten verteilt werden.
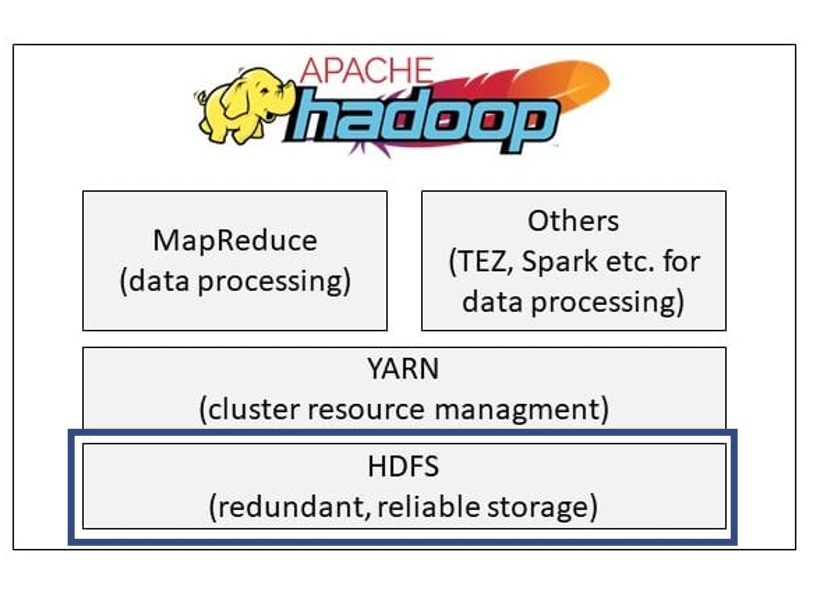
Im Gegensatz zu einer klassischen Datenbank werden einzelne Dateien im Dateisystem abgelegt, die nach bestimmten Kriterien partitioniert und auf dem Dateisystem sichtbar sind.
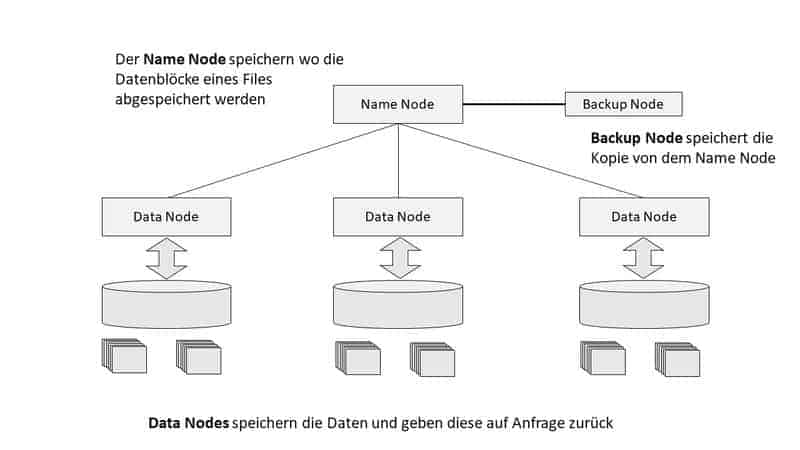
Ein Hadoop System arbeitet in einem Cluster aus Servern, welche aus Master- und Slavenodes bestehen. Der Masternode, der auch NameNode genannt wird, ist für die Verarbeitung aller eingehenden Anfragen zuständig und organisiert die Speicherung von Dateien sowie den dazugehörigen Metadadaten in den einzelnen Datanodes (oder Slave Nodes). HDFS ist auf große Datenmengen ausgelegt und kann daher Dateisysteme bis zu einer Größe von mehreren Millionen Dateien erstellen.
Die Dateiblocklänge als auch der Replikationsgrad sind frei konfigurierbar, was aus meiner Erfahrung einen großen Einfluss auf die Performance von Hadoop hat. Hier gibt es mehr Informationen über Replikation und Dateiblockgröße in Bezug auf Performance.
HDFS Stärken und Schwächen
Folgend gehe ich auf die Stärken und Schwäche von dem HDFS als Filesystem ein.
Stärken
- Sehr große Dateien: Hunderte TB
- Skaliert auf tausende Standard-Server
- Automatische Verteilung und Replikation
- Ausfallsicher: Fehler sind selten
- Schwächen
- Physische Lokationen von Blöcken intransparent
- eingeschränktes Optimierungspotenzial für höhere Dienste (wie Hive etc.)
In der Praxis sehe ich immer weniger HDFS Dateisysteme, da die Cloudinfrastruktur auch in Deutschland zusehends Fahrt aufnimmt. Demnach werden viele Big Data Projekte schon innerhalb Cloud auf intelligenten Speicher Systemen wie AWS S3 oder Azure BlobStore gestartet, da diese oft kosteneffizienter und einfacher zu bedienen sind.
YARN – Yet Another Resource Negotiator
YARN ist der Ressource Manager von Hadoop und ist dafür zuständig die angefragten Ressourcen (CPU, Speicher) eines Hadoop Clusters der verschiedenen Jobs zu verteilen. So lassen sich bestimmte Jobs mehr oder weniger Ressourcen zuordnen, was jeweilig nach Anwendung und Nutzer konfiguriert werden kann.
MapReduce Algorithmus
Hadoop basiert auf dem MapReduce Algorithmus, welcher konfigurierbare Klassen für Map, Reduce und Kombinationsphasen bereitstellt. MapReduce ist leider schon etwas in die Jahre gekommen und gilt in der Szene als veraltet, wodurch es zunehmend durch Directred-Acyclic-Graph (DAG) basierte Engines ersetzt wird. Apache Spark z.B. basiert auch auf einem gerichteten azyklischen Graphen und kann ebenfalls für Abfragen eingesetzt werden.
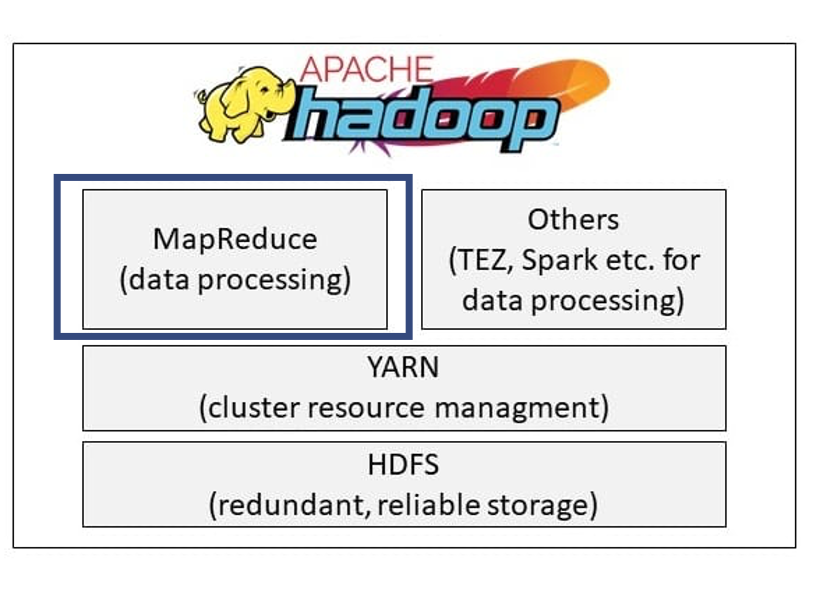
Aus meiner Erfahrung empfehle ich MapReduce nicht mehr einzusetzen und lieber auf neue Ausführungsverfahren (TEZ, Spark) zu wechseln, um nicht auf Performance zu verzichten.
Directed-Acyclic-Graph (DAG)
Ein DAG kommt aus der Graphentheorie und ermöglich die performante Ausführung von komplexen verteilten Algorithmen. Verschiedene Ausführungsverfahren wie Apache Spark oder Apache TEZ machen performante Datenverarbeitung im Hadoop Umfeld möglich.
Dateiformate und Kompression
Hadoop unterstützt verschiedene Dateiformate und ist in der Lage strukturierte, sowie unstrukturierte Formate zu lesen. Einfache Formate wie CSV, JSON oder hochoptimierte strukturierte Formate wie ORC und Parquet sind somit kompatibel. Das schemabasierte Formate Apache Avro ist ebenfalls eine gute Option, um Daten zu strukturieren und nutzbar zu machen.

Künstliche Intelligenz optimiert Marketing und Vertrieb
In 6 Fallstudien erfahren Sie:
- Wie Sie 29% mehr Umsatz pro Kampagne machen.
- Wie Sie durch KI und Automatisierung mehr Zeit gewinnen.
- Wie Sie 300% mehr Conversions zur richtigen Zeit machen.
Hadoop Erweiterungen
Auf Basis von Hadoop wurden viele Erweiterungen entwickelt, die bestimmte Funktionalitäten zu Hadoop hinzufügen oder es ermöglichen einfacher auf das Dateisystem HDFS zuzugreifen. Im Nachfolgenden gebe ich einen kleinen Überblick der wichtigsten Erweiterungen.
Apache Hive
Hive erweitert Hadoop um eine Funktionalität eines DWHs und es werden Abfragen in einer SQL basierenden Sprache auf das Hadoop Filesystem möglich. Mit der HiveQL-Syntax, die nah an der SQL:1999 Standard ist, können Anwender und Programmierer Programme zur Datenverarbeitung (ETL) schreiben und verschieden Skripte ausführen. HiveQL übersetzt den geschriebenen SQL-Code in MapReduce-Jobs oder einen DAG.
Mit Apache Hive sind mittlerweile schon viele Unternehmen vertraut und es hat einen gewissen Standard erreicht. Da viele Entwickler mit SQL sehr vertraut sind, wird Hive gerne in Produktionsumgebungen genutzt.
In Hive werden natürlich viele gängige SQL Standard Operationen wie Joins, Date-Funktionen, Filter, Aggregationsfunktionen sowie Windows-Funktionen zur Verfügung gestellt. Anders als relationale Datenbanken, die Schema-on-Write (SoW) nutzen, arbeitet Hive den Schema-on-Read (SoR) Konzept, welches erst beim Lesen der Daten nach einem gewissen Schema prüft. Dadurch können Datenstrukturen sehr agil sein und unstrukturierte Daten werden unterstützt.
HBase
HBase ist eine spaltenorientierte Datenbankerweiterung für das verteilte Hadoop File System (HDFS). Anders als in relationalen Datenbanken kann man in HBase kein SQL-Code für Abfragen nutzen und es stehen für die Entwicklung von Applikationen Java, Apache Avro, REST oder Thrift zur Verfügung.
In einem HBase System werden Tabellen gehalten, mit Zeilen und Spalten, wie in einer relationalen Datenbank. Jede Tabelle muss einen definierten Primärschlüssel haben, welcher beim Zugriff auf die Daten genutzt werden muss. Ein Vorteil von HBase ist die Möglichkeit „Sparse“ Tabellen anzulegen.
Apache Spark
Spark kann durch das DataSource API ebenfalls auf HDFS zugreifen und als performante Engine für die Datenverarbeitung genutzt werden. So können Sie bspw. mit Spark einen ETL mit Spark durchführen und das fertige Flatfile auf HDFS abspeichern.
Tez
Tez ist eine Open Source Framework, was als performante Ausführungsengine auf Hadoop genutzt werden kann. Genutzt wird dabei ein Directred-Acyclic-Graph (DAG), was als deutlich performantere Ausführungsengine als Hadoop MapReduce gilt. Hier ein Vergleich von der offiziellen Apache TEZ Seite:
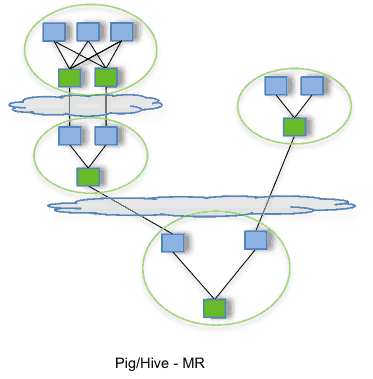
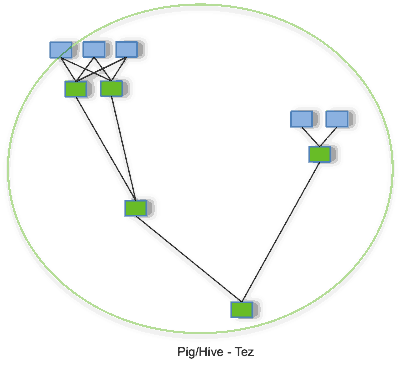
In den Grafiken ist deutlich zu erkennen, dass die Ausführung anhand eines DAGs deutlich optimiert wird. Diese Optimierung führt zu schnelleren Abfragen und allgemein zu mehr Performance auf Hadoop.
Was ist ein Hadoop Cluster?
Ein Hadoop–Cluster ist ein Zusammenschluss von Servern zu einem Computer-Cluster, was die Speicherung und Analyse von enormen Datenmengen ermöglicht. Durch die verteilte Rechenleistung wird besonders rechenintensive Datenverarbeitung möglich.
Was ist MapReduce? MapReduce Algorithmus
MapReduce ist das Herzstück von Apache Hadoop. Das Programmierkonzept erlaubt die massive Skalierung von tausenden von Servern innerhalb eines Hadoop Clusters. Das Konzept ist eigentlich relativ einfach zu verstehen und wie der Name schon sagt, besteht es aus zwei einzelnen Tasks: Map & Reduce.
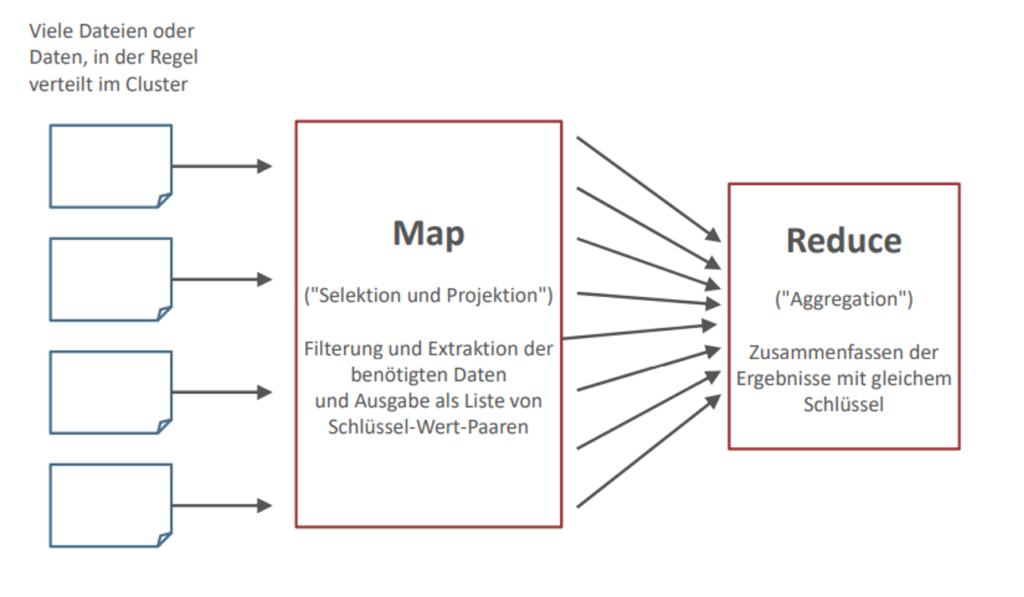
Der erste Prozess ist der Map Job, dieser nimmt ein Set von Daten und konvertiert diese in ein anderes Set von Daten, in welchem die individuellen Elemente der Daten in Tupel (Key/Value Pairs) zusammengefasst werden.
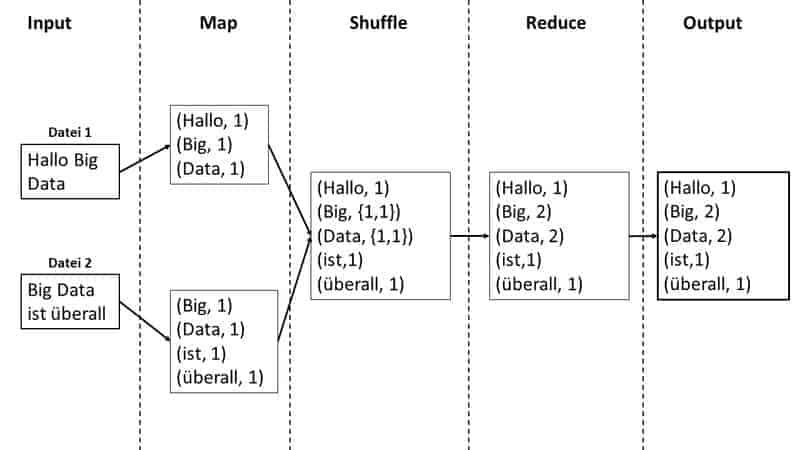
Der Reduce Job nimmt den Output von dem Map Job und kombiniert die gebildeten Tupel in kleinere Menge von Tupel. Ein Reduce Job kommt immer nach dem Map Job. Folgende Grafik zeigt einen MapReduce Job am Beispiel eines Word Counts.
Wo liegt der Unterschied zu einer relationalen Datenbank?
Der Unterschied zwischen einem Hadoop System und einer relationalen Datenbank ist signifikant. Folgend zeige ich euch die größten Unterschiede.
- Hadoop ist im engsten Sinne keine wirkliche Datenbank, sondern mit HDFS ein redundantes und parallelisiertes Dateisystem.
- Relationale Datenbanken basieren auf dem ACID Prinzip: Atomicity, Consistency, Isolation and Durability. Hadoop basiert verfolgt nicht dieses Prinzip d.h. wenn man beispielsweise einen Use Case eines Guthabenaccounts nachbauen möchte, muss man alle möglichen Szenarien nachbauen (Was passiert, wenn Guthaben gebucht wird und ein Fehler tritt auf?).
- Hadoop ermöglicht massive Skalierung der Rechenleistung und Speicherkapazitäten mit relativ kleinen Kosten im Vergleich zu einem RDBMS.
- Parallelisierung von Prozessen und somit die Verarbeitung von sehr großen Datenmengen ist in Hadoop möglich.
- Oft wird gesagt der Hauptunterschied zu RDBMS darin liegt, dass diese nicht in der Lage sind mit unstrukturierten Daten zu arbeiten. Aber eigentlich gibt es doch einige RDBMS, die mit unstrukturierten Daten arbeiten können. Natürlich ist die Performance, wenn die Datenmenge groß wird, irgendwann ein Problem.
- Hive SQL ist immer langsamer als ein SQL-Behelf auf einer realtionalen Datenbank. Jeder der glaubt, Hive sei bei der gleichen (kleineren) Datenmenge schneller, wird oft enttäuscht sein.
- Die Parallelisierung und Skalierung ist Hadoops Stärke, somit ist kaum eine Grenze in der Größe der Daten gesetzt.
Benötigen Sie Unterstützung?
Gerne helfen wir Ihnen bei den ersten Schritten zur eigenen Datenplattform oder begleiten Sie auf Ihrem Weg zur Data Driven Company.
Lasst uns die zwei Systeme Hadoop und RDBMS nochmal im direkten Vergleich angucken:
| Eigenschaft | RDBMS | Hadoop |
| Datenvielfalt | Vornehmlich strukturierte Daten | Strukturierte, Semi-Strukturierte and unstrukturierte daten |
| Datenspeicher | Durchschnittlich eher GBS | Für große Datenmengen im TB und PB-Bereich |
| Abfragen | SQL | HQL (Hive Query Language) |
| Schema | Schema on write (static schema) | Schema on read (dynamic schema) |
| Geschwindigkeit | Liest sehr schnell | Lesen und Schreiben schnell, aber bei geringeren Datenmengen ist die RDBMS schneller |
| Kosten | meistens Lizenz | Kostenlos |
| Use Case | OLTP (Online transaction processing) | Analytics (Audio, video, logs etc), Data Discovery |
| Datenobjekte | Relationale Tabellen | Key/Value Pair |
| Durchsatz | Gering | Hoch |
| Skalierbarkeit | Vertikial (Scale Up) | Horizontal (Scale Out) |
| Hardware | High-End Server | Commodity/Utility Hardware |
| Integrität | Hoch (ACID) | Gering |
Was ist der Unterschied zwischen MapReduce und Apache Spark?
Oft wird mir die Frage gestellt: Wie unterscheidet sich Spark vs. Apache Hadoop?
In diesem Artikel gebe ich einen grundsätzlichen Überblick über Apache Spark und warum Spark viele Vorteile gegenüber Hadoop hat.
Beide basieren auf dem Konzept der Verteilung von Daten und Arbeitsschritten in einem Cluster, aber unterscheiden sich grundsätzlich in der Architektur und Möglichkeiten der Datenverarbeitung:
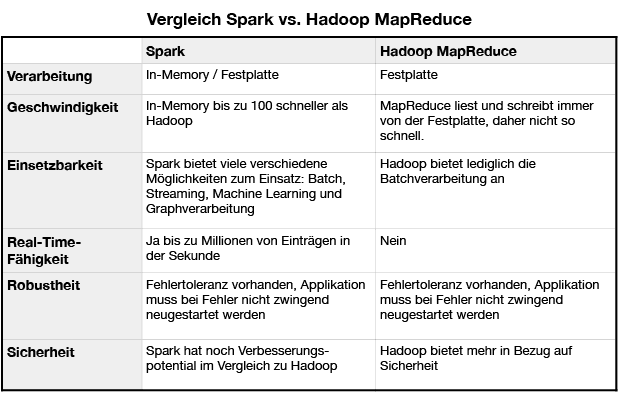
Der Vergleich zeigt, dass Spark in der Verarbeitung von Daten viele Vorteile hat, dennoch kommt HDFS für die langfristige Speicherung von großen Datenmengen öfter zu Einsatz. Durch den Vormarsch der Cloudtechnologie von Amazon und Microsoft wird das HDFS langsam abgelöst und durch intelligente Dienste wie Amazon S3 ersetzt.
Vor- und Nachteile von Hadoop
Folgend habe ich die Vor- und Nachteile von Hadoop zusammengefasst.
Vorteile von Hadoop
- Verteilte Speicherung (HDFS)
- Verteile Verarbeitung (MapReduce)
- Fehlerrobustheit
- Open Source
- Großes Ökosystem
Nachteile von Hadoop
- Hohe Latenz bei Abfragen
- Komplexe API
- Machine Learning kaum möglich
- Kein Streaming
Zusammenfassung
Hadoop ist eines der weitverbreitetsten Big Data Plattformen und mit dem starken Dateisystem HDFS ein oft eingesetztes Dateisystem im Big Data Umfeld. Die vielen Erweiterungen von Hadoop, geben einem viele Möglichkeiten HDFS für verschiedenste Prozesse und Datenverarbeitungen einzusetzen.
Wenn Hadoop HDFS zum Einsatz kommt, sollten Sie sich gut überlegen welche Abfragealgorithmen Sie einsetzen sollten. Denn MapReduce ist in die Jahre gekommen und hat einige Nachteile in Bezug auf Performance. Hier gibt es zum Beispiel TEZ oder Spark, die Sie einsetzen können. Beide werden nach einem DAG optimiert und somit sind diese MapReduce überlegen.
Auch HDFS wir heute schon häufig durch andere Objekt Stores wie AWS S3 oder Microsoft Blob Storage ersetzt, diese haben den Vorteil, dass sie kaum gewartet werden müssen.

Lassen Sie uns sprechen und Ihr Potenzial entdecken.
Ob und wie künstliche Intelligenz Ihnen weiterhelfen kann, können Sie in einem ersten, unverbindlichen Gespräch mit uns herausfinden.
In diesem Gespräch erfahren Sie:
- Wie Ihr Use-Case technisch am besten umgesetzt werden kann
- Wie wir maximal sicher mit Ihren Kundendaten umgehen
- Wie lange wir für die Umsetzung benötigen und wie ein konkreter Projektplan aussehen könnte







